 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Elimination of Non-Novel Segments at Multi-Scale for Few-Shot Segmentation
Nov 04, 2022
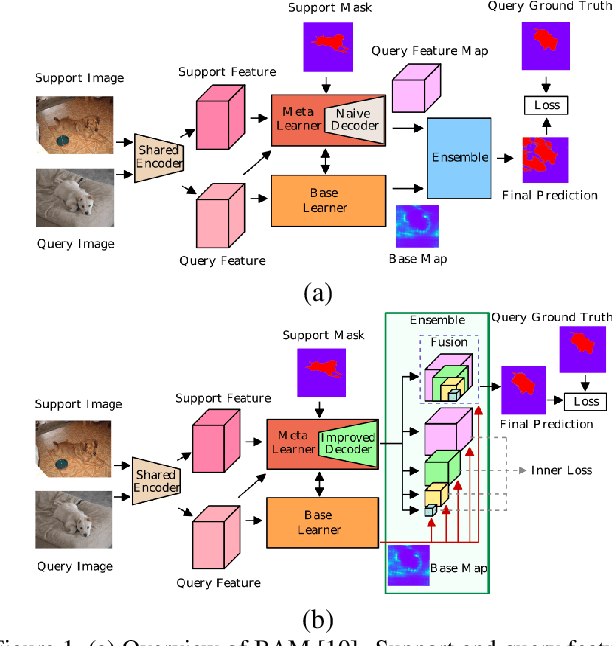
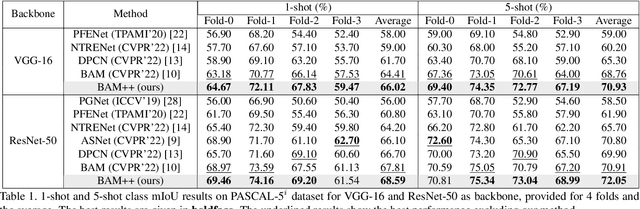
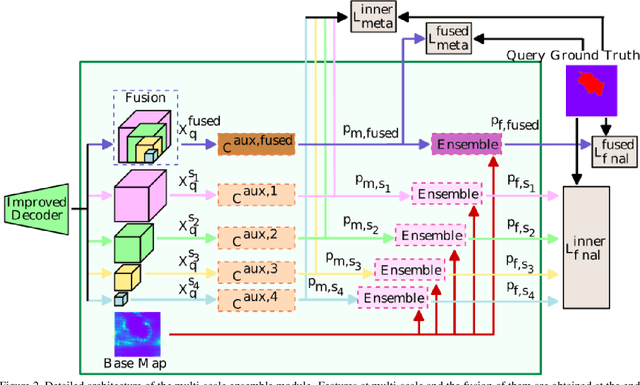

Few-shot segmentation aims to devise a generalizing model that segments query images from unseen classes during training with the guidance of a few support images whose class tally with the class of the query. There exist two domain-specific problems mentioned in the previous works, namely spatial inconsistency and bias towards seen classes. Taking the former problem into account, our method compares the support feature map with the query feature map at multi scales to become scale-agnostic. As a solution to the latter problem, a supervised model, called as base learner, is trained on available classes to accurately identify pixels belonging to seen classes. Hence, subsequent meta learner has a chance to discard areas belonging to seen classes with the help of an ensemble learning model that coordinates meta learner with the base learner. We simultaneously address these two vital problems for the first time and achieve state-of-the-art performances on both PASCAL-5i and COCO-20i datasets.
Reducing Two-Way Ranging Variance by Signal-Timing Optimization
Nov 01, 2022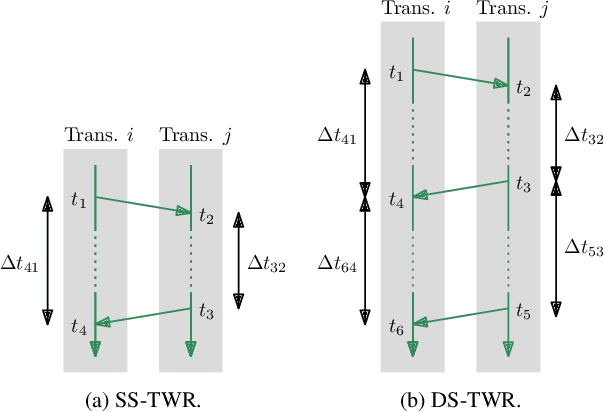
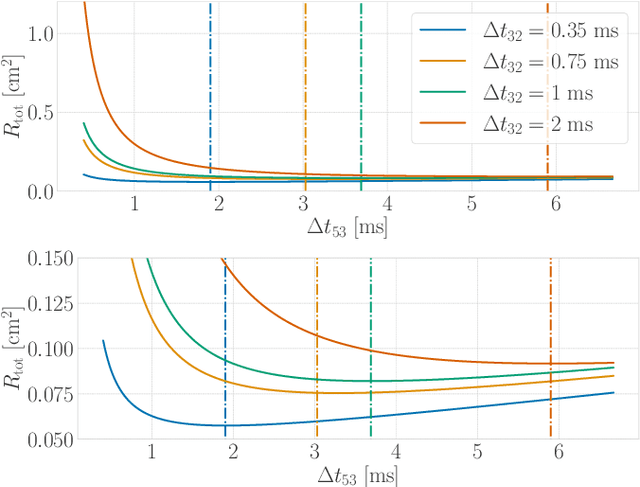

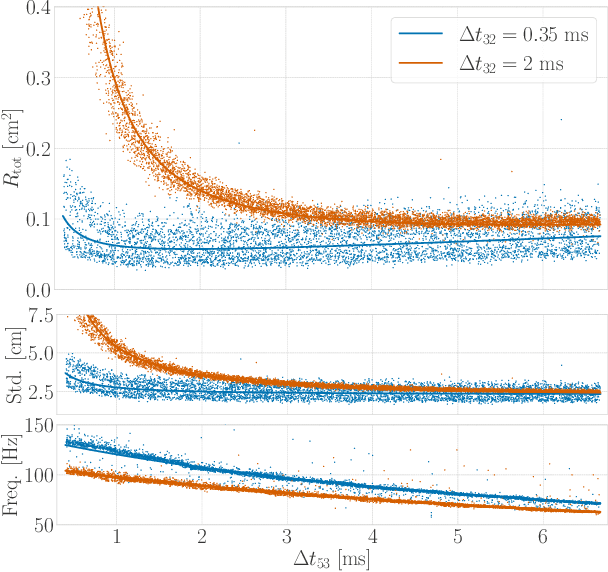
Time-of-flight-based range measurements among transceivers with different clocks requires ranging protocols that accommodate for the varying rates of the clocks. Double-sided two-way ranging (DS-TWR) has recently been widely adopted as a standard protocol due to its accuracy; however, the precision of DS-TWR has not been clearly addressed. In this paper, an analytical model of the variance of DS-TWR is derived as a function of the user-programmed response delays. Consequently, this allows formulating an optimization problem over the response delays in order to maximize the information gained from range measurements by addressing the effect of varying the response delays on the precision and frequency of the measurements. The derived analytical variance model and proposed optimization formulation are validated experimentally with 2 ranging UWB transceivers, where 29 million range measurements are collected.
A Fast and Accurate Pitch Estimation Algorithm Based on the Pseudo Wigner-Ville Distribution
Oct 27, 2022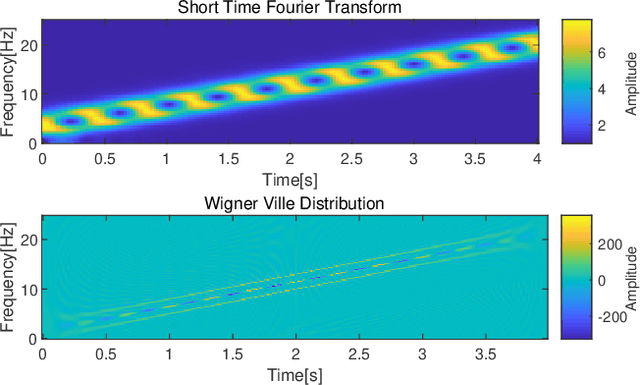
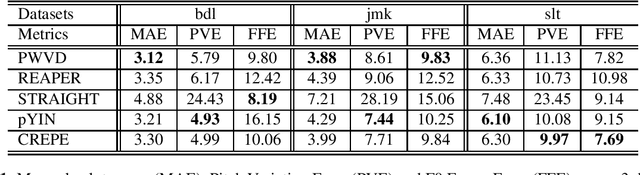
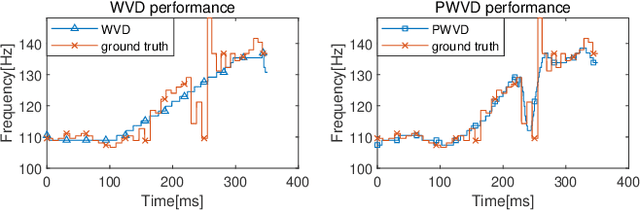
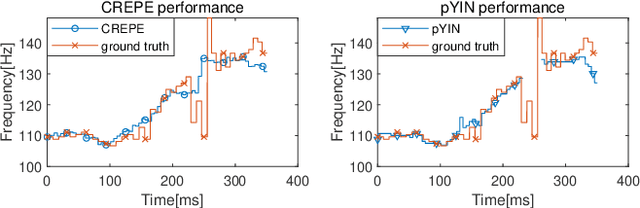
Estimation of fundamental frequency (F0) in voiced segments of speech signals, also known as pitch tracking, plays a crucial role in pitch synchronous speech analysis, speech synthesis, and speech manipulation. In this paper, we capitalize on the high time and frequency resolution of the pseudo Wigner-Ville distribution (PWVD) and propose a new PWVD-based pitch estimation method. We devise an efficient algorithm to compute PWVD faster and use cepstrum-based pre-filtering to avoid cross-term interference. Evaluating our approach on a database with speech and electroglottograph (EGG) recordings yields a state-of-the-art mean absolute error (MAE) of around 4Hz. Our approach is also effective at voiced/unvoiced classification and handling sudden frequency changes.
Combination of Time-domain, Frequency-domain, and Cepstral-domain Acoustic Features for Speech Commands Classification
Mar 30, 2022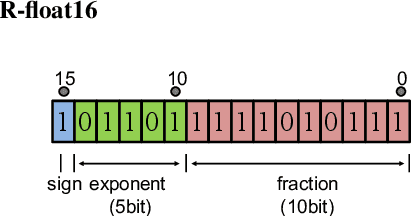
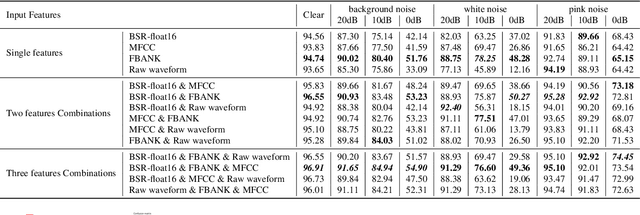
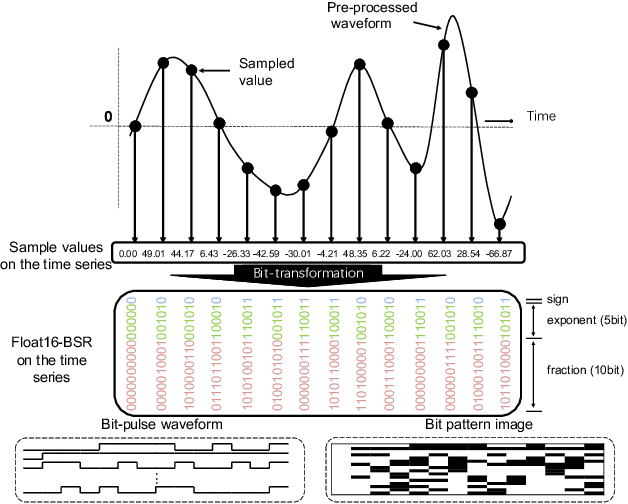
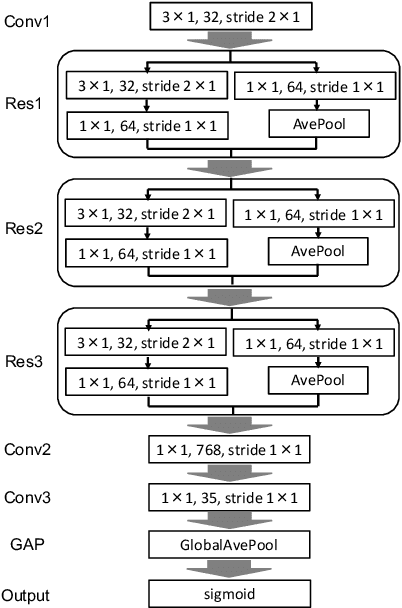
In speech-related classification tasks, frequency-domain acoustic features such as logarithmic Mel-filter bank coefficients (FBANK) and cepstral-domain acoustic features such as Mel-frequency cepstral coefficients (MFCC) are often used. However, time-domain features perform more effectively in some sound classification tasks which contain non-vocal or weakly speech-related sounds. We previously proposed a feature called bit sequence representation (BSR), which is a time-domain binary acoustic feature based on the raw waveform. Compared with MFCC, BSR performed better in environmental sound detection and showed comparable accuracy performance in limited-vocabulary speech recognition tasks. In this paper, we propose a novel improvement BSR feature called BSR-float16 to represent floating-point values more precisely. We experimentally demonstrated the complementarity among time-domain, frequency-domain, and cepstral-domain features using a dataset called Speech Commands proposed by Google. Therefore, we used a simple back-end score fusion method to improve the final classification accuracy. The fusion results also showed better noise robustness.
Exact Formulas for Finite-Time Estimation Errors of Decentralized Temporal Difference Learning with Linear Function Approximation
Apr 20, 2022In this paper, we consider the policy evaluation problem in multi-agent reinforcement learning (MARL) and derive exact closed-form formulas for the finite-time mean-squared estimation errors of decentralized temporal difference (TD) learning with linear function approximation. Our analysis hinges upon the fact that the decentralized TD learning method can be viewed as a Markov jump linear system (MJLS). Then standard MJLS theory can be applied to quantify the mean and covariance matrix of the estimation error of the decentralized TD method at every time step. Various implications of our exact formulas on the algorithm performance are also discussed. An interesting finding is that under a necessary and sufficient stability condition, the mean-squared TD estimation error will converge to an exact limit at a specific exponential rate.
Optimal Fractional Fourier Filtering in Time-vertex Graphs signal processing
Jan 12, 2022
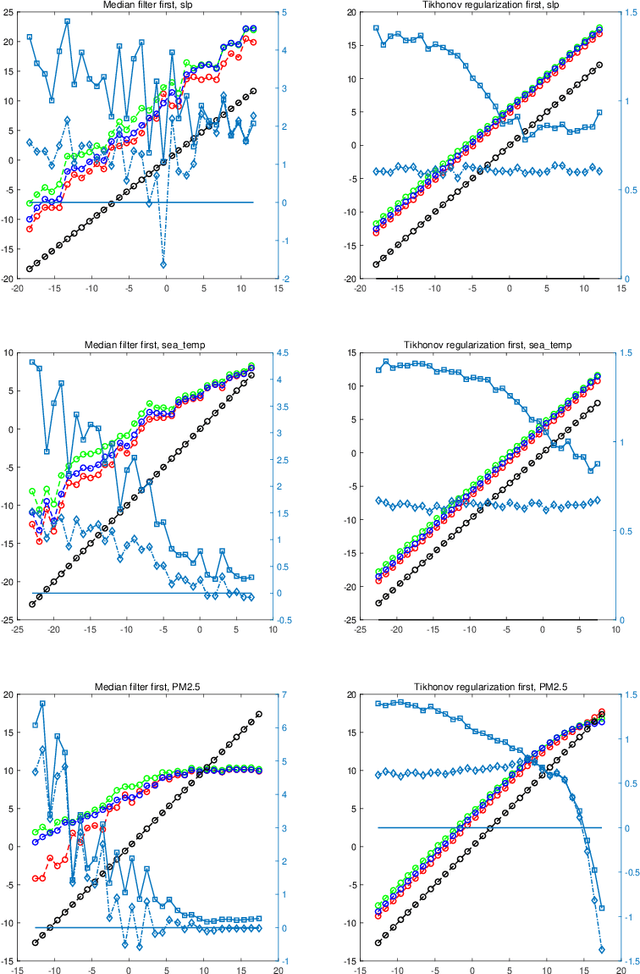
Graph signal processing (GSP) is an effective tool in dealing with data residing in irregular domains. In GSP, the optimal graph filter is one of the essential techniques, owing to its ability to recover the original signal from the distorted and noisy version. However, most current research focuses on static graph signals and ordinary space/time or frequency domains. The time-varying graph signals have a strong ability to capture the features of real-world data, and fractional domains can provide a more suitable space to separate the signal and noise. In this paper, the optimal time-vertex graph filter and its Wiener-Hopf equation are developed, using the product graph framework. Furthermore, the optimal time-vertex graph filter in fractional domains is also developed, using the graph fractional Laplacian operator and graph fractional Fourier transform. Numerical simulations on real-world datasets will demonstrate the superiority of the optimal time-vertex graph filter in fractional domains over the optimal time-vertex graph filter in ordinary domains and the optimal static graph filter in fractional domains.
A Location-Based Global Authorization Method for Underwater Security
Oct 14, 2022
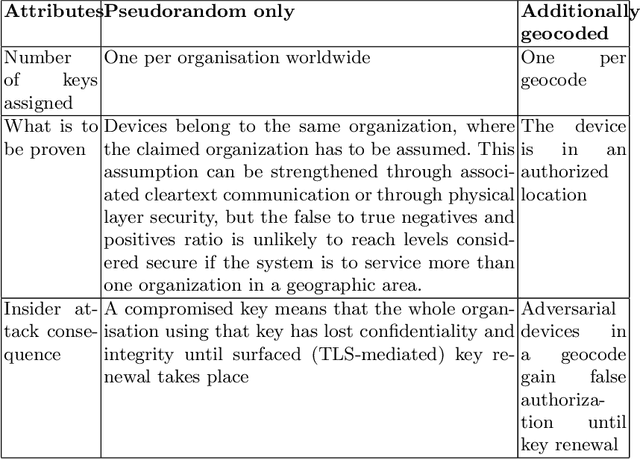


National or international maritime authorities are used to handle requests for licenses for all kinds of marine activities. These licenses constitute authorizations limited in time and space, but there is no technical security service to check for the authorization of a wide range of marine assets. We have noted secure AIS solutions suitable for more or less constantly internet-connected assets such as ships with satellite connections. The additional constraints posed by underwater autonomous assets, namely less power and connectivity, can be mitigated by using symmetric cryptography. We propose a security service that allows the automatized check of asset authorization status based on large symmetric keys. Key generation can take place at a central authority according to the time and space limitations of a license, i.e. timestamped and geocoded. Our solution harnesses the exceptionally large key size of the RC5 cipher and the standardized encoding of geocells in the Open Location Code system. While we developed and described our solution for offshore underwater use, aerial and terrestrial environments could also make use of it if they are similarly bandwidth constrained or want to rely on quantum-resistant and computationally economic symmetric methods.
Performance of Deep Learning models with transfer learning for multiple-step-ahead forecasts in monthly time series
Mar 18, 2022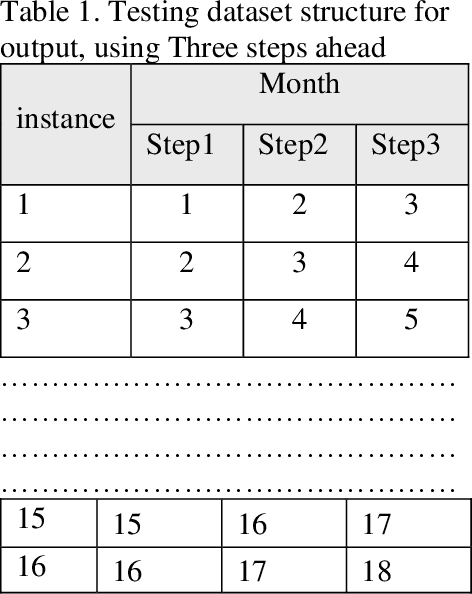
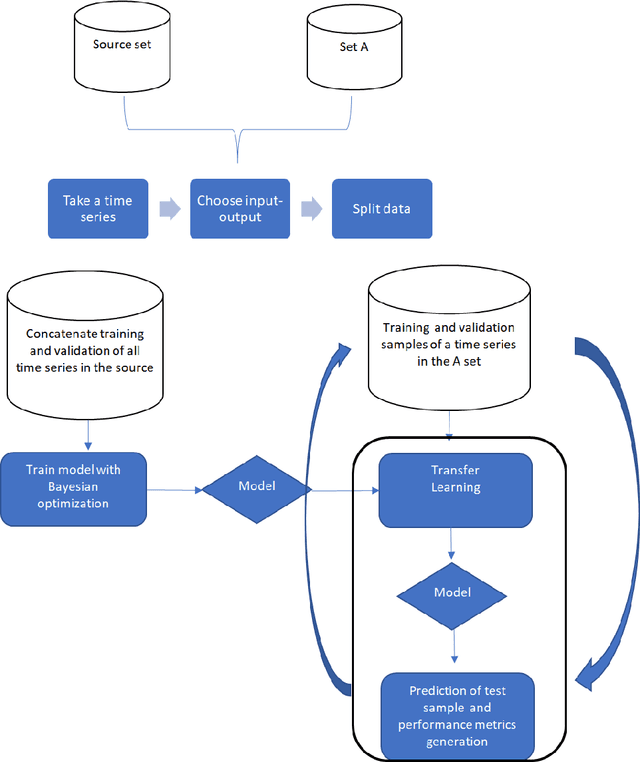

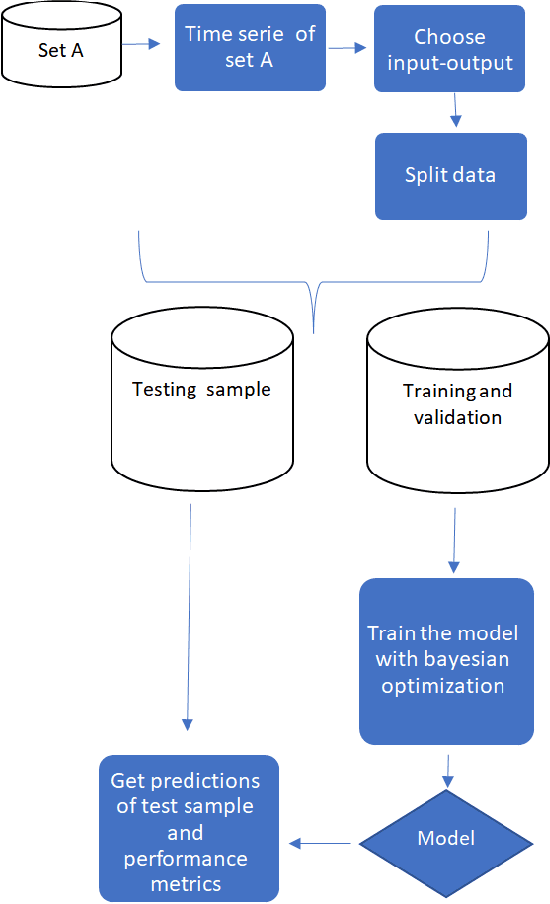
Deep Learning and transfer learning models are being used to generate time series forecasts; however, there is scarce evidence about their performance prediction that it is more evident for monthly time series. The purpose of this paper is to compare Deep Learning models with transfer learning and without transfer learning and other traditional methods used for monthly forecasts to answer three questions about the suitability of Deep Learning and Transfer Learning to generate predictions of time series. Time series of M4 and M3 competitions were used for the experiments. The results suggest that deep learning models based on TCN, LSTM, and CNN with transfer learning tend to surpass the performance prediction of other traditional methods. On the other hand, TCN and LSTM, trained directly on the target time series, got similar or better performance than traditional methods for some forecast horizons.
Moment Estimation for Nonparametric Mixture Models Through Implicit Tensor Decomposition
Oct 25, 2022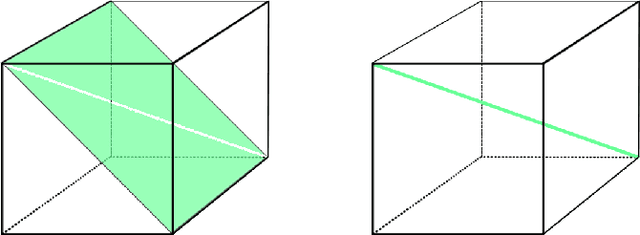
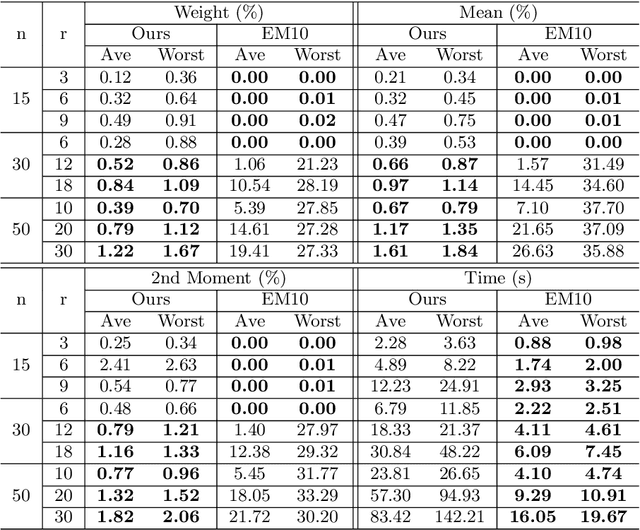
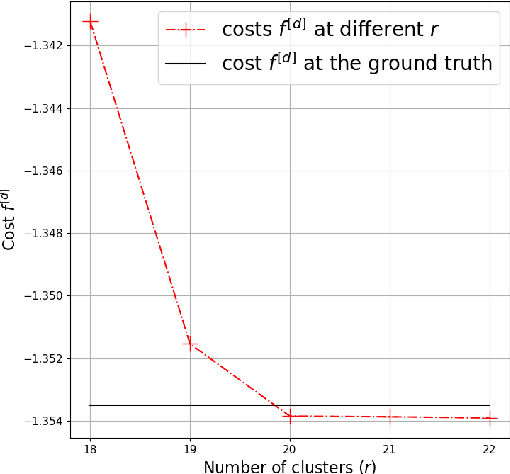
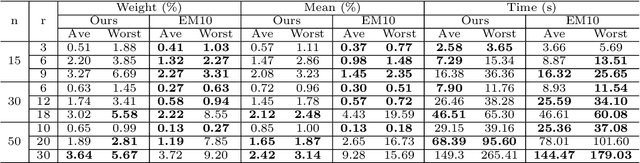
We present an alternating least squares type numerical optimization scheme to estimate conditionally-independent mixture models in $\mathbb{R}^n$, with minimal additional distributional assumptions. Following the method of moments, we tackle a coupled system of low-rank tensor decomposition problems. The steep costs associated with high-dimensional tensors are avoided, through the development of specialized tensor-free operations. Numerical experiments illustrate the performance of the algorithm and its applicability to various models and applications. In many cases the results exhibit improved reliability over the expectation-maximization algorithm, with similar time and storage costs. We also provide some supporting theory, establishing identifiability and local linear convergence.
RangeSeg: Range-Aware Real Time Segmentation of 3D LiDAR Point Clouds
May 02, 2022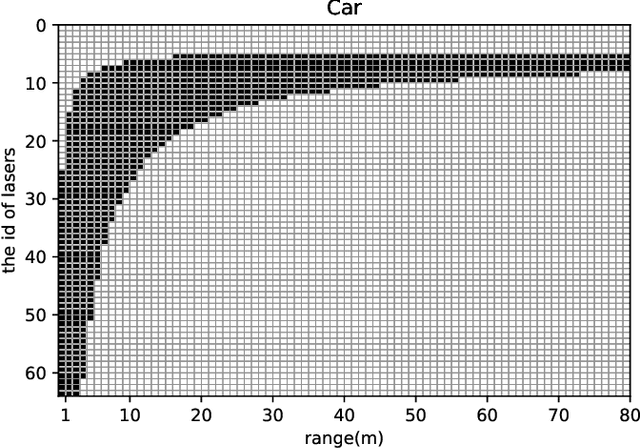
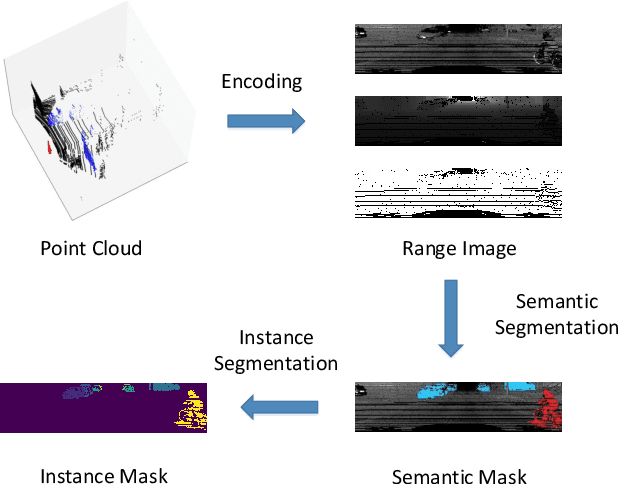
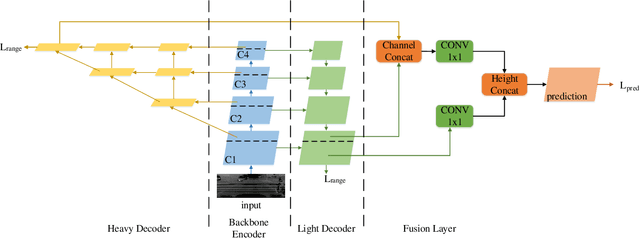
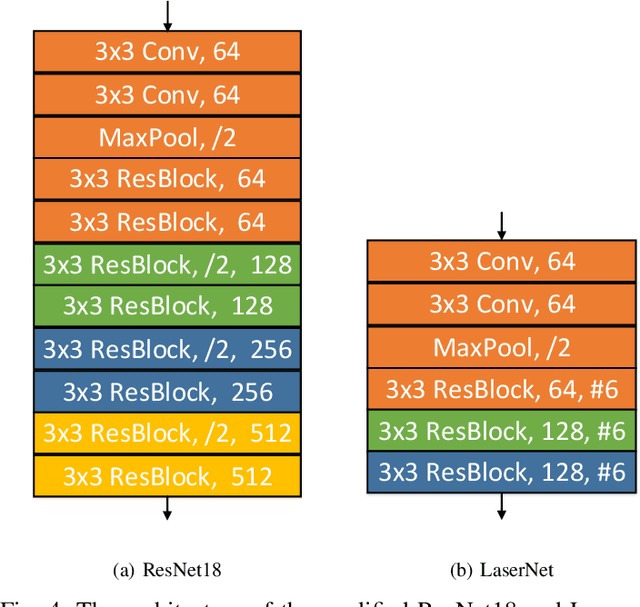
Semantic outdoor scene understanding based on 3D LiDAR point clouds is a challenging task for autonomous driving due to the sparse and irregular data structure. This paper takes advantages of the uneven range distribution of different LiDAR laser beams to propose a range aware instance segmentation network, RangeSeg. RangeSeg uses a shared encoder backbone with two range dependent decoders. A heavy decoder only computes top of a range image where the far and small objects locate to improve small object detection accuracy, and a light decoder computes whole range image for low computational cost. The results are further clustered by the DBSCAN method with a resolution weighted distance function to get instance-level segmentation results. Experiments on the KITTI dataset show that RangeSeg outperforms the state-of-the-art semantic segmentation methods with enormous speedup and improves the instance-level segmentation performance on small and far objects. The whole RangeSeg pipeline meets the real time requirement on NVIDIA\textsuperscript{\textregistered} JETSON AGX Xavier with 19 frames per second in average.