 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sketching sparse low-rank matrices with near-optimal sample- and time-complexity
May 12, 2022
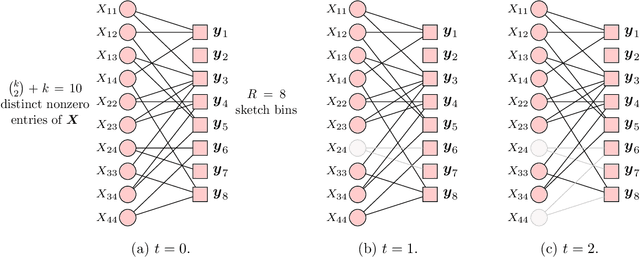
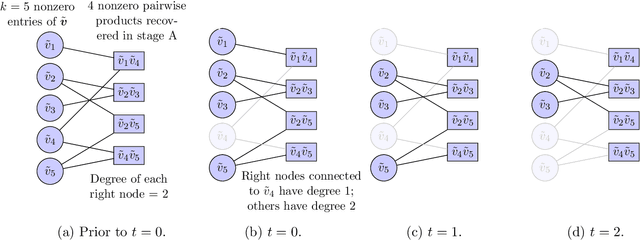
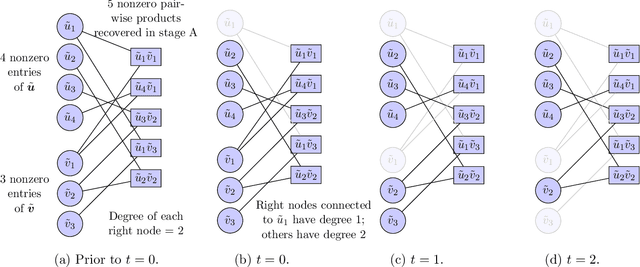
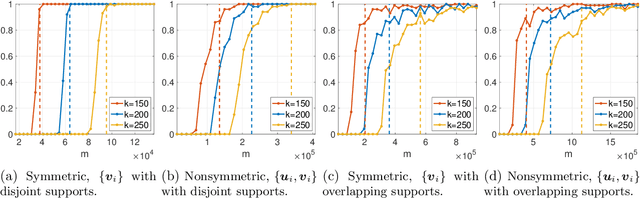
We consider the problem of recovering an $n_1 \times n_2$ low-rank matrix with $k$-sparse singular vectors from a small number of linear measurements (sketch). We propose a sketching scheme and an algorithm that can recover the singular vectors with high probability, with a sample complexity and running time that both depend only on $k$ and not on the ambient dimensions $n_1$ and $n_2$. Our sketching operator, based on a scheme for compressed sensing by Li et al. and Bakshi et al., uses a combination of a sparse parity check matrix and a partial DFT matrix. Our main contribution is the design and analysis of a two-stage iterative algorithm which recovers the singular vectors by exploiting the simultaneously sparse and low-rank structure of the matrix. We derive a nonasymptotic bound on the probability of exact recovery. We also show how the scheme can be adapted to tackle matrices that are approximately sparse and low-rank. The theoretical results are validated by numerical simulations.
DisentQA: Disentangling Parametric and Contextual Knowledge with Counterfactual Question Answering
Nov 10, 2022
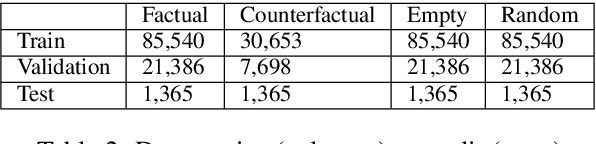
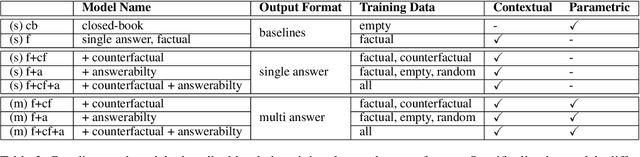
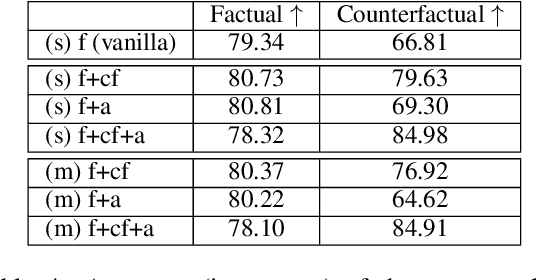
Question answering models commonly have access to two sources of "knowledge" during inference time: (1) parametric knowledge - the factual knowledge encoded in the model weights, and (2) contextual knowledge - external knowledge (e.g., a Wikipedia passage) given to the model to generate a grounded answer. Having these two sources of knowledge entangled together is a core issue for generative QA models as it is unclear whether the answer stems from the given non-parametric knowledge or not. This unclarity has implications on issues of trust, interpretability and factuality. In this work, we propose a new paradigm in which QA models are trained to disentangle the two sources of knowledge. Using counterfactual data augmentation, we introduce a model that predicts two answers for a given question: one based on given contextual knowledge and one based on parametric knowledge. Our experiments on the Natural Questions dataset show that this approach improves the performance of QA models by making them more robust to knowledge conflicts between the two knowledge sources, while generating useful disentangled answers.
SETGen: Scalable and Efficient Template Generation Framework for Groupwise Medical Image Registration
Nov 10, 2022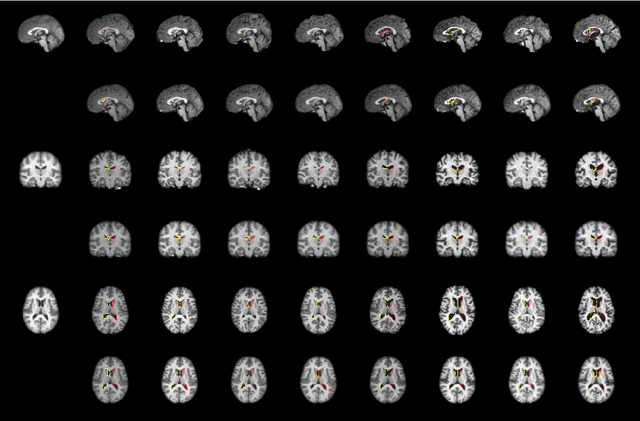
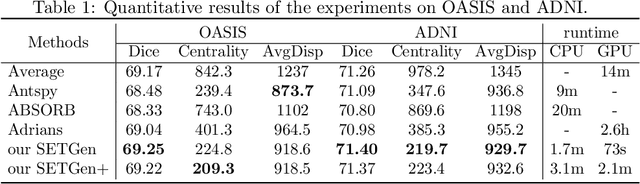
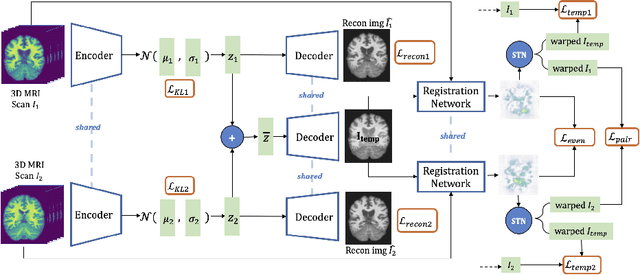
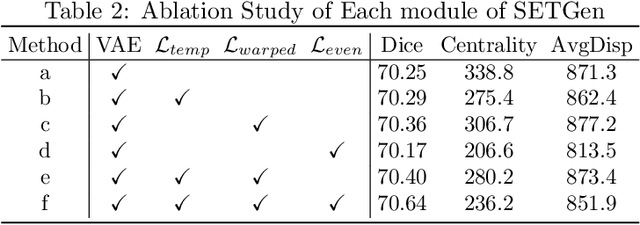
Template generation is a crucial step of groupwise image registration which deforms a group of subjects into a common space. Existing traditional and deep learning-based methods can generate high-quality template images. However, they suffer from substantial time costs or limited application scenarios like fixed group size. In this paper, we propose an efficient groupwise template generative framework based on variational autoencoder models utilizing the arithmetic property of latent representation of input images. We acquire the latent vectors of each input and use the average vector to construct the template through the decoder. Therefore, the method can be applied to groups of any scale. Secondly, we explore a siamese training scheme that feeds two images to the shared-weight twin networks and compares the distances between inputs and the generated template to prompt the template to be close to the implicit center. We conduct experiments on 3D brain MRI scans of groups of different sizes. Results show that our framework can achieve comparable and even better performance to baselines, with runtime decreased to seconds.
Optimizing the Age of Information in Mixed-Critical Wireless Communication Networks
Nov 10, 2022
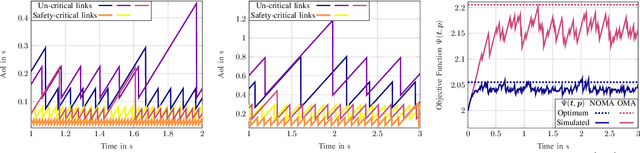
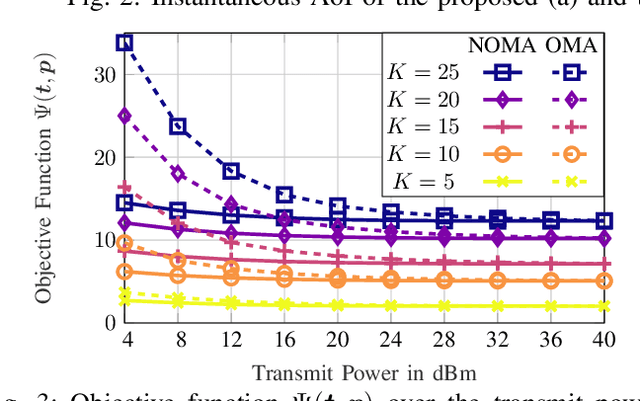
Beyond fifth generation wireless communication networks (B5G) are applied in many use-cases, such as industrial control systems, smart public transport, and power grids. Those applications require innovative techniques for timely transmission and increased wireless network capacities. Hence, this paper proposes optimizing the data freshness measured by the age of information (AoI) in dense internet of things (IoT) sensor-actuator networks. Given different priorities of data-streams, i.e., different sensitivities to outdated information, mixed-criticality is introduced by analyzing different functions of the age, i.e., we consider linear and exponential aging functions. An intricate non-convex optimization problem managing the physical transmission time and packet outage probability is derived. Such problem is tackled using stochastic reformulations, successive convex approximations, and fractional programming, resulting in an efficient iterative algorithm for AoI optimization. Simulation results validate the proposed scheme's performance in terms of AoI, mixed-criticality, and scalability. The proposed non-orthogonal transmission is shown to outperform an orthogonal access scheme in various deployment cases. Results emphasize the potential gains for dense B5G empowered IoT networks in minimizing the AoI.
Coordinating CAV Swarms at Intersections with a Deep Learning Model
Nov 10, 2022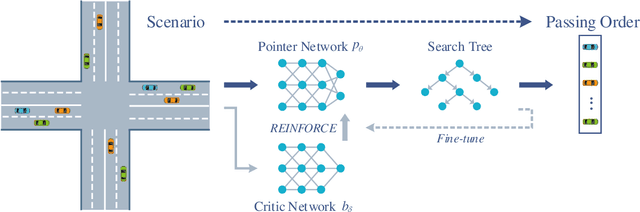
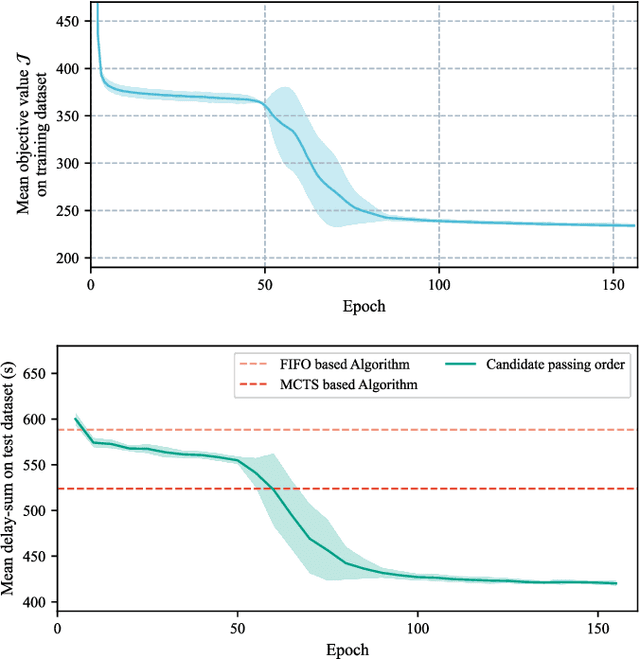
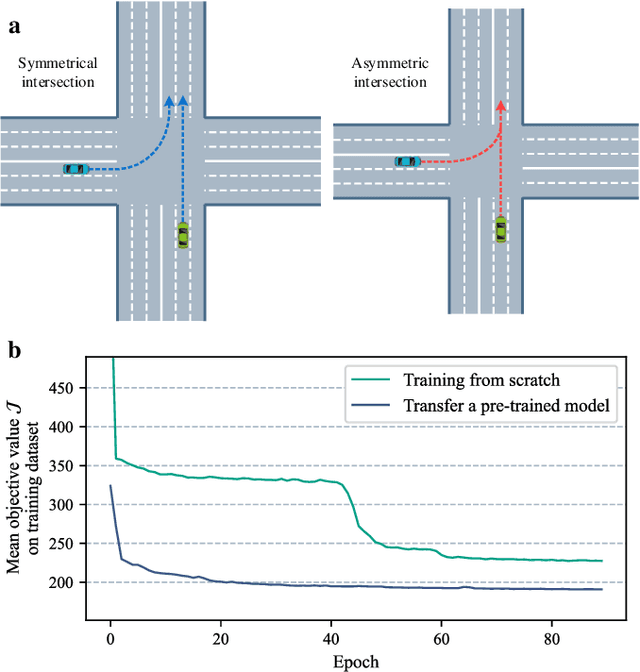
Connected and automated vehicles (CAVs) are viewed as a special kind of robots that have the potential to significantly improve the safety and efficiency of traffic. In contrast to many swarm robotics studies that are demonstrated in labs by employing a small number of robots, CAV studies aims to achieve cooperative driving of unceasing robot swarm flows. However, how to get the optimal passing order of such robot swarm flows even for a signal-free intersection is an NP-hard problem (specifically, enumerating based algorithm takes days to find the optimal solution to a 20-CAV scenario). Here, we introduce a novel cooperative driving algorithm (AlphaOrder) that combines offline deep learning and online tree searching to find a near-optimal passing order in real-time. AlphaOrder builds a pointer network model from solved scenarios and generates near-optimal passing orders instantaneously for new scenarios. Furthermore, our approach provides a general approach to managing preemptive resource sharing between swarm robotics (e.g., scheduling multiple automated guided vehicles (AGVs) and unmanned aerial vehicles (UAVs) at conflicting areas
Space-Time Graph Neural Networks
Oct 06, 2021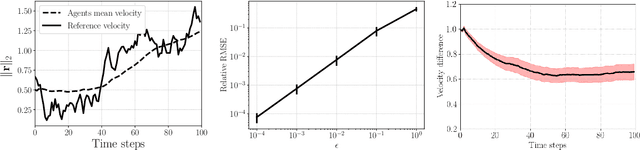
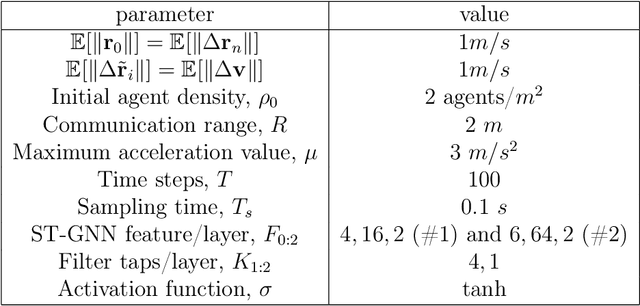
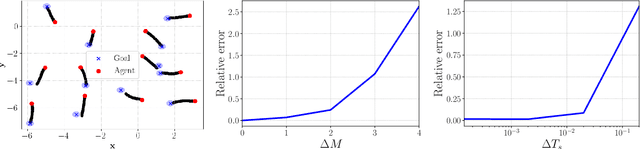
We introduce space-time graph neural network (ST-GNN), a novel GNN architecture, tailored to jointly process the underlying space-time topology of time-varying network data. The cornerstone of our proposed architecture is the composition of time and graph convolutional filters followed by pointwise nonlinear activation functions. We introduce a generic definition of convolution operators that mimic the diffusion process of signals over its underlying support. On top of this definition, we propose space-time graph convolutions that are built upon a composition of time and graph shift operators. We prove that ST-GNNs with multivariate integral Lipschitz filters are stable to small perturbations in the underlying graphs as well as small perturbations in the time domain caused by time warping. Our analysis shows that small variations in the network topology and time evolution of a system does not significantly affect the performance of ST-GNNs. Numerical experiments with decentralized control systems showcase the effectiveness and stability of the proposed ST-GNNs.
Sparse-Group Log-Sum Penalized Graphical Model Learning For Time Series
Apr 29, 2022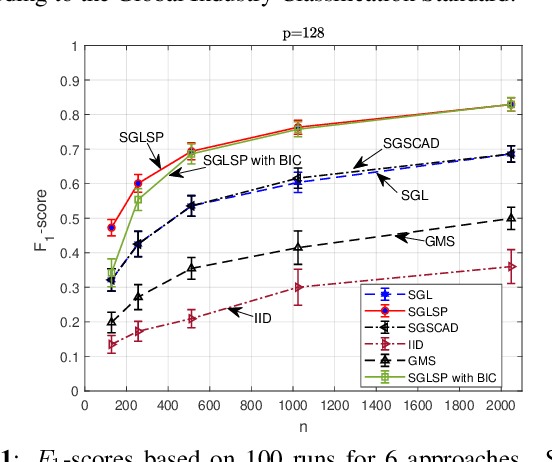
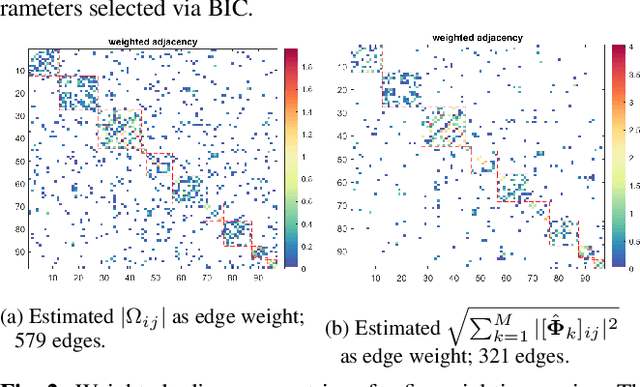
We consider the problem of inferring the conditional independence graph (CIG) of a high-dimensional stationary multivariate Gaussian time series. A sparse-group lasso based frequency-domain formulation of the problem has been considered in the literature where the objective is to estimate the sparse inverse power spectral density (PSD) of the data. The CIG is then inferred from the estimated inverse PSD. In this paper we investigate use of a sparse-group log-sum penalty (LSP) instead of sparse-group lasso penalty. An alternating direction method of multipliers (ADMM) approach for iterative optimization of the non-convex problem is presented. We provide sufficient conditions for local convergence in the Frobenius norm of the inverse PSD estimators to the true value. This results also yields a rate of convergence. We illustrate our approach using numerical examples utilizing both synthetic and real data.
Unsupervised classification of the spectrogram zeros
Oct 11, 2022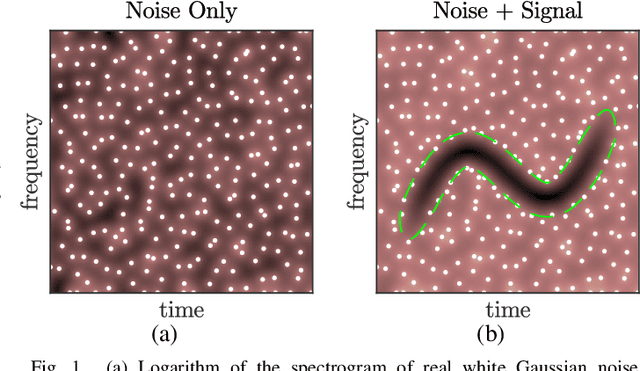
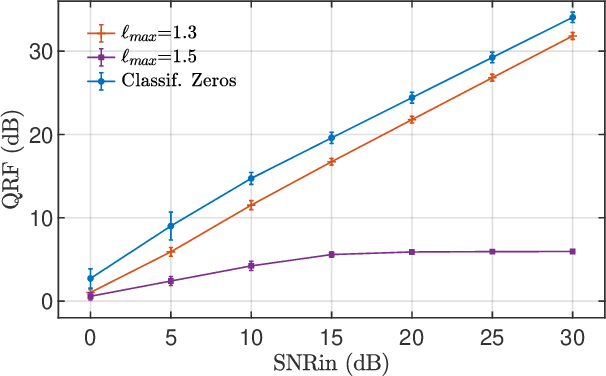
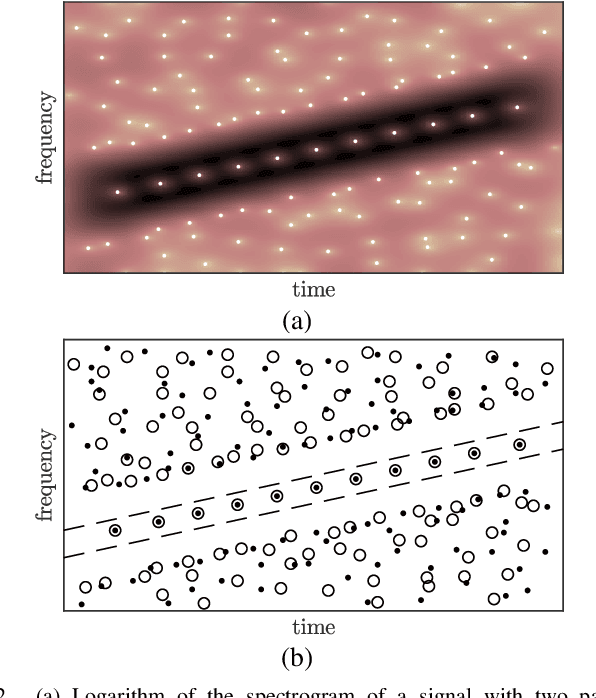

The zeros of the spectrogram have proven to be a relevant feature to describe the time-frequency structure of a signal, originated by the destructive interference between components in the time-frequency plane. In this work, a classification of these zeros in three types is introduced, based on the nature of the components that interfere to produce them. Echoing noise-assisted methods, a classification algorithm is proposed based on the addition of independent noise realizations to build a 2D histogram describing the stability of zeros. Features extracted from this histogram are later used to classify the zeros using a non-supervised clusterization algorithm. A denoising approach based on the classification of the spectrogram zeros is also introduced. Examples of the classification of zeros are given for synthetic and real signals, as well as a performance comparison of the proposed denoising algorithm with another zero-based approach.
Self-Distillation for Unsupervised 3D Domain Adaptation
Oct 15, 2022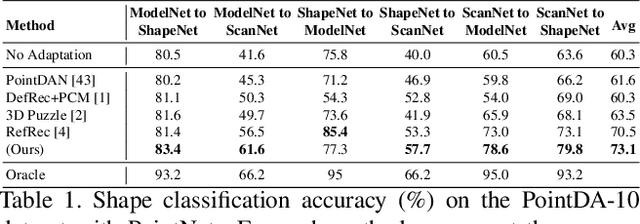
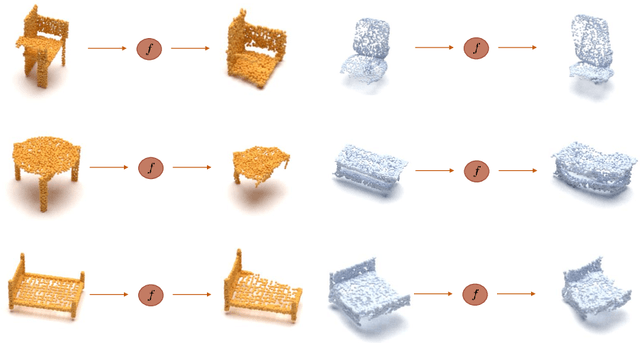

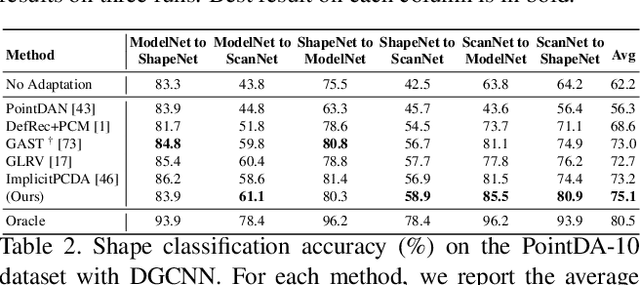
Point cloud classification is a popular task in 3D vision. However, previous works, usually assume that point clouds at test time are obtained with the same procedure or sensor as those at training time. Unsupervised Domain Adaptation (UDA) instead, breaks this assumption and tries to solve the task on an unlabeled target domain, leveraging only on a supervised source domain. For point cloud classification, recent UDA methods try to align features across domains via auxiliary tasks such as point cloud reconstruction, which however do not optimize the discriminative power in the target domain in feature space. In contrast, in this work, we focus on obtaining a discriminative feature space for the target domain enforcing consistency between a point cloud and its augmented version. We then propose a novel iterative self-training methodology that exploits Graph Neural Networks in the UDA context to refine pseudo-labels. We perform extensive experiments and set the new state-of-the-art in standard UDA benchmarks for point cloud classification. Finally, we show how our approach can be extended to more complex tasks such as part segmentation.
Automatic Neural Network Hyperparameter Optimization for Extrapolation: Lessons Learned from Visible and Near-Infrared Spectroscopy of Mango Fruit
Oct 03, 2022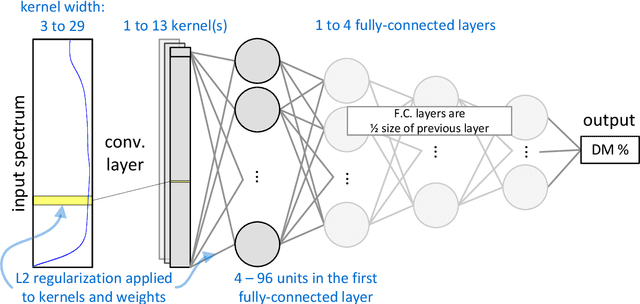
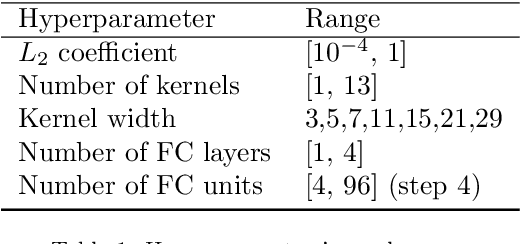

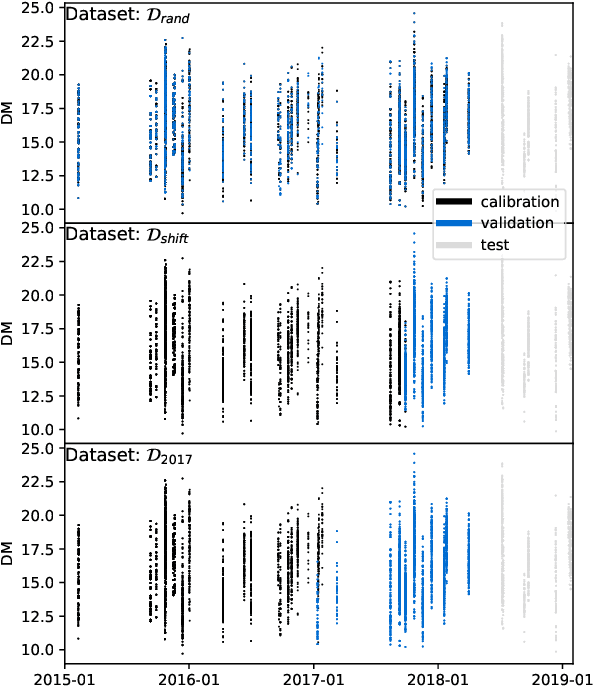
Neural networks are configured by choosing an architecture and hyperparameter values; doing so often involves expert intuition and hand-tuning to find a configuration that extrapolates well without overfitting. This paper considers automatic methods for configuring a neural network that extrapolates in time for the domain of visible and near-infrared (VNIR) spectroscopy. In particular, we study the effect of (a) selecting samples for validating configurations and (b) using ensembles. Most of the time, models are built of the past to predict the future. To encourage the neural network model to extrapolate, we consider validating model configurations on samples that are shifted in time similar to the test set. We experiment with three validation set choices: (1) a random sample of 1/3 of non-test data (the technique used in previous work), (2) using the latest 1/3 (sorted by time), and (3) using a semantically meaningful subset of the data. Hyperparameter optimization relies on the validation set to estimate test-set error, but neural network variance obfuscates the true error value. Ensemble averaging - computing the average across many neural networks - can reduce the variance of prediction errors. To test these methods, we do a comprehensive study of a held-out 2018 harvest season of mango fruit given VNIR spectra from 3 prior years. We find that ensembling improves the state-of-the-art model's variance and accuracy. Furthermore, hyperparameter optimization experiments - with and without ensemble averaging and with each validation set choice - show that when ensembling is combined with using the latest 1/3 of samples as the validation set, a neural network configuration is found automatically that is on par with the state-of-the-art.