 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A smart resource management mechanism with trust access control for cloud computing environment
Dec 10, 2022
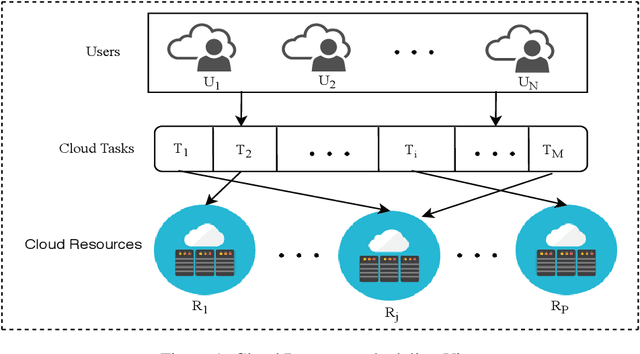
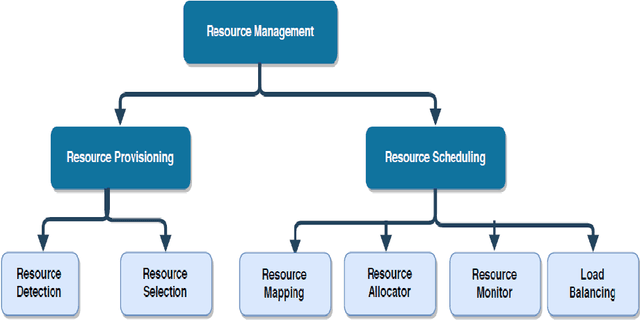
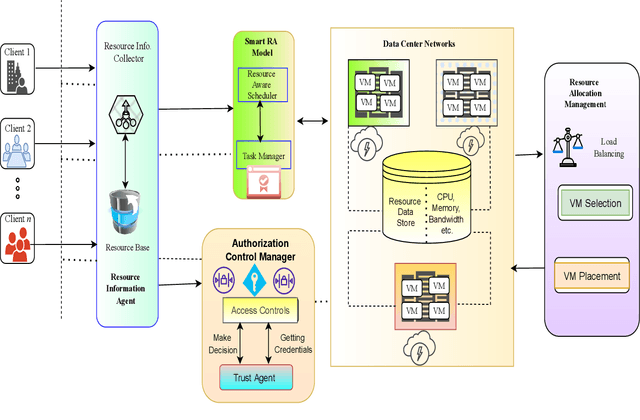
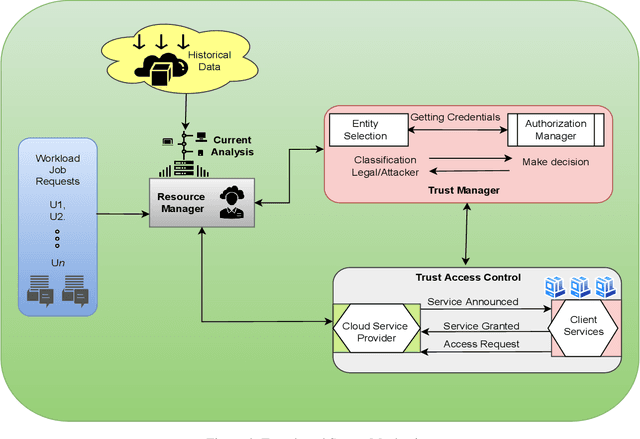
The core of the computer business now offers subscription-based on-demand services with the help of cloud computing. We may now share resources among multiple users by using virtualization, which creates a virtual instance of a computer system running in an abstracted hardware layer. It provides infinite computing capabilities through its massive cloud datacenters, in contrast to early distributed computing models, and has been incredibly popular in recent years because to its continually growing infrastructure, user base, and hosted data volume. This article suggests a conceptual framework for a workload management paradigm in cloud settings that is both safe and performance-efficient. A resource management unit is used in this paradigm for energy and performing virtual machine allocation with efficiency, assuring the safe execution of users' applications, and protecting against data breaches brought on by unauthorised virtual machine access real-time. A secure virtual machine management unit controls the resource management unit and is created to produce data on unlawful access or intercommunication. Additionally, a workload analyzer unit works simultaneously to estimate resource consumption data to help the resource management unit be more effective during virtual machine allocation. The suggested model functions differently to effectively serve the same objective, including data encryption and decryption prior to transfer, usage of trust access mechanism to prevent unauthorised access to virtual machines, which creates extra computational cost overhead.
QVIP: An ILP-based Formal Verification Approach for Quantized Neural Networks
Dec 10, 2022
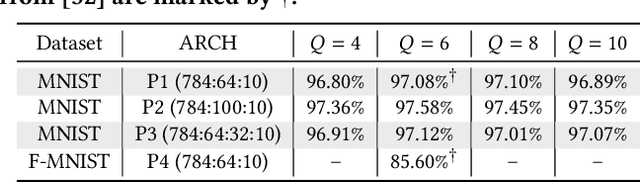

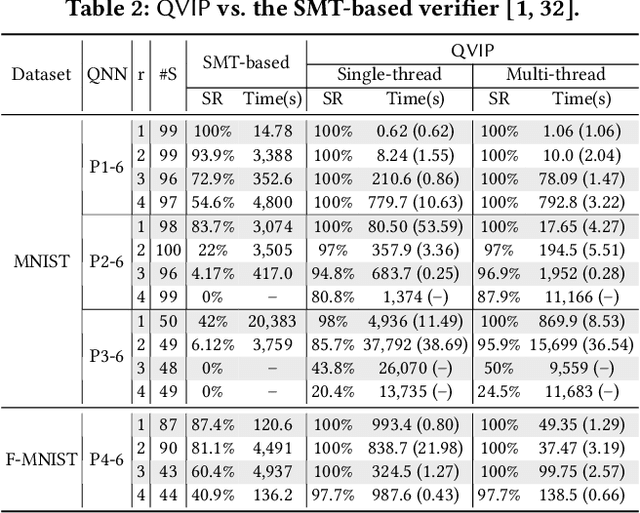
Deep learning has become a promising programming paradigm in software development, owing to its surprising performance in solving many challenging tasks. Deep neural networks (DNNs) are increasingly being deployed in practice, but are limited on resource-constrained devices owing to their demand for computational power. Quantization has emerged as a promising technique to reduce the size of DNNs with comparable accuracy as their floating-point numbered counterparts. The resulting quantized neural networks (QNNs) can be implemented energy-efficiently. Similar to their floating-point numbered counterparts, quality assurance techniques for QNNs, such as testing and formal verification, are essential but are currently less explored. In this work, we propose a novel and efficient formal verification approach for QNNs. In particular, we are the first to propose an encoding that reduces the verification problem of QNNs into the solving of integer linear constraints, which can be solved using off-the-shelf solvers. Our encoding is both sound and complete. We demonstrate the application of our approach on local robustness verification and maximum robustness radius computation. We implement our approach in a prototype tool QVIP and conduct a thorough evaluation. Experimental results on QNNs with different quantization bits confirm the effectiveness and efficiency of our approach, e.g., two orders of magnitude faster and able to solve more verification tasks in the same time limit than the state-of-the-art methods.
Routine Outcome Monitoring in Psychotherapy Treatment using Sentiment-Topic Modelling Approach
Dec 08, 2022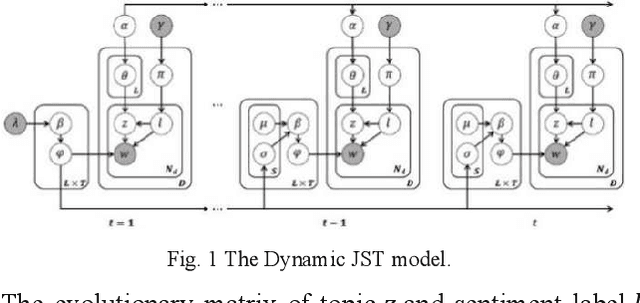
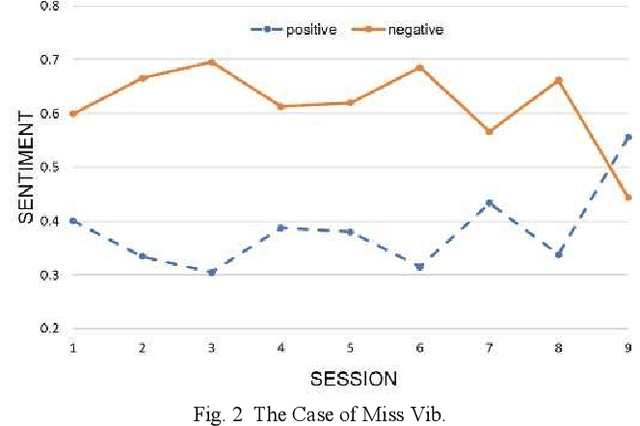
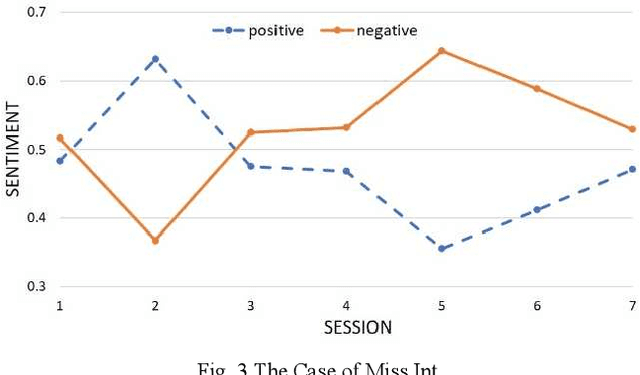
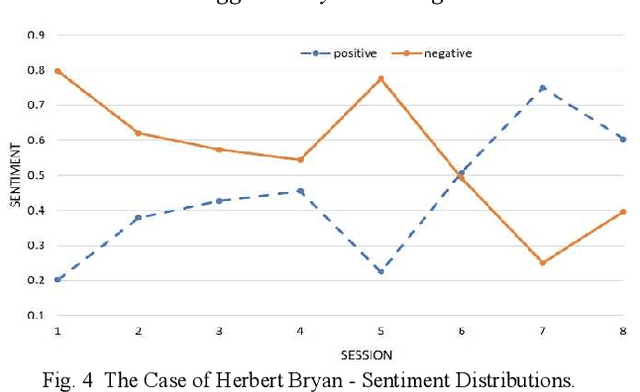
Despite the importance of emphasizing the right psychotherapy treatment for an individual patient, assessing the outcome of the therapy session is equally crucial. Evidence showed that continuous monitoring patient's progress can significantly improve the therapy outcomes to an expected change. By monitoring the outcome, the patient's progress can be tracked closely to help clinicians identify patients who are not progressing in the treatment. These monitoring can help the clinician to consider any necessary actions for the patient's treatment as early as possible, e.g., recommend different types of treatment, or adjust the style of approach. Currently, the evaluation system is based on the clinical-rated and self-report questionnaires that measure patients' progress pre- and post-treatment. While outcome monitoring tends to improve the therapy outcomes, however, there are many challenges in the current method, e.g. time and financial burden for administering questionnaires, scoring and analysing the results. Therefore, a computational method for measuring and monitoring patient progress over the course of treatment is needed, in order to enhance the likelihood of positive treatment outcome. Moreover, this computational method could potentially lead to an inexpensive monitoring tool to evaluate patients' progress in clinical care that could be administered by a wider range of health-care professionals.
Generalizing LTL Instructions via Future Dependent Options
Dec 08, 2022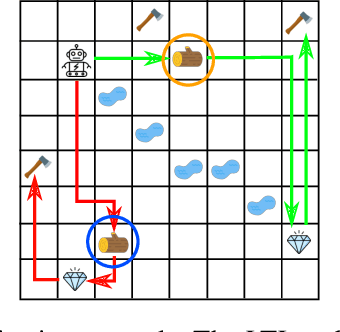
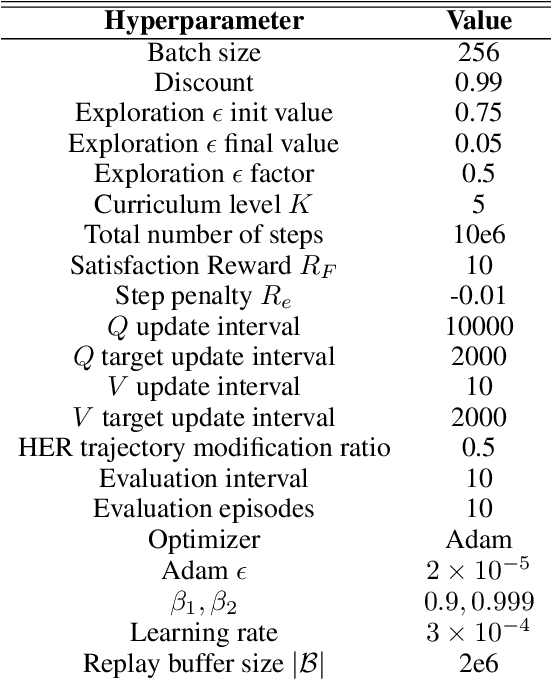

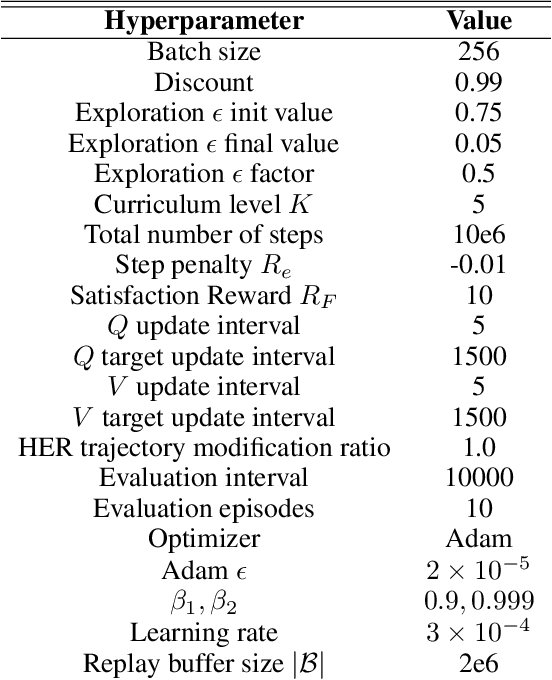
Linear temporal logic (LTL) is a widely-used task specification language which has a compositional grammar that naturally induces temporally extended behaviours across tasks, including conditionals and alternative realizations. An important problem i RL with LTL tasks is to learn task-conditioned policies which can zero-shot generalize to new LTL instructions not observed in the training. However, because symbolic observation is often lossy and LTL tasks can have long time horizon, previous works can suffer from issues such as training sampling inefficiency and infeasibility or sub-optimality of the found solutions. In order to tackle these issues, this paper proposes a novel multi-task RL algorithm with improved learning efficiency and optimality. To achieve the global optimality of task completion, we propose to learn options dependent on the future subgoals via a novel off-policy approach. In order to propagate the rewards of satisfying future subgoals back more efficiently, we propose to train a multi-step value function conditioned on the subgoal sequence which is updated with Monte Carlo estimates of multi-step discounted returns. In experiments on three different domains, we evaluate the LTL generalization capability of the agent trained by the proposed method, showing its advantage over previous representative methods.
Lie detection algorithms attract few users but vastly increase accusation rates
Dec 08, 2022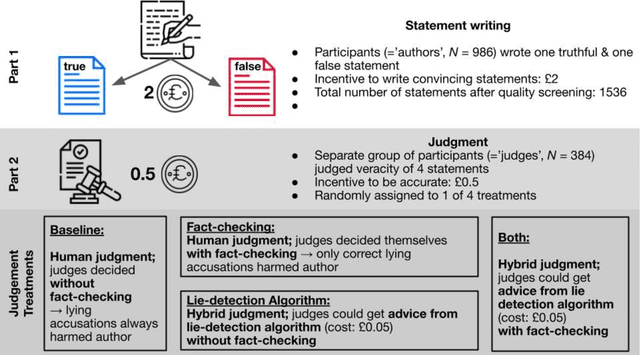
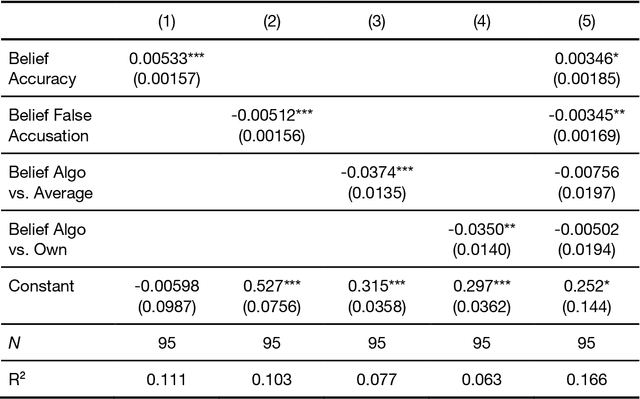
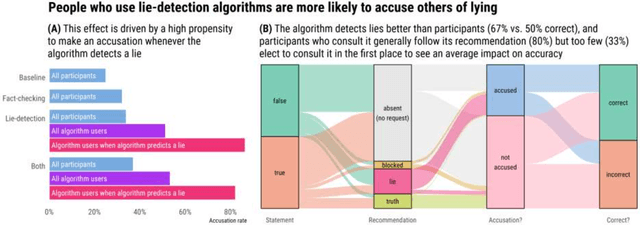
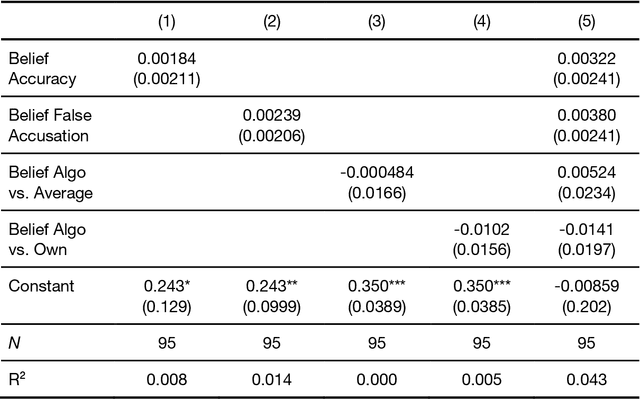
People are not very good at detecting lies, which may explain why they refrain from accusing others of lying, given the social costs attached to false accusations - both for the accuser and the accused. Here we consider how this social balance might be disrupted by the availability of lie-detection algorithms powered by Artificial Intelligence. Will people elect to use lie detection algorithms that perform better than humans, and if so, will they show less restraint in their accusations? We built a machine learning classifier whose accuracy (67\%) was significantly better than human accuracy (50\%) in a lie-detection task and conducted an incentivized lie-detection experiment in which we measured participants' propensity to use the algorithm, as well as the impact of that use on accusation rates. We find that the few people (33\%) who elect to use the algorithm drastically increase their accusation rates (from 25\% in the baseline condition up to 86% when the algorithm flags a statement as a lie). They make more false accusations (18pp increase), but at the same time, the probability of a lie remaining undetected is much lower in this group (36pp decrease). We consider individual motivations for using lie detection algorithms and the social implications of these algorithms.
Synaptic Dynamics Realize First-order Adaptive Learning and Weight Symmetry
Dec 01, 2022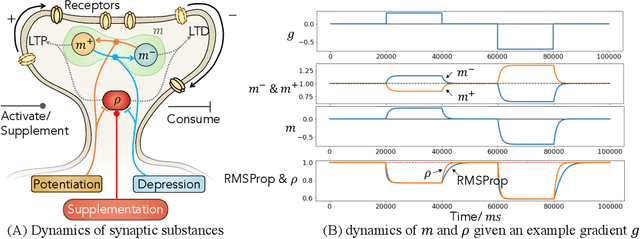
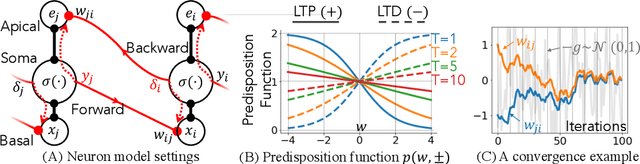
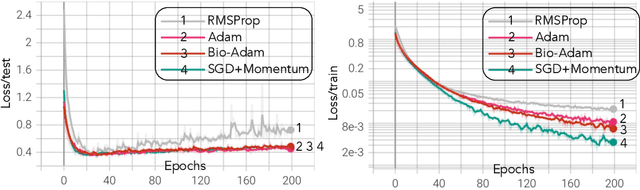
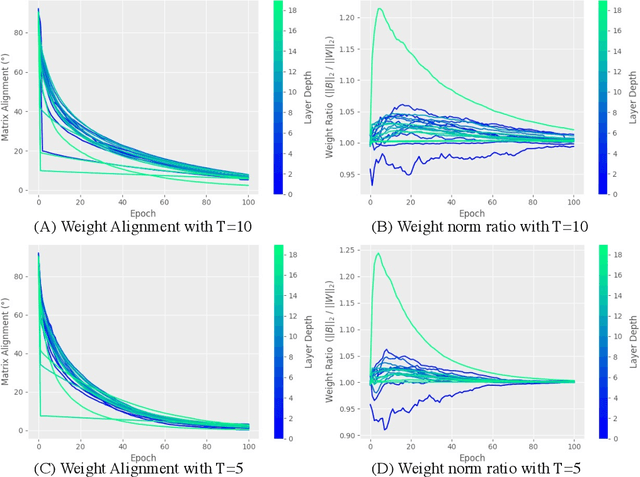
Gradient-based first-order adaptive optimization methods such as the Adam optimizer are prevalent in training artificial networks, achieving the state-of-the-art results. This work attempts to answer the question whether it is viable for biological neural systems to adopt such optimization methods. To this end, we demonstrate a realization of the Adam optimizer using biologically-plausible mechanisms in synapses. The proposed learning rule has clear biological correspondence, runs continuously in time, and achieves performance to comparable Adam's. In addition, we present a new approach, inspired by the predisposition property of synapses observed in neuroscience, to circumvent the biological implausibility of the weight transport problem in backpropagation (BP). With only local information and no separate training phases, this method establishes and maintains weight symmetry in the forward and backward signaling paths, and is applicable to the proposed biologically plausible Adam learning rule. These mechanisms may shed light on the way in which biological synaptic dynamics facilitate learning.
Navigating an Ocean of Video Data: Deep Learning for Humpback Whale Classification in YouTube Videos
Dec 01, 2022
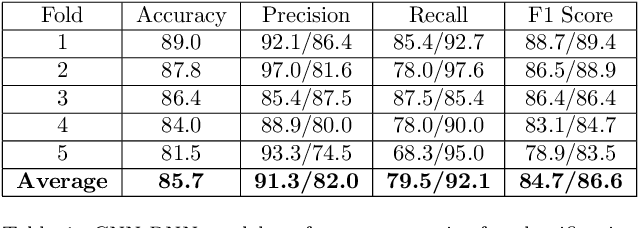
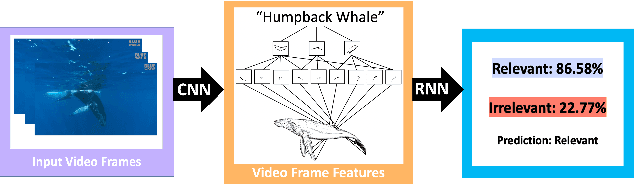

Image analysis technologies empowered by artificial intelligence (AI) have proved images and videos to be an opportune source of data to learn about humpback whale (Megaptera novaeangliae) population sizes and dynamics. With the advent of social media, platforms such as YouTube present an abundance of video data across spatiotemporal contexts documenting humpback whale encounters from users worldwide. In our work, we focus on automating the classification of YouTube videos as relevant or irrelevant based on whether they document a true humpback whale encounter or not via deep learning. We use a CNN-RNN architecture pretrained on the ImageNet dataset for classification of YouTube videos as relevant or irrelevant. We achieve an average 85.7% accuracy, and 84.7% (irrelevant)/ 86.6% (relevant) F1 scores using five-fold cross validation for evaluation on the dataset. We show that deep learning can be used as a time-efficient step to make social media a viable source of image and video data for biodiversity assessments.
GMM-IL: Image Classification using Incrementally Learnt, Independent Probabilistic Models for Small Sample Sizes
Dec 01, 2022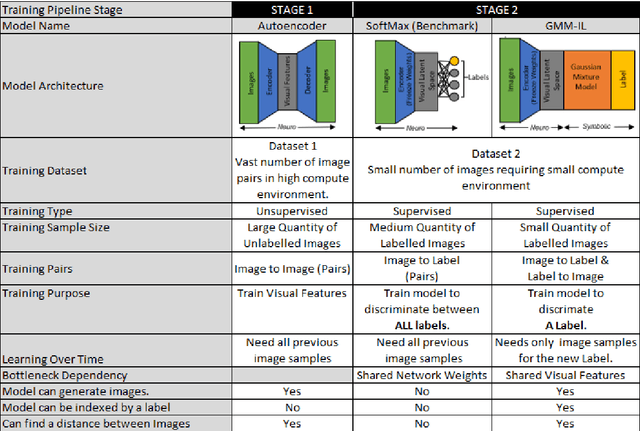
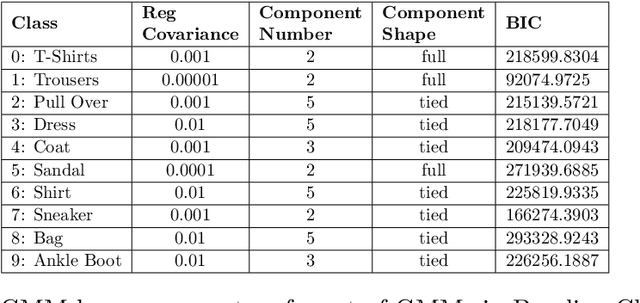
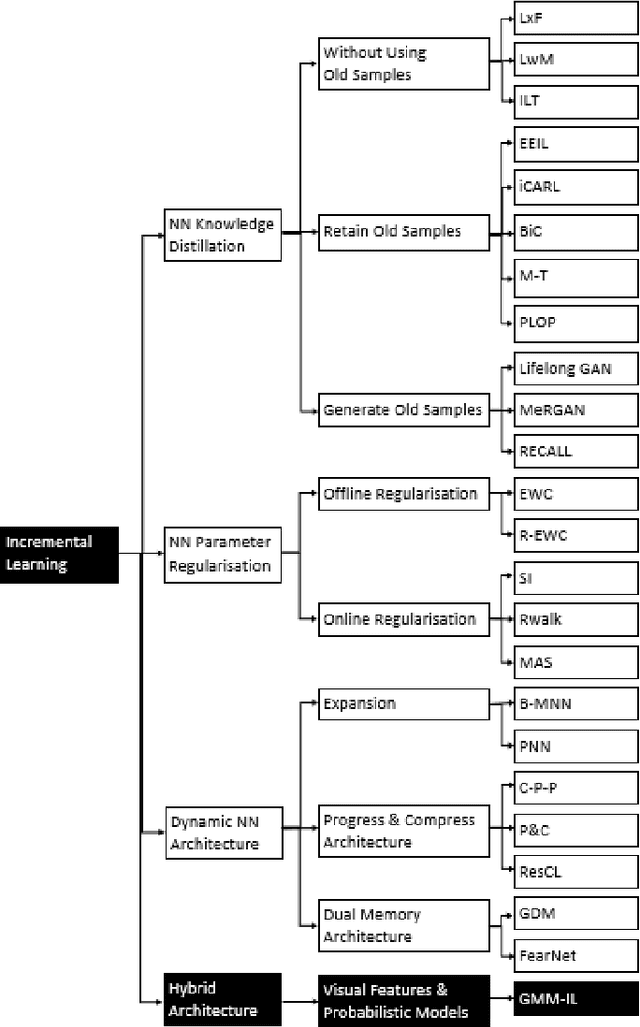
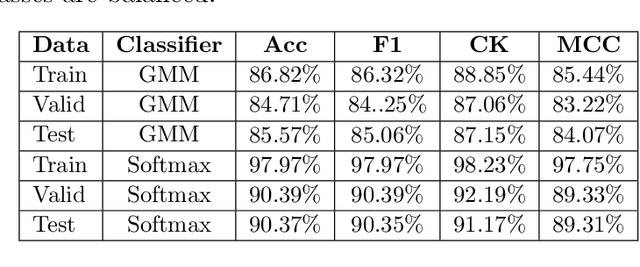
Current deep learning classifiers, carry out supervised learning and store class discriminatory information in a set of shared network weights. These weights cannot be easily altered to incrementally learn additional classes, since the classification weights all require retraining to prevent old class information from being lost and also require the previous training data to be present. We present a novel two stage architecture which couples visual feature learning with probabilistic models to represent each class in the form of a Gaussian Mixture Model. By using these independent class representations within our classifier, we outperform a benchmark of an equivalent network with a Softmax head, obtaining increased accuracy for sample sizes smaller than 12 and increased weighted F1 score for 3 imbalanced class profiles in that sample range. When learning new classes our classifier exhibits no catastrophic forgetting issues and only requires the new classes' training images to be present. This enables a database of growing classes over time which can be visually indexed and reasoned over.
Learning Dense and Continuous Optical Flow from an Event Camera
Nov 16, 2022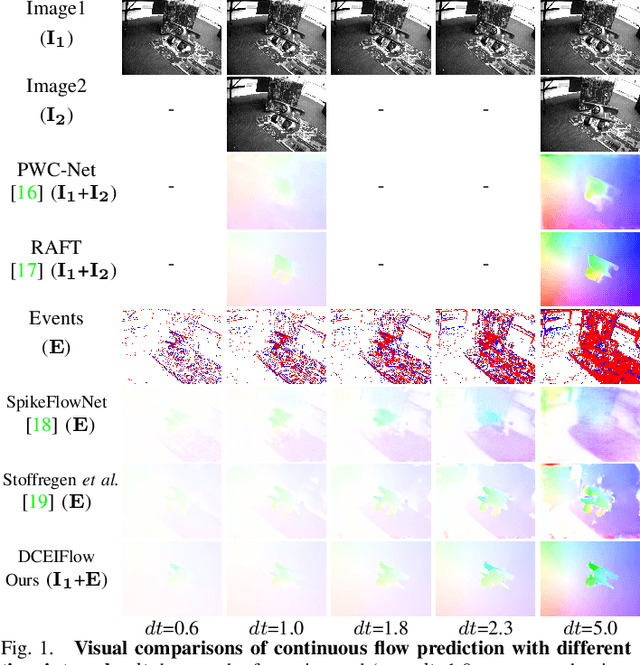
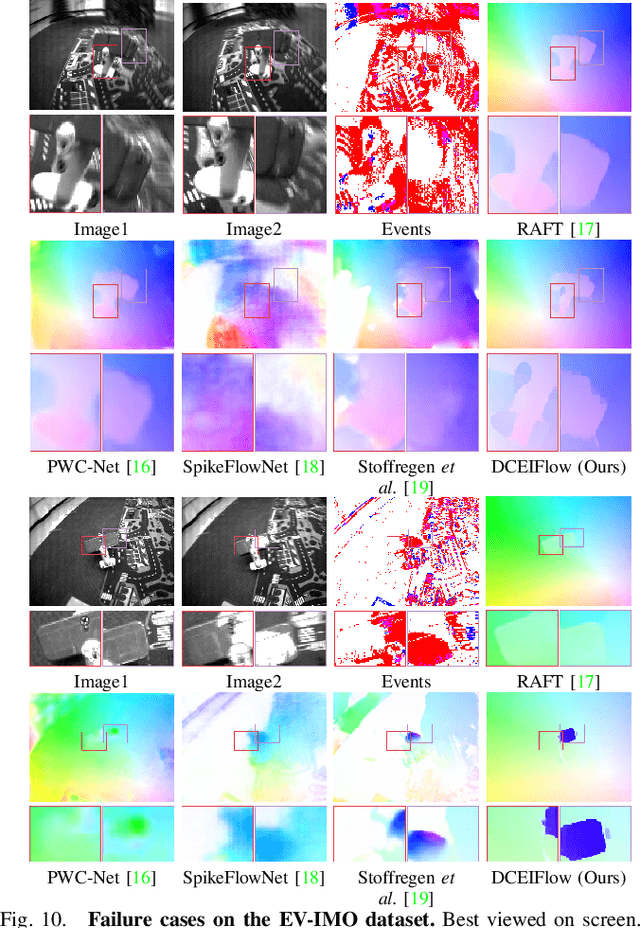
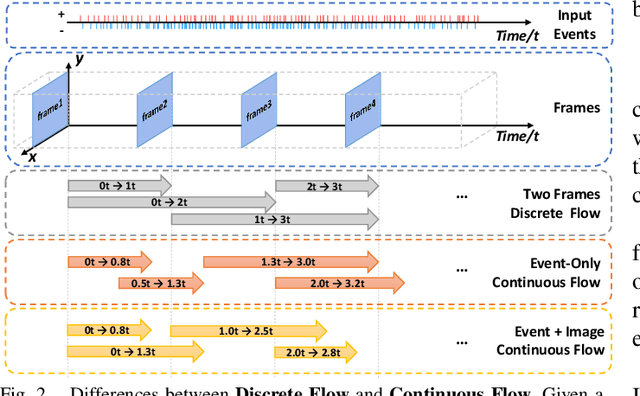
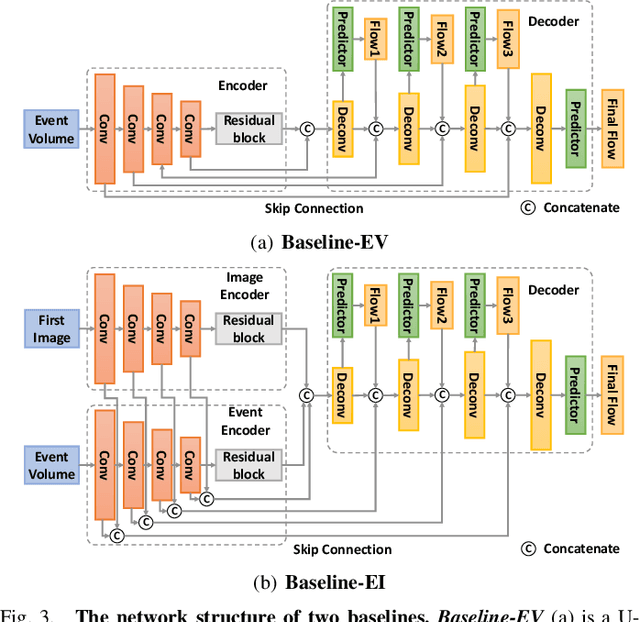
Event cameras such as DAVIS can simultaneously output high temporal resolution events and low frame-rate intensity images, which own great potential in capturing scene motion, such as optical flow estimation. Most of the existing optical flow estimation methods are based on two consecutive image frames and can only estimate discrete flow at a fixed time interval. Previous work has shown that continuous flow estimation can be achieved by changing the quantities or time intervals of events. However, they are difficult to estimate reliable dense flow , especially in the regions without any triggered events. In this paper, we propose a novel deep learning-based dense and continuous optical flow estimation framework from a single image with event streams, which facilitates the accurate perception of high-speed motion. Specifically, we first propose an event-image fusion and correlation module to effectively exploit the internal motion from two different modalities of data. Then we propose an iterative update network structure with bidirectional training for optical flow prediction. Therefore, our model can estimate reliable dense flow as two-frame-based methods, as well as estimate temporal continuous flow as event-based methods. Extensive experimental results on both synthetic and real captured datasets demonstrate that our model outperforms existing event-based state-of-the-art methods and our designed baselines for accurate dense and continuous optical flow estimation.
The non-overlapping statistical approximation to overlapping group lasso
Nov 16, 2022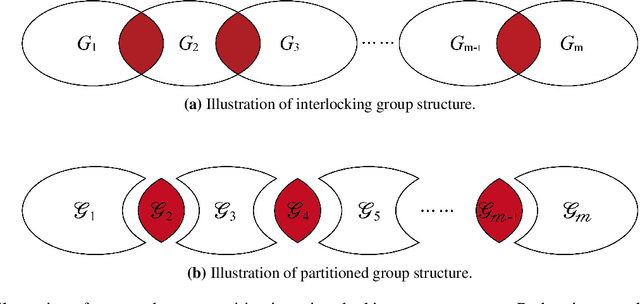
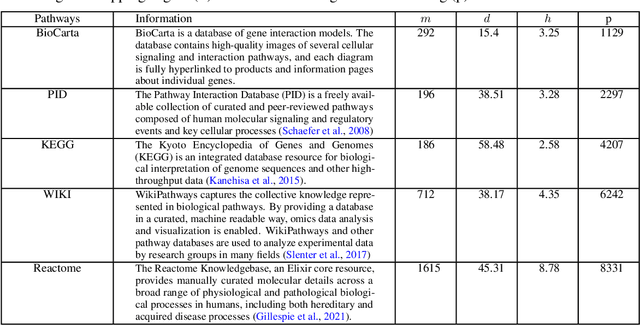

Group lasso is a commonly used regularization method in statistical learning in which parameters are eliminated from the model according to predefined groups. However, when the groups overlap, optimizing the group lasso penalized objective can be time-consuming on large-scale problems because of the non-separability induced by the overlapping groups. This bottleneck has seriously limited the application of overlapping group lasso regularization in many modern problems, such as gene pathway selection and graphical model estimation. In this paper, we propose a separable penalty as an approximation of the overlapping group lasso penalty. Thanks to the separability, the computation of regularization based on our penalty is substantially faster than that of the overlapping group lasso, especially for large-scale and high-dimensional problems. We show that the penalty is the tightest separable relaxation of the overlapping group lasso norm within the family of $\ell_{q_1}/\ell_{q_2}$ norms. Moreover, we show that the estimator based on the proposed separable penalty is statistically equivalent to the one based on the overlapping group lasso penalty with respect to their error bounds and the rate-optimal performance under the squared loss. We demonstrate the faster computational time and statistical equivalence of our method compared with the overlapping group lasso in simulation examples and a classification problem of cancer tumors based on gene expression and multiple gene pathways.