 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Motion-Robust Remote Photoplethysmography through Arbitrary Resolution Videos
Dec 02, 2022
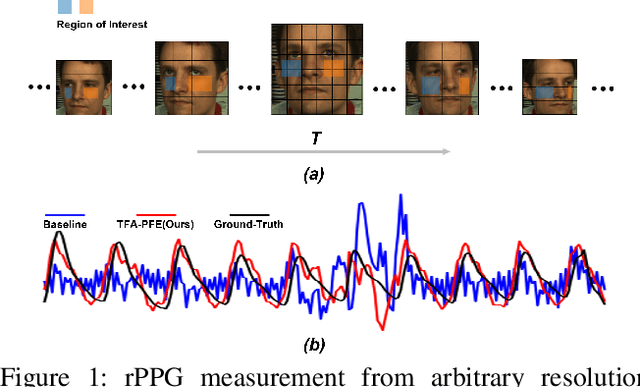
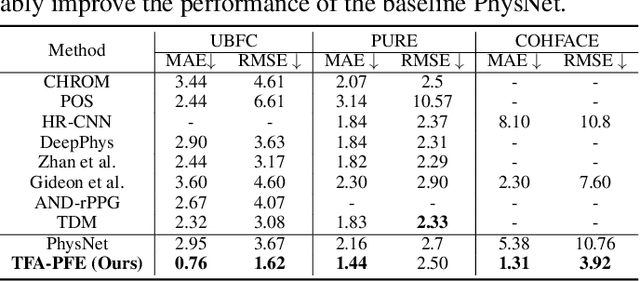
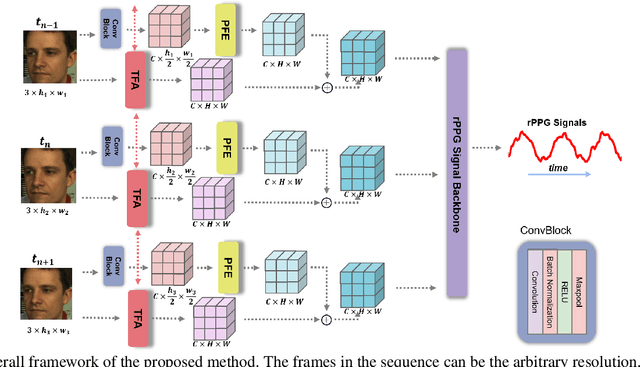
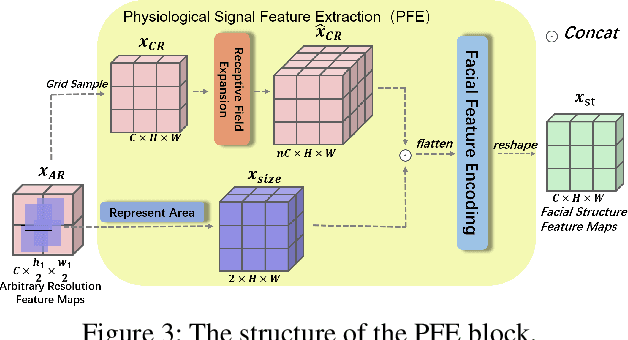
Remote photoplethysmography (rPPG) enables non-contact heart rate (HR) estimation from facial videos which gives significant convenience compared with traditional contact-based measurements. In the real-world long-term health monitoring scenario, the distance of the participants and their head movements usually vary by time, resulting in the inaccurate rPPG measurement due to the varying face resolution and complex motion artifacts. Different from the previous rPPG models designed for a constant distance between camera and participants, in this paper, we propose two plug-and-play blocks (i.e., physiological signal feature extraction block (PFE) and temporal face alignment block (TFA)) to alleviate the degradation of changing distance and head motion. On one side, guided with representative-area information, PFE adaptively encodes the arbitrary resolution facial frames to the fixed-resolution facial structure features. On the other side, leveraging the estimated optical flow, TFA is able to counteract the rPPG signal confusion caused by the head movement thus benefit the motion-robust rPPG signal recovery. Besides, we also train the model with a cross-resolution constraint using a two-stream dual-resolution framework, which further helps PFE learn resolution-robust facial rPPG features. Extensive experiments on three benchmark datasets (UBFC-rPPG, COHFACE and PURE) demonstrate the superior performance of the proposed method. One highlight is that with PFE and TFA, the off-the-shelf spatio-temporal rPPG models can predict more robust rPPG signals under both varying face resolution and severe head movement scenarios. The codes are available at https://github.com/LJW-GIT/Arbitrary_Resolution_rPPG.
DeepFT: Fault-Tolerant Edge Computing using a Self-Supervised Deep Surrogate Model
Dec 02, 2022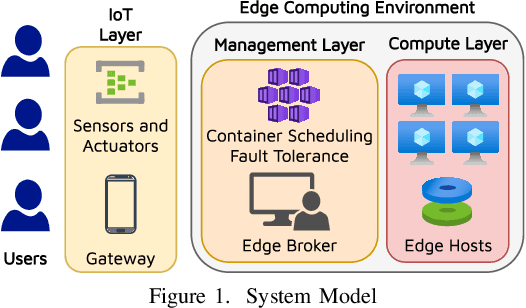

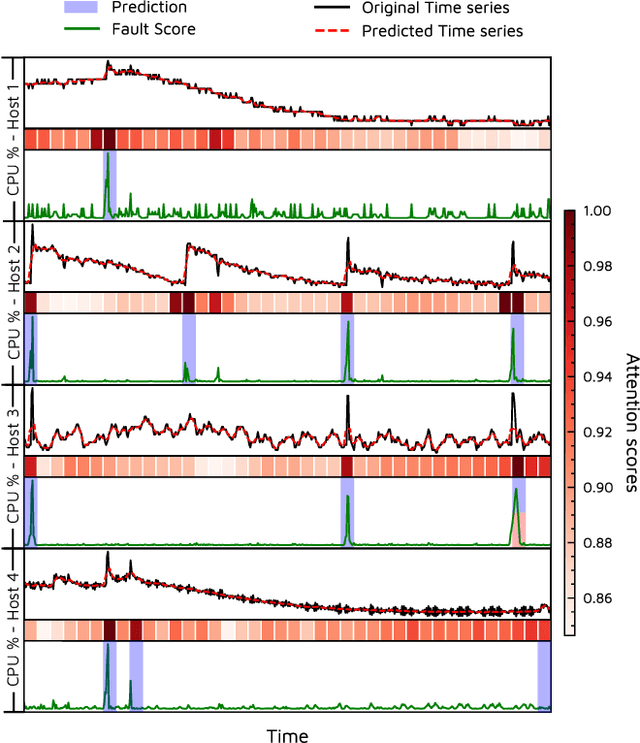

The emergence of latency-critical AI applications has been supported by the evolution of the edge computing paradigm. However, edge solutions are typically resource-constrained, posing reliability challenges due to heightened contention for compute and communication capacities and faulty application behavior in the presence of overload conditions. Although a large amount of generated log data can be mined for fault prediction, labeling this data for training is a manual process and thus a limiting factor for automation. Due to this, many companies resort to unsupervised fault-tolerance models. Yet, failure models of this kind can incur a loss of accuracy when they need to adapt to non-stationary workloads and diverse host characteristics. To cope with this, we propose a novel modeling approach, called DeepFT, to proactively avoid system overloads and their adverse effects by optimizing the task scheduling and migration decisions. DeepFT uses a deep surrogate model to accurately predict and diagnose faults in the system and co-simulation based self-supervised learning to dynamically adapt the model in volatile settings. It offers a highly scalable solution as the model size scales by only 3 and 1 percent per unit increase in the number of active tasks and hosts. Extensive experimentation on a Raspberry-Pi based edge cluster with DeFog benchmarks shows that DeepFT can outperform state-of-the-art baseline methods in fault-detection and QoS metrics. Specifically, DeepFT gives the highest F1 scores for fault-detection, reducing service deadline violations by up to 37\% while also improving response time by up to 9%.
SpectraNet: Multivariate Forecasting and Imputation under Distribution Shifts and Missing Data
Oct 25, 2022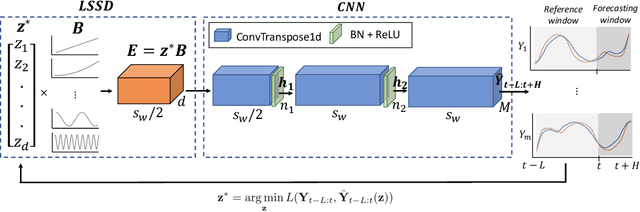
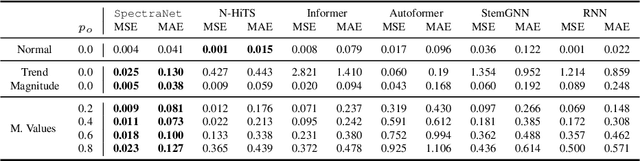
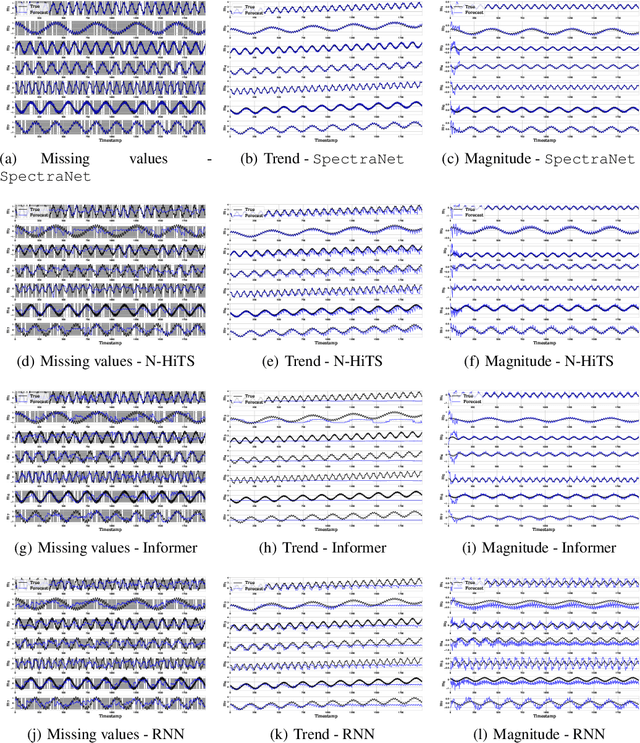
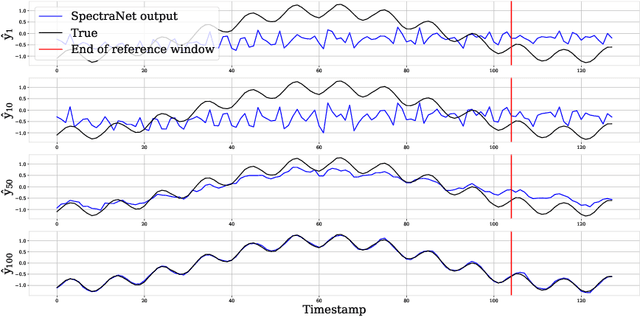
In this work, we tackle two widespread challenges in real applications for time-series forecasting that have been largely understudied: distribution shifts and missing data. We propose SpectraNet, a novel multivariate time-series forecasting model that dynamically infers a latent space spectral decomposition to capture current temporal dynamics and correlations on the recent observed history. A Convolution Neural Network maps the learned representation by sequentially mixing its components and refining the output. Our proposed approach can simultaneously produce forecasts and interpolate past observations and can, therefore, greatly simplify production systems by unifying imputation and forecasting tasks into a single model. SpectraNet achieves SoTA performance simultaneously on both tasks on five benchmark datasets, compared to forecasting and imputation models, with up to 92% fewer parameters and comparable training times. On settings with up to 80% missing data, SpectraNet has average performance improvements of almost 50% over the second-best alternative. Our code is available at https://github.com/cchallu/spectranet.
Adversarial Domain Adaptation for Action Recognition Around the Clock
Oct 25, 2022
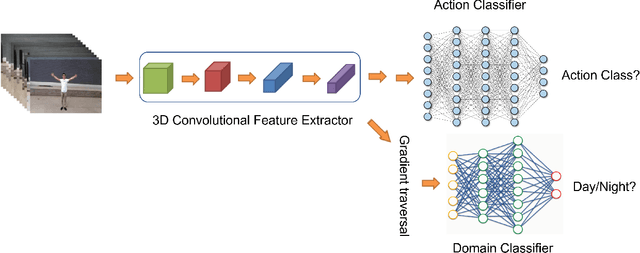


Due to the numerous potential applications in visual surveillance and nighttime driving, recognizing human action in low-light conditions remains a difficult problem in computer vision. Existing methods separate action recognition and dark enhancement into two distinct steps to accomplish this task. However, isolating the recognition and enhancement impedes end-to-end learning of the space-time representation for video action classification. This paper presents a domain adaptation-based action recognition approach that uses adversarial learning in cross-domain settings to learn cross-domain action recognition. Supervised learning can train it on a large amount of labeled data from the source domain (daytime action sequences). However, it uses deep domain invariant features to perform unsupervised learning on many unlabelled data from the target domain (night-time action sequences). The resulting augmented model, named 3D-DiNet can be trained using standard backpropagation with an additional layer. It achieves SOTA performance on InFAR and XD145 actions datasets.
Input-Output Relation and Performance of RIS-Aided OTFS with Fractional Delay-Doppler
Oct 25, 2022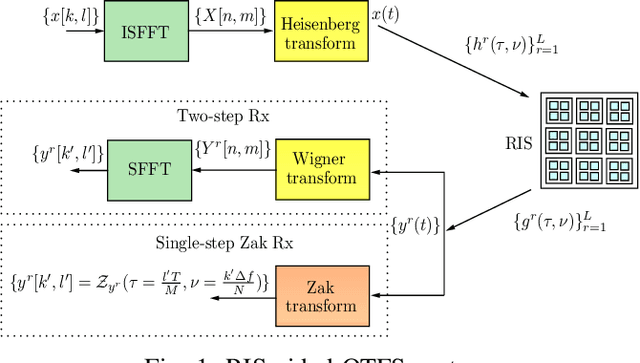
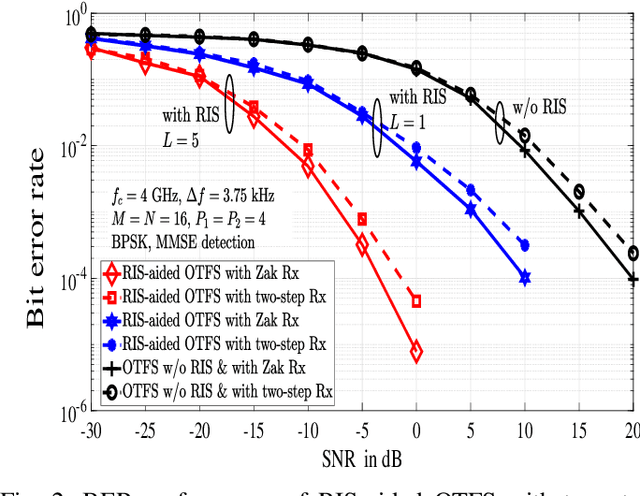
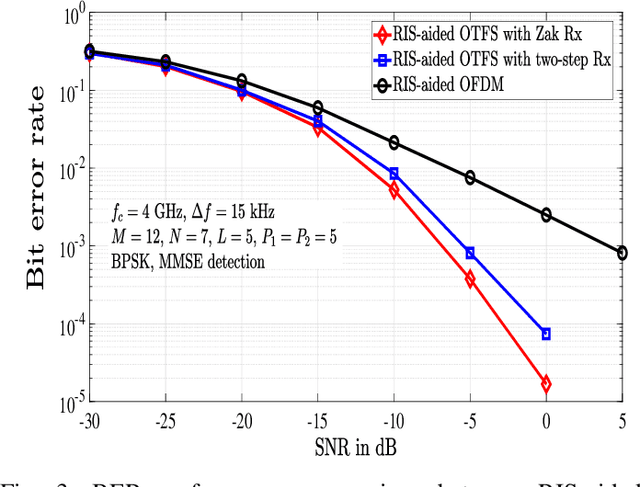
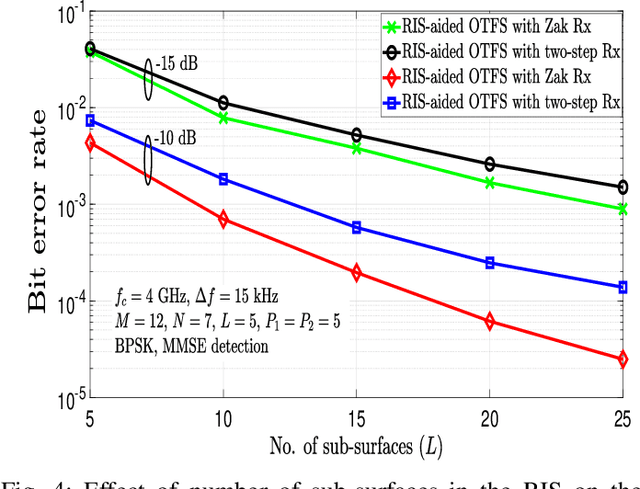
Reconfigurable intelligent surfaces (RIS) and orthogonal time-frequency space (OTFS) modulation have gained attention in recent wireless research. RIS technology aids communication by reflecting the incident electromagnetic waves towards the receiver, and OTFS modulation is effective in high-Doppler channels. This paper presents an early investigation of RIS-aided OTFS in high-Doppler channels. We derive the end-to-end delay-Doppler (DD) domain input-output relation of a RIS-aided OTFS system, considering rectangular pulses and fractional delay-Doppler values. We also consider a Zak receiver for RIS-aided OTFS that converts the received time-domain signal to DD domain in one step using Zak transform, and derive its end-to-end input-output relation. Our simulation results show that $i)$ RIS-aided OTFS performs better than OTFS without RIS, $ii)$ Zak receiver performs better than a two-step receiver, and $iii)$ RIS-aided OTFS achieves superior performance compared to RIS-aided OFDM.
First Competitive Ant Colony Scheme for the CARP
Nov 19, 2022
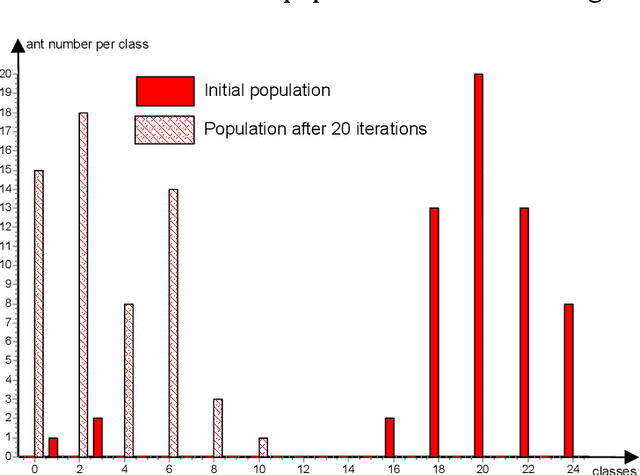
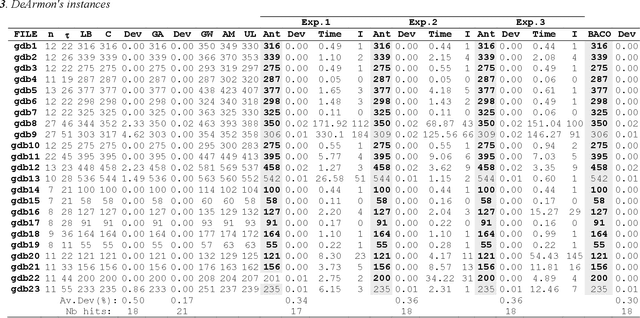
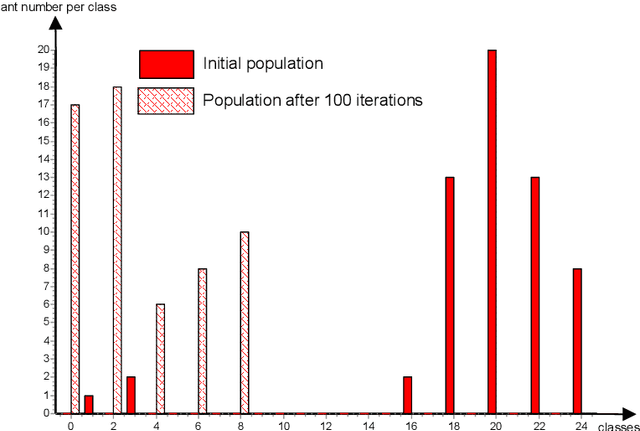
This paper addresses the Capacitated Arc Routing Problem (CARP) using an Ant Colony Optimization scheme. Ant Colony schemes can compute solutions for medium scale instances of VRP. The proposed Ant Colony is dedicated to large-scale instances of CARP with more than 140 nodes and 190 arcs to service. The Ant Colony scheme is coupled with a local search procedure and provides high quality solutions. The benchmarks we carried out prove possible to obtain solutions as profitable as CARPET ones can be obtained using such scheme when a sufficient number of iterations is devoted to the ants. It competes with the Genetic Algorithm of Lacomme et al. regarding solution quality but it is more time consuming on large scale instances. The method has been intensively benchmarked on the well-known instances of Eglese, DeArmon and the last ones of Belenguer and Benavent. This research report is a step forward CARP resolution by Ant Colony proving ant schemes can compete with Taboo search methods and Genetic Algorithms
NVDiff: Graph Generation through the Diffusion of Node Vectors
Nov 19, 2022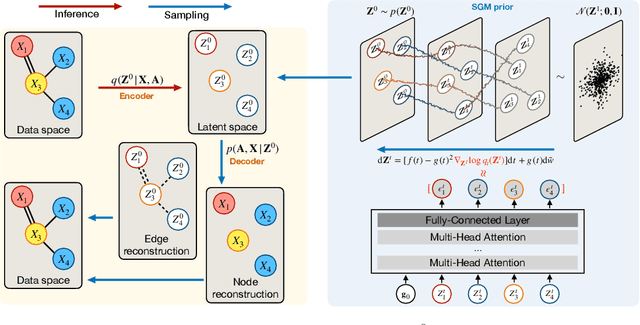
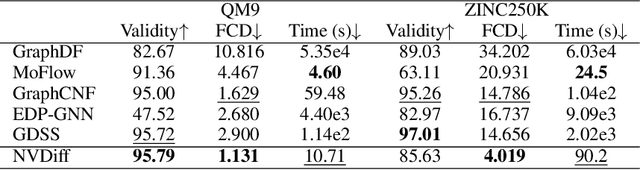
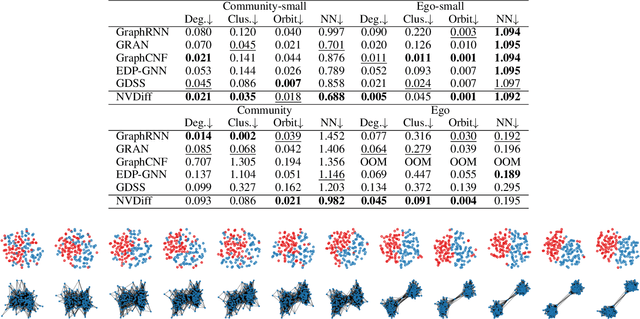
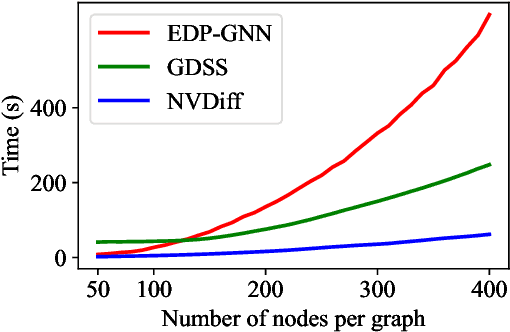
Learning to generate graphs is challenging as a graph is a set of pairwise connected, unordered nodes encoding complex combinatorial structures. Recently, several works have proposed graph generative models based on normalizing flows or score-based diffusion models. However, these models need to generate nodes and edges in parallel from the same process, whose dimensionality is unnecessarily high. We propose NVDiff, which takes the VGAE structure and uses a score-based generative model (SGM) as a flexible prior to sample node vectors. By modeling only node vectors in the latent space, NVDiff significantly reduces the dimension of the diffusion process and thus improves sampling speed. Built on the NVDiff framework, we introduce an attention-based score network capable of capturing both local and global contexts of graphs. Experiments indicate that NVDiff significantly reduces computations and can model much larger graphs than competing methods. At the same time, it achieves superior or competitive performances over various datasets compared to previous methods.
Quality Assurance in MLOps Setting: An Industrial Perspective
Nov 24, 2022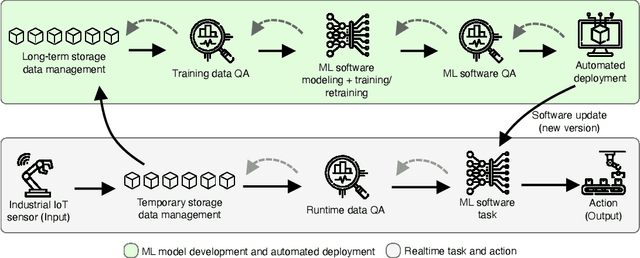
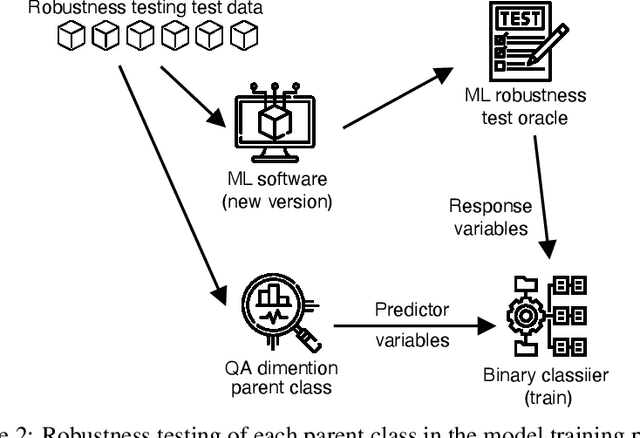
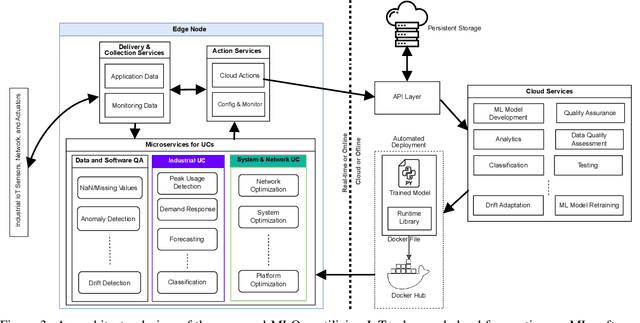
Today, machine learning (ML) is widely used in industry to provide the core functionality of production systems. However, it is practically always used in production systems as part of a larger end-to-end software system that is made up of several other components in addition to the ML model. Due to production demand and time constraints, automated software engineering practices are highly applicable. The increased use of automated ML software engineering practices in industries such as manufacturing and utilities requires an automated Quality Assurance (QA) approach as an integral part of ML software. Here, QA helps reduce risk by offering an objective perspective on the software task. Although conventional software engineering has automated tools for QA data analysis for data-driven ML, the use of QA practices for ML in operation (MLOps) is lacking. This paper examines the QA challenges that arise in industrial MLOps and conceptualizes modular strategies to deal with data integrity and Data Quality (DQ). The paper is accompanied by real industrial use-cases from industrial partners. The paper also presents several challenges that may serve as a basis for future studies.
ReFace: Improving Clothes-Changing Re-Identification With Face Features
Nov 24, 2022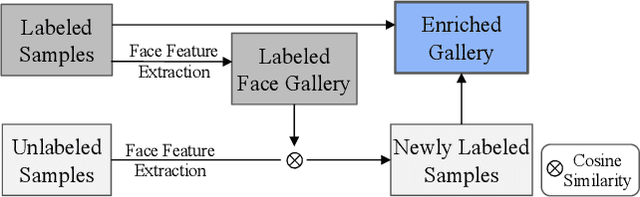
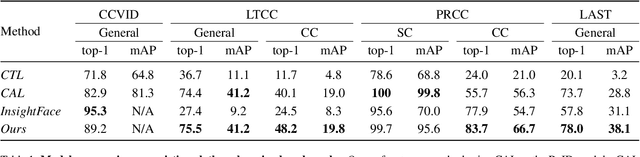
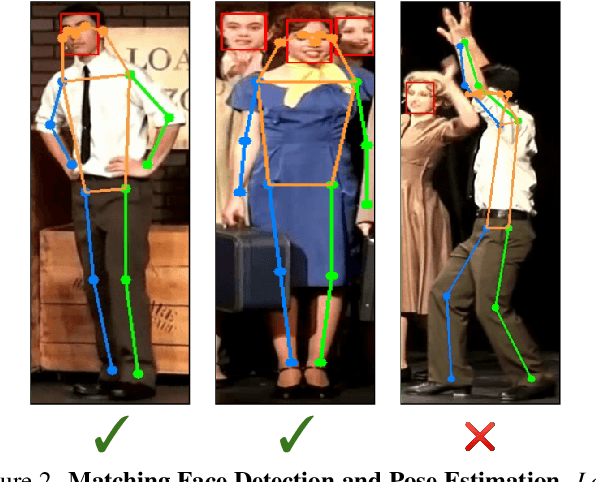
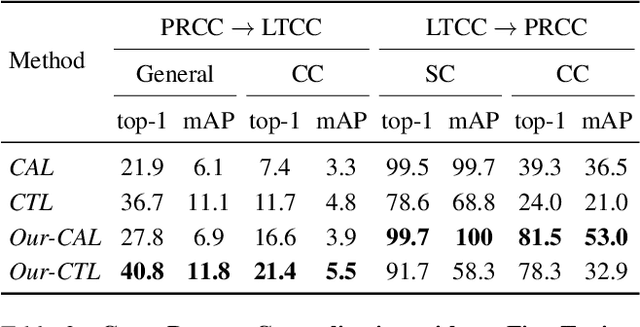
Person re-identification (ReID) has been an active research field for many years. Despite that, models addressing this problem tend to perform poorly when the task is to re-identify the same people over a prolonged time, due to appearance changes such as different clothes and hairstyles. In this work, we introduce a new method that takes full advantage of the ability of existing ReID models to extract appearance-related features and combines it with a face feature extraction model to achieve new state-of-the-art results, both on image-based and video-based benchmarks. Moreover, we show how our method could be used for an application in which multiple people of interest, under clothes-changing settings, should be re-identified given an unseen video and a limited amount of labeled data. We claim that current ReID benchmarks do not represent such real-world scenarios, and publish a new dataset, 42Street, based on a theater play as an example of such an application. We show that our proposed method outperforms existing models also on this dataset while using only pre-trained modules and without any further training.
Learning-enhanced Nonlinear Model Predictive Control using Knowledge-based Neural Ordinary Differential Equations and Deep Ensembles
Nov 24, 2022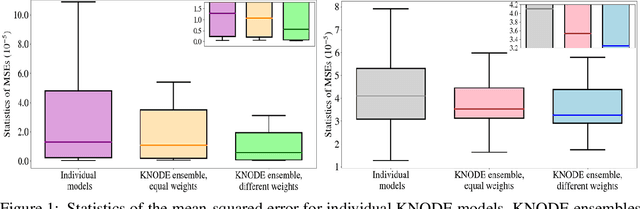
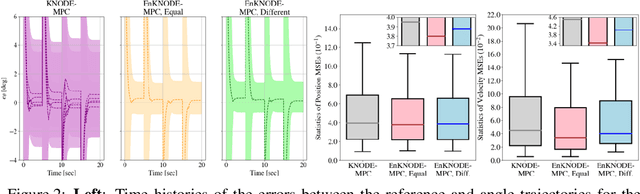
Nonlinear model predictive control (MPC) is a flexible and increasingly popular framework used to synthesize feedback control strategies that can satisfy both state and control input constraints. In this framework, an optimization problem, subjected to a set of dynamics constraints characterized by a nonlinear dynamics model, is solved at each time step. Despite its versatility, the performance of nonlinear MPC often depends on the accuracy of the dynamics model. In this work, we leverage deep learning tools, namely knowledge-based neural ordinary differential equations (KNODE) and deep ensembles, to improve the prediction accuracy of this model. In particular, we learn an ensemble of KNODE models, which we refer to as the KNODE ensemble, to obtain an accurate prediction of the true system dynamics. This learned model is then integrated into a novel learning-enhanced nonlinear MPC framework. We provide sufficient conditions that guarantees asymptotic stability of the closed-loop system and show that these conditions can be implemented in practice. We show that the KNODE ensemble provides more accurate predictions and illustrate the efficacy and closed-loop performance of the proposed nonlinear MPC framework using two case studies.