 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Speed up the inference of diffusion models via shortcut MCMC sampling
Dec 18, 2022

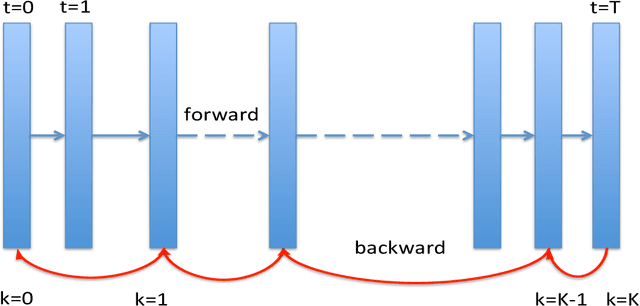
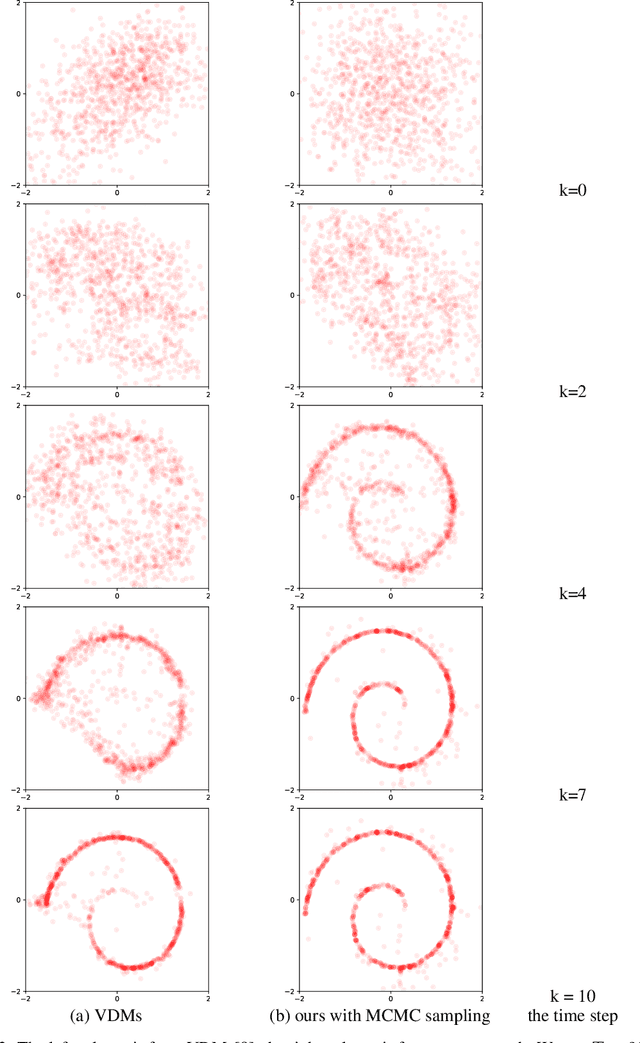
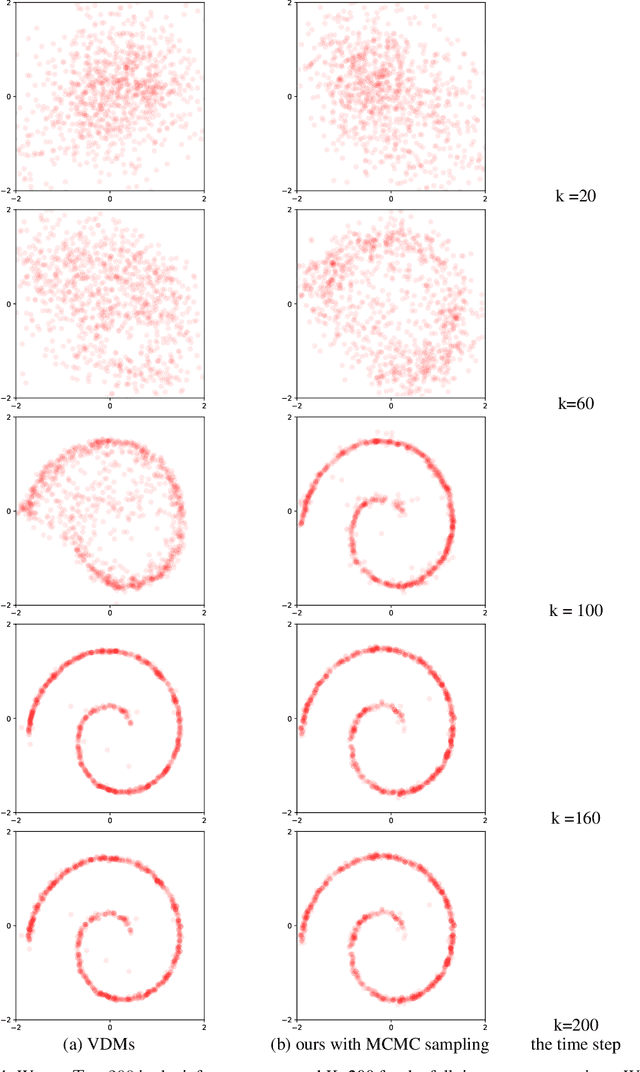
Diffusion probabilistic models have generated high quality image synthesis recently. However, one pain point is the notorious inference to gradually obtain clear images with thousands of steps, which is time consuming compared to other generative models. In this paper, we present a shortcut MCMC sampling algorithm, which balances training and inference, while keeping the generated data's quality. In particular, we add the global fidelity constraint with shortcut MCMC sampling to combat the local fitting from diffusion models. We do some initial experiments and show very promising results. Our implementation is available at https://github.com//vividitytech/diffusion-mcmc.git.
Spatio-Temporal Meta-Graph Learning for Traffic Forecasting
Dec 08, 2022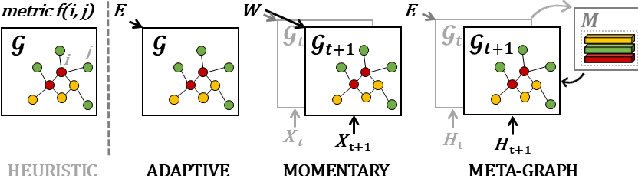

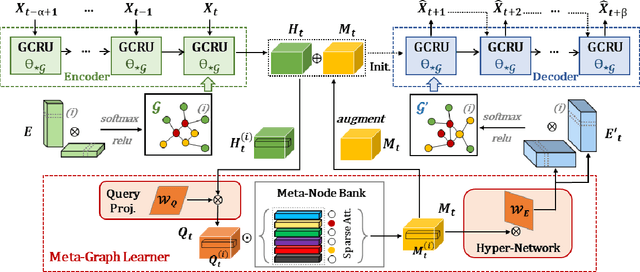
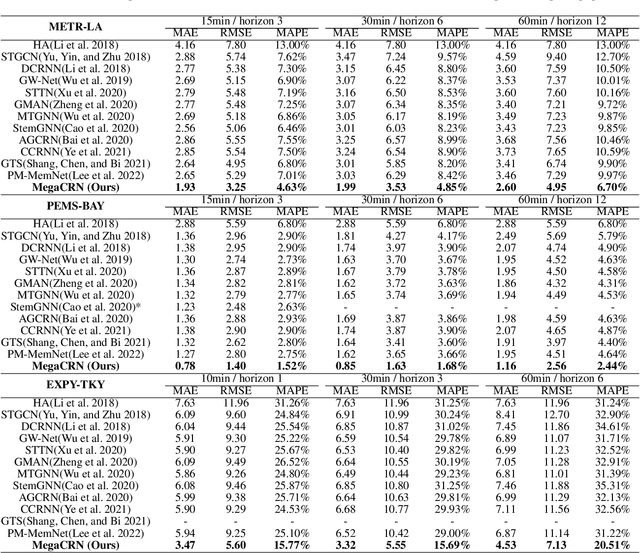
Traffic forecasting as a canonical task of multivariate time series forecasting has been a significant research topic in AI community. To address the spatio-temporal heterogeneity and non-stationarity implied in the traffic stream, in this study, we propose Spatio-Temporal Meta-Graph Learning as a novel Graph Structure Learning mechanism on spatio-temporal data. Specifically, we implement this idea into Meta-Graph Convolutional Recurrent Network (MegaCRN) by plugging the Meta-Graph Learner powered by a Meta-Node Bank into GCRN encoder-decoder. We conduct a comprehensive evaluation on two benchmark datasets (METR-LA and PEMS-BAY) and a new large-scale traffic speed dataset in which traffic incident information is contained. Our model outperformed the state-of-the-arts to a large degree on all three datasets (over 27% MAE and 34% RMSE). Besides, through a series of qualitative evaluations, we demonstrate that our model can explicitly disentangle the road links and time slots with different patterns and be robustly adaptive to any anomalous traffic situations. Codes and datasets are available at https://github.com/deepkashiwa20/MegaCRN.
Advanced Data Augmentation Approaches: A Comprehensive Survey and Future directions
Jan 07, 2023
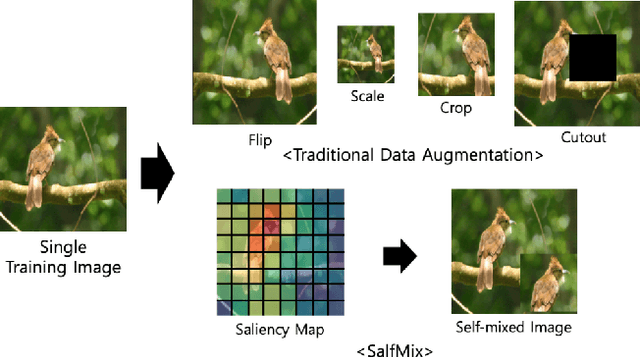


Deep learning (DL) algorithms have shown significant performance in various computer vision tasks. However, having limited labelled data lead to a network overfitting problem, where network performance is bad on unseen data as compared to training data. Consequently, it limits performance improvement. To cope with this problem, various techniques have been proposed such as dropout, normalization and advanced data augmentation. Among these, data augmentation, which aims to enlarge the dataset size by including sample diversity, has been a hot topic in recent times. In this article, we focus on advanced data augmentation techniques. we provide a background of data augmentation, a novel and comprehensive taxonomy of reviewed data augmentation techniques, and the strengths and weaknesses (wherever possible) of each technique. We also provide comprehensive results of the data augmentation effect on three popular computer vision tasks, such as image classification, object detection and semantic segmentation. For results reproducibility, we compiled available codes of all data augmentation techniques. Finally, we discuss the challenges and difficulties, and possible future direction for the research community. We believe, this survey provides several benefits i) readers will understand the data augmentation working mechanism to fix overfitting problems ii) results will save the searching time of the researcher for comparison purposes. iii) Codes of the mentioned data augmentation techniques are available at https://github.com/kmr2017/Advanced-Data-augmentation-codes iv) Future work will spark interest in research community.
360Roam: Real-Time Indoor Roaming Using Geometry-Aware ${360^\circ}$ Radiance Fields
Aug 04, 2022
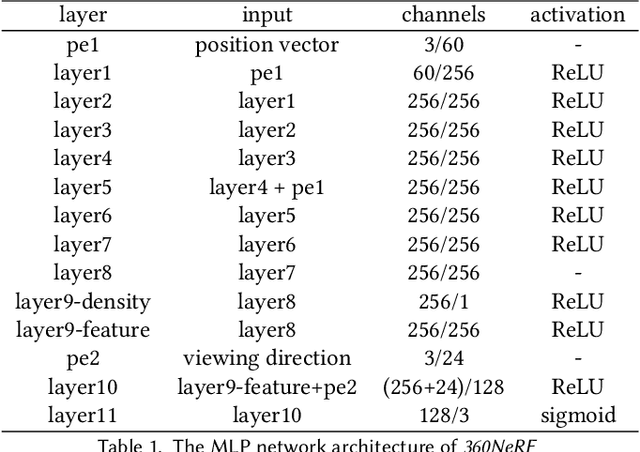
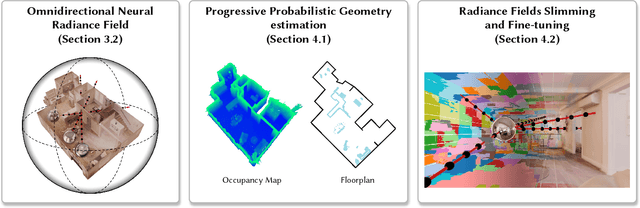
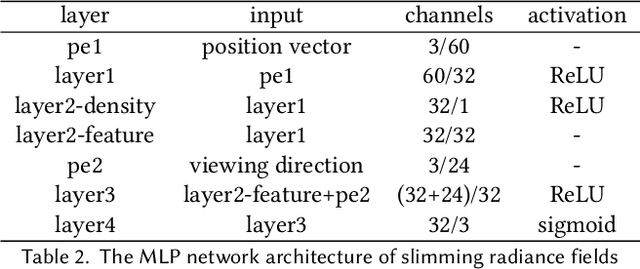
Neural radiance field (NeRF) has recently achieved impressive results in novel view synthesis. However, previous works on NeRF mainly focus on object-centric scenarios. In this work, we propose 360Roam, a novel scene-level NeRF system that can synthesize images of large-scale indoor scenes in real time and support VR roaming. Our system first builds an omnidirectional neural radiance field 360NeRF from multiple input $360^\circ$ images. Using 360NeRF, we then progressively estimate a 3D probabilistic occupancy map which represents the scene geometry in the form of spacial density. Skipping empty spaces and upsampling occupied voxels essentially allows us to accelerate volume rendering by using 360NeRF in a geometry-aware fashion. Furthermore, we use an adaptive divide-and-conquer strategy to slim and fine-tune the radiance fields for further improvement. The floorplan of the scene extracted from the occupancy map can provide guidance for ray sampling and facilitate a realistic roaming experience. To show the efficacy of our system, we collect a $360^\circ$ image dataset in a large variety of scenes and conduct extensive experiments. Quantitative and qualitative comparisons among baselines illustrated our predominant performance in novel view synthesis for complex indoor scenes.
Look Beyond Bias with Entropic Adversarial Data Augmentation
Jan 10, 2023
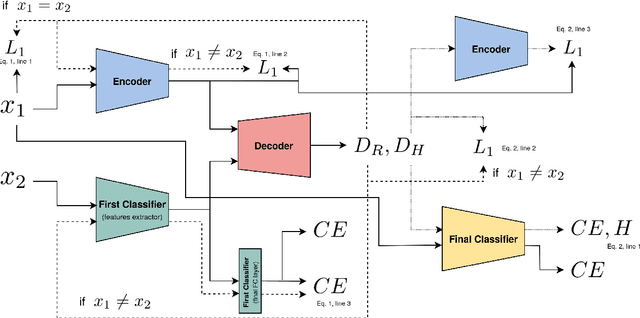

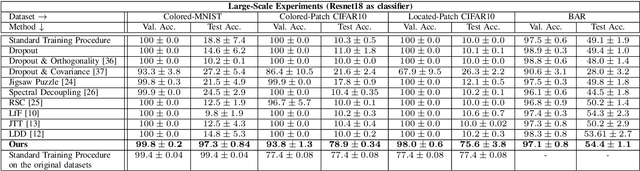
Deep neural networks do not discriminate between spurious and causal patterns, and will only learn the most predictive ones while ignoring the others. This shortcut learning behaviour is detrimental to a network's ability to generalize to an unknown test-time distribution in which the spurious correlations do not hold anymore. Debiasing methods were developed to make networks robust to such spurious biases but require to know in advance if a dataset is biased and make heavy use of minority counterexamples that do not display the majority bias of their class. In this paper, we argue that such samples should not be necessarily needed because the ''hidden'' causal information is often also contained in biased images. To study this idea, we propose 3 publicly released synthetic classification benchmarks, exhibiting predictive classification shortcuts, each of a different and challenging nature, without any minority samples acting as counterexamples. First, we investigate the effectiveness of several state-of-the-art strategies on our benchmarks and show that they do not yield satisfying results on them. Then, we propose an architecture able to succeed on our benchmarks, despite their unusual properties, using an entropic adversarial data augmentation training scheme. An encoder-decoder architecture is tasked to produce images that are not recognized by a classifier, by maximizing the conditional entropy of its outputs, and keep as much as possible of the initial content. A precise control of the information destroyed, via a disentangling process, enables us to remove the shortcut and leave everything else intact. Furthermore, results competitive with the state-of-the-art on the BAR dataset ensure the applicability of our method in real-life situations.
Language Models sounds the Death Knell of Knowledge Graphs
Jan 10, 2023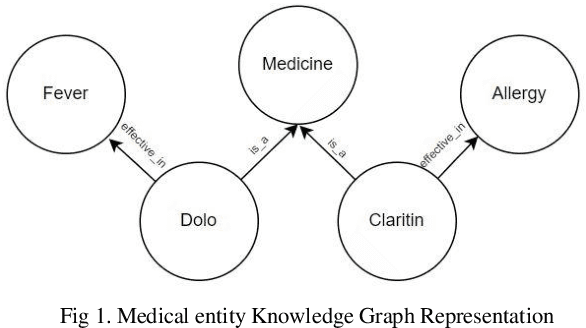
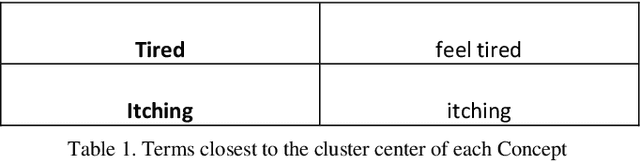
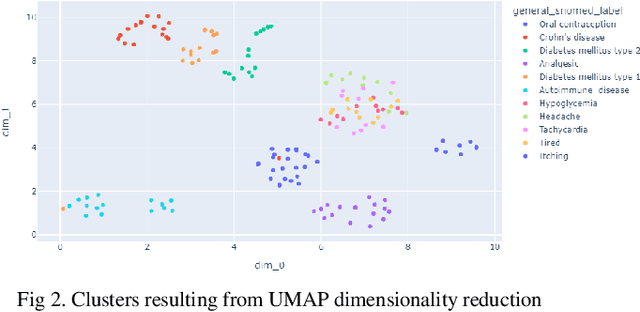
Healthcare domain generates a lot of unstructured and semi-structured text. Natural Language processing (NLP) has been used extensively to process this data. Deep Learning based NLP especially Large Language Models (LLMs) such as BERT have found broad acceptance and are used extensively for many applications. A Language Model is a probability distribution over a word sequence. Self-supervised Learning on a large corpus of data automatically generates deep learning-based language models. BioBERT and Med-BERT are language models pre-trained for the healthcare domain. Healthcare uses typical NLP tasks such as question answering, information extraction, named entity recognition, and search to simplify and improve processes. However, to ensure robust application of the results, NLP practitioners need to normalize and standardize them. One of the main ways of achieving normalization and standardization is the use of Knowledge Graphs. A Knowledge Graph captures concepts and their relationships for a specific domain, but their creation is time-consuming and requires manual intervention from domain experts, which can prove expensive. SNOMED CT (Systematized Nomenclature of Medicine -- Clinical Terms), Unified Medical Language System (UMLS), and Gene Ontology (GO) are popular ontologies from the healthcare domain. SNOMED CT and UMLS capture concepts such as disease, symptoms and diagnosis and GO is the world's largest source of information on the functions of genes. Healthcare has been dealing with an explosion in information about different types of drugs, diseases, and procedures. This paper argues that using Knowledge Graphs is not the best solution for solving problems in this domain. We present experiments using LLMs for the healthcare domain to demonstrate that language models provide the same functionality as knowledge graphs, thereby making knowledge graphs redundant.
Iterative regularization in classification via hinge loss diagonal descent
Dec 24, 2022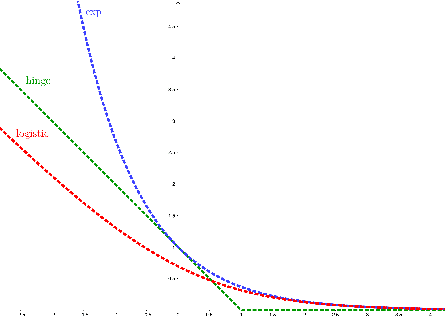
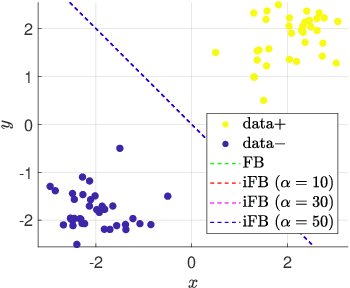
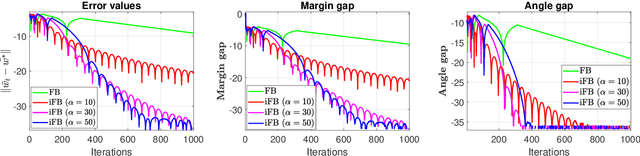
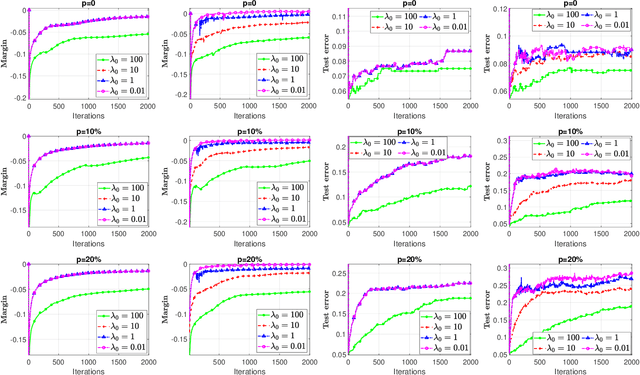
Iterative regularization is a classic idea in regularization theory, that has recently become popular in machine learning. On the one hand, it allows to design efficient algorithms controlling at the same time numerical and statistical accuracy. On the other hand it allows to shed light on the learning curves observed while training neural networks. In this paper, we focus on iterative regularization in the context of classification. After contrasting this setting with that of regression and inverse problems, we develop an iterative regularization approach based on the use of the hinge loss function. More precisely we consider a diagonal approach for a family of algorithms for which we prove convergence as well as rates of convergence. Our approach compares favorably with other alternatives, as confirmed also in numerical simulations.
Back to the Source: Diffusion-Driven Test-Time Adaptation
Jul 07, 2022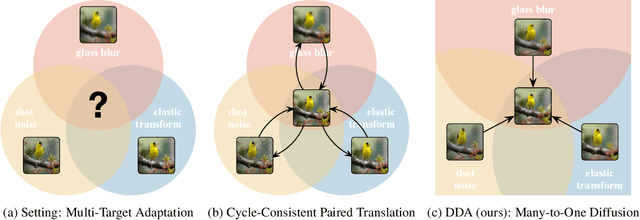

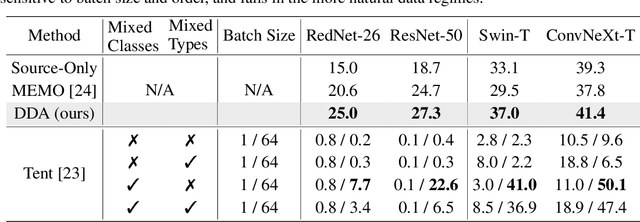
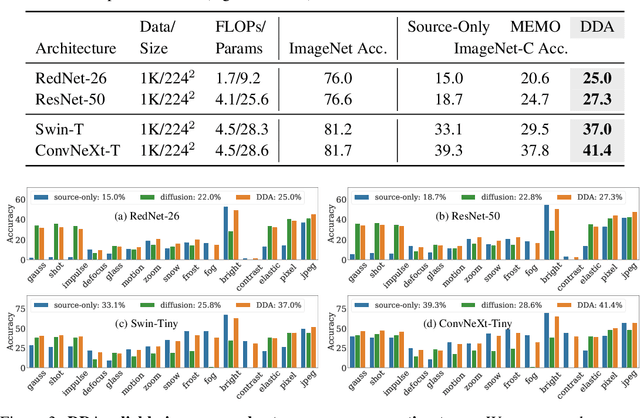
Test-time adaptation harnesses test inputs to improve the accuracy of a model trained on source data when tested on shifted target data. Existing methods update the source model by (re-)training on each target domain. While effective, re-training is sensitive to the amount and order of the data and the hyperparameters for optimization. We instead update the target data, by projecting all test inputs toward the source domain with a generative diffusion model. Our diffusion-driven adaptation method, DDA, shares its models for classification and generation across all domains. Both models are trained on the source domain, then fixed during testing. We augment diffusion with image guidance and self-ensembling to automatically decide how much to adapt. Input adaptation by DDA is more robust than prior model adaptation approaches across a variety of corruptions, architectures, and data regimes on the ImageNet-C benchmark. With its input-wise updates, DDA succeeds where model adaptation degrades on too little data in small batches, dependent data in non-uniform order, or mixed data with multiple corruptions.
A Novel Exploitative and Explorative GWO-SVM Algorithm for Smart Emotion Recognition
Jan 05, 2023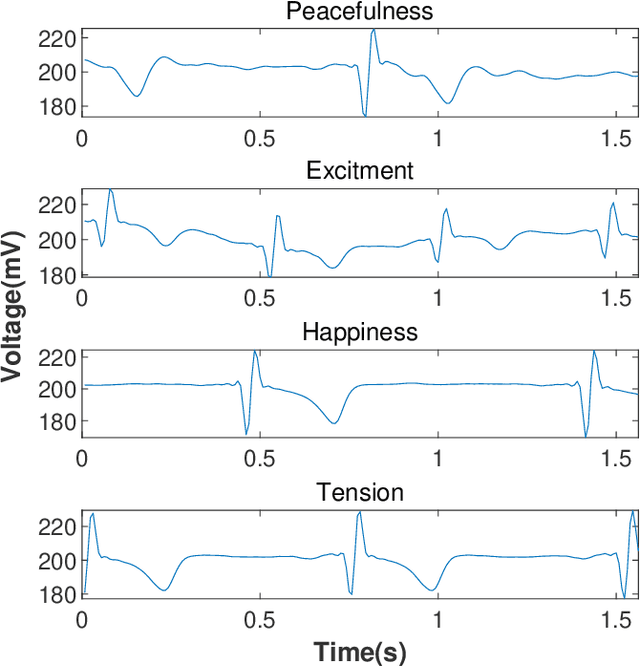
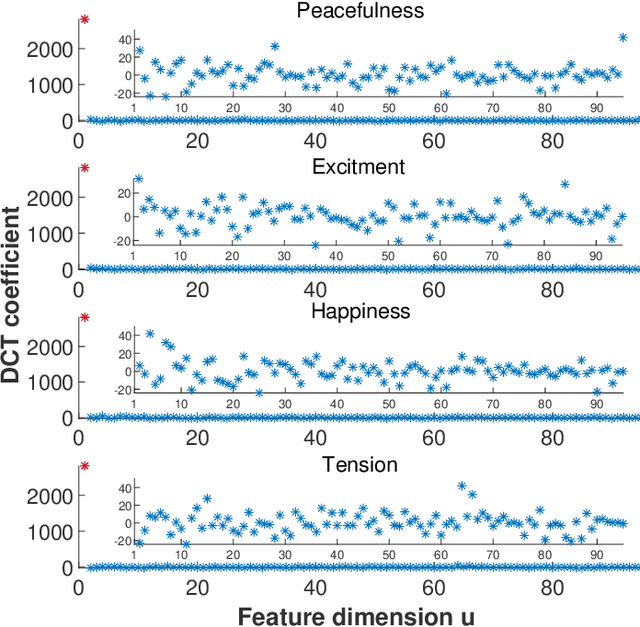
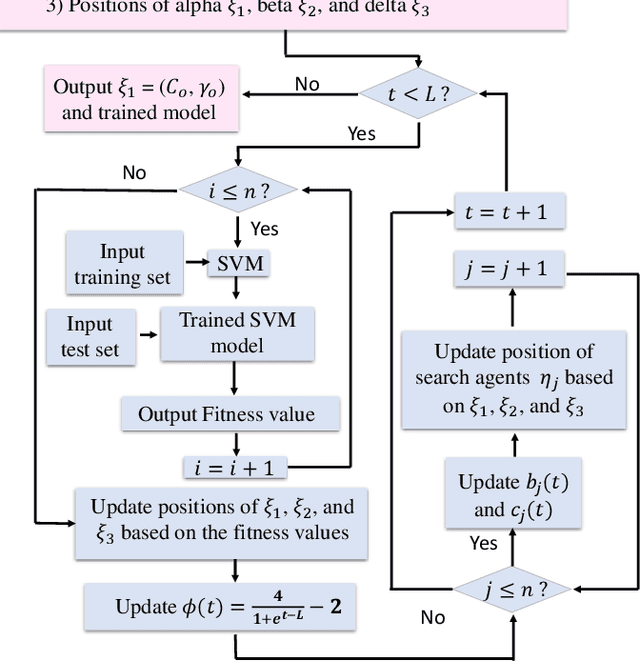
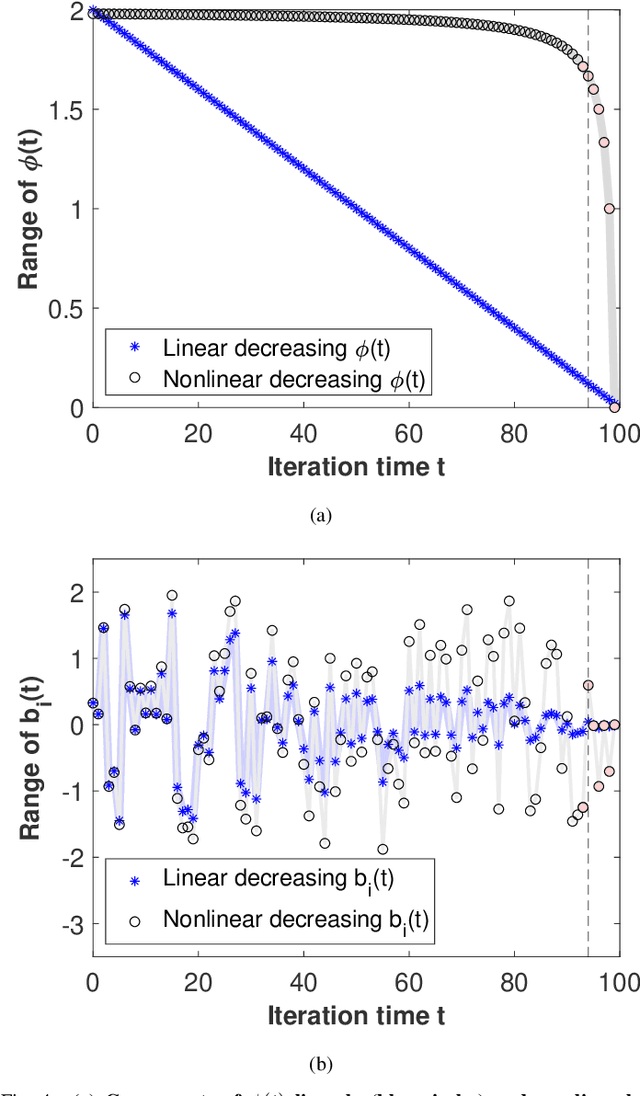
Emotion recognition or detection is broadly utilized in patient-doctor interactions for diseases such as schizophrenia and autism and the most typical techniques are speech detection and facial recognition. However, features extracted from these behavior-based emotion recognitions are not reliable since humans can disguise their emotions. Recording voices or tracking facial expressions for a long term is also not efficient. Therefore, our aim is to find a reliable and efficient emotion recognition scheme, which can be used for non-behavior-based emotion recognition in real-time. This can be solved by implementing a single-channel electrocardiogram (ECG) based emotion recognition scheme in a lightweight embedded system. However, existing schemes have relatively low accuracy. Therefore, we propose a reliable and efficient emotion recognition scheme - exploitative and explorative grey wolf optimizer based SVM (X - GWO - SVM) for ECG-based emotion recognition. Two datasets, one raw self-collected iRealcare dataset, and the widely-used benchmark WESAD dataset are used in the X - GWO - SVM algorithm for emotion recognition. This work demonstrates that the X - GWO - SVM algorithm can be used for emotion recognition and the algorithm exhibits superior performance in reliability compared to the use of other supervised machine learning methods in earlier works. It can be implemented in a lightweight embedded system, which is much more efficient than existing solutions based on deep neural networks.
Estimation of binary time-frequency masks from ambient noise
May 20, 2022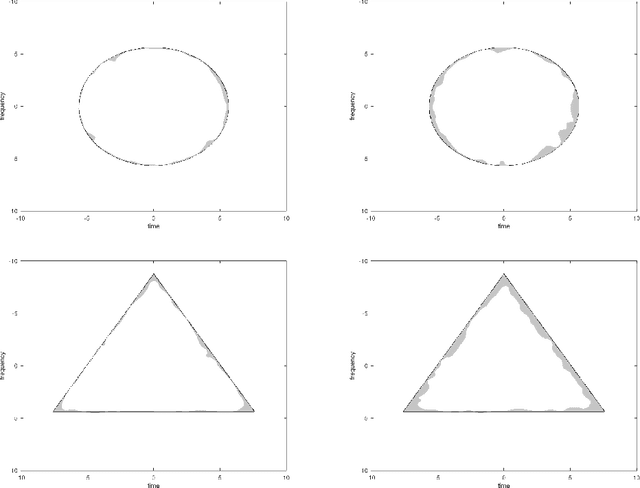
We investigate the retrieval of a binary time-frequency mask from a few observations of filtered white ambient noise. Confirming household wisdom in acoustic modeling, we show that this is possible by inspecting the average spectrogram of ambient noise. Specifically, we show that the lower quantile of the average of $\mathcal{O}(\log(|\Omega|/\varepsilon))$ masked spectrograms is enough to identify a rather general mask $\Omega$ with confidence at least $\varepsilon$, up to shape details concentrated near the boundary of $\Omega$. As an application, the expected measure of the estimation error is dominated by the perimeter of the time-frequency mask. The estimator requires no knowledge of the noise variance, and only a very qualitative profile of the filtering window, but no exact knowledge of it.