 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-vehicle Dynamic Water Surface Monitoring
Feb 23, 2023

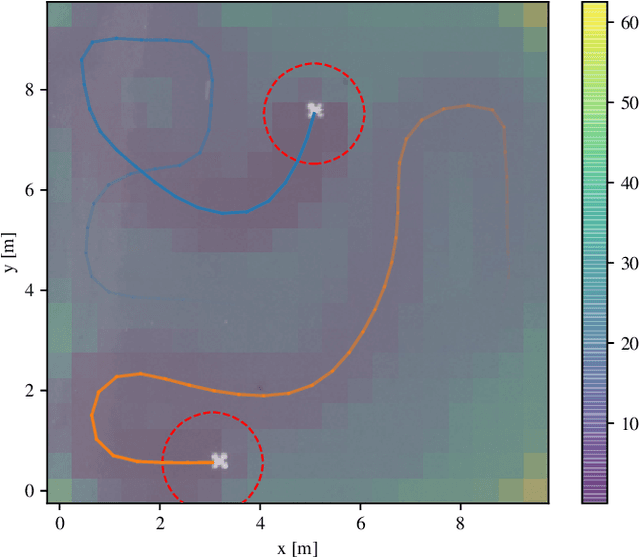

Repeated exploration of a water surface to detect objects of interest and their subsequent monitoring is important in search-and-rescue or ocean clean-up operations. Since the location of any detected object is dynamic, we propose to address the combined surface exploration and monitoring of the detected objects by modeling spatio-temporal reward states and coordinating a team of vehicles to collect the rewards. The model characterizes the dynamics of the water surface and enables the planner to predict future system states. The state reward value relevant to the particular water surface cell increases over time and is nullified by being in a sensor range of a vehicle. Thus, the proposed multi-vehicle planning approach is to minimize the collective value of the dynamic model reward states. The purpose is to address vehicles' motion constraints by using model predictive control on receding horizon, thus fully exploiting the utilized vehicles' motion capabilities. Based on the evaluation results, the approach indicates improvement in a solution to the kinematic orienteering problem and the team orienteering problem in the monitoring task compared to the existing solutions. The proposed approach has been experimentally verified, supporting its feasibility in real-world monitoring tasks.
Solving differential equations using physics informed deep learning: a hand-on tutorial with benchmark tests
Feb 23, 2023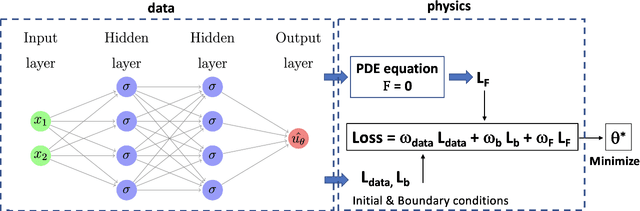
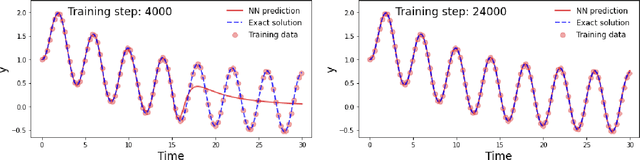

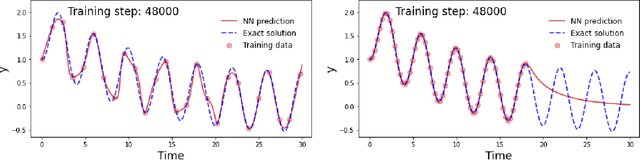
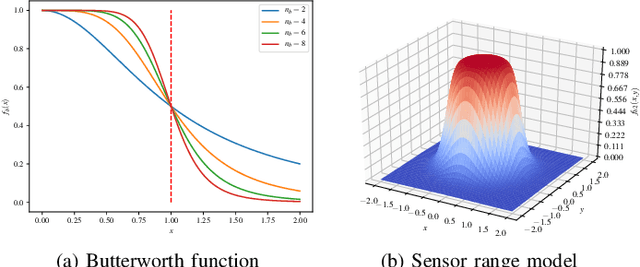
We revisit the original approach of using deep learning and neural networks to solve differential equations by incorporating the knowledge of the equation. This is done by adding a dedicated term to the loss function during the optimization procedure in the training process. The so-called physics-informed neural networks (PINNs) are tested on a variety of academic ordinary differential equations in order to highlight the benefits and drawbacks of this approach with respect to standard integration methods. We focus on the possibility to use the least possible amount of data into the training process. The principles of PINNs for solving differential equations by enforcing physical laws via penalizing terms are reviewed. A tutorial on a simple equation model illustrates how to put into practice the method for ordinary differential equations. Benchmark tests show that a very small amount of training data is sufficient to predict the solution when the non linearity of the problem is weak. However, this is not the case in strongly non linear problems where a priori knowledge of training data over some partial or the whole time integration interval is necessary.
A comparative assessment of deep learning models for day-ahead load forecasting: Investigating key accuracy drivers
Feb 23, 2023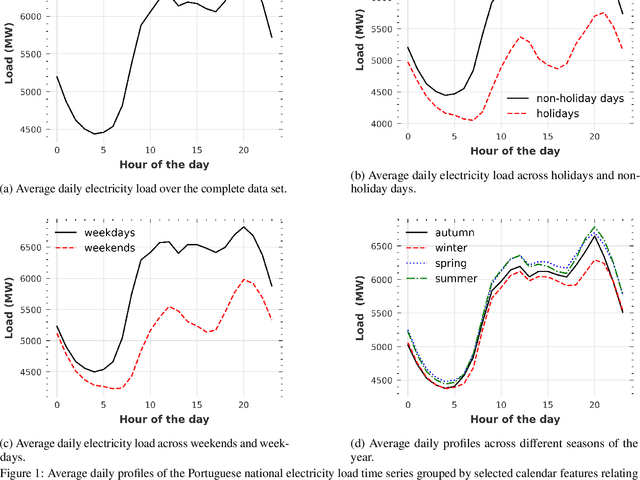
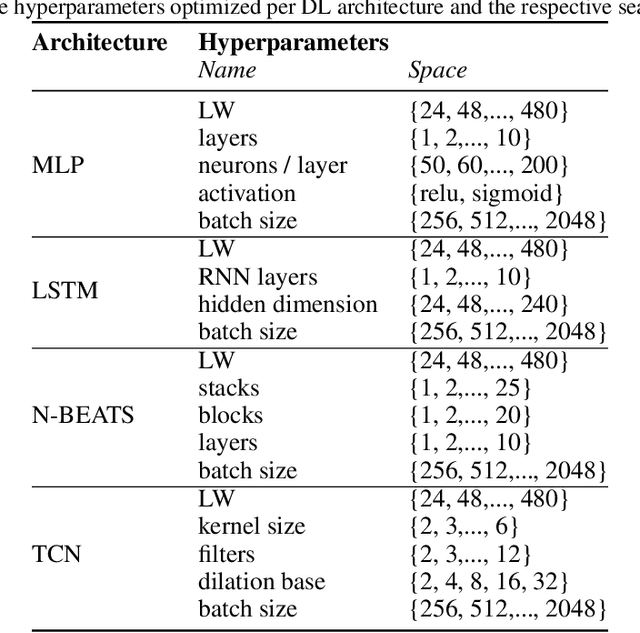
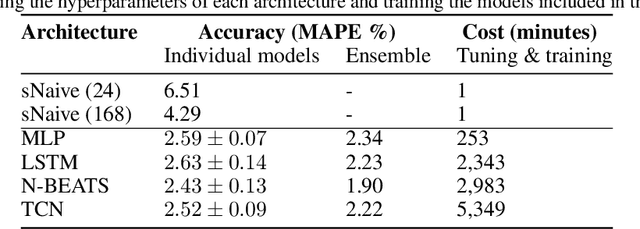
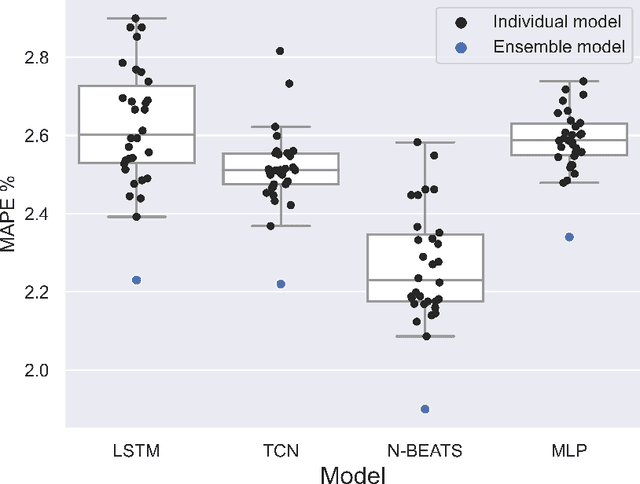
Short-term load forecasting (STLF) is vital for the daily operation of power grids. However, the non-linearity, non-stationarity, and randomness characterizing electricity demand time series renders STLF a challenging task. To that end, different forecasting methods have been proposed in the literature for day-ahead load forecasting, including a variety of deep learning models that are currently considered to achieve state-of-the-art performance. In order to compare the accuracy of such models, we focus on national net aggregated STLF and examine well-established autoregressive neural networks of indicative architectures, namely multi-layer perceptrons, N-BEATS, long short-term memory neural networks, and temporal convolutional networks, for the case of Portugal. To investigate the factors that affect the performance of each model and identify the most appropriate per case, we also conduct a post-hoc analysis, correlating forecast errors with key calendar and weather features. Our results indicate that N-BEATS consistently outperforms the rest of the examined deep learning models. Additionally, we find that external factors can significantly impact accuracy, affecting both the actual and relative performance of the models.
Learning to Manipulate a Commitment Optimizer
Feb 23, 2023


It is shown in recent studies that in a Stackelberg game the follower can manipulate the leader by deviating from their true best-response behavior. Such manipulations are computationally tractable and can be highly beneficial for the follower. Meanwhile, they may result in significant payoff losses for the leader, sometimes completely defeating their first-mover advantage. A warning to commitment optimizers, the risk these findings indicate appears to be alleviated to some extent by a strict information advantage the manipulations rely on. That is, the follower knows the full information about both players' payoffs whereas the leader only knows their own payoffs. In this paper, we study the manipulation problem with this information advantage relaxed. We consider the scenario where the follower is not given any information about the leader's payoffs to begin with but has to learn to manipulate by interacting with the leader. The follower can gather necessary information by querying the leader's optimal commitments against contrived best-response behaviors. Our results indicate that the information advantage is not entirely indispensable to the follower's manipulations: the follower can learn the optimal way to manipulate in polynomial time with polynomially many queries of the leader's optimal commitment.
Access-based Lightweight Physical Layer Authentication for the Internet of Things Devices
Mar 01, 2023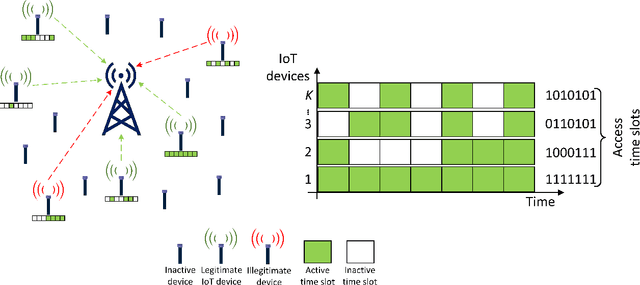
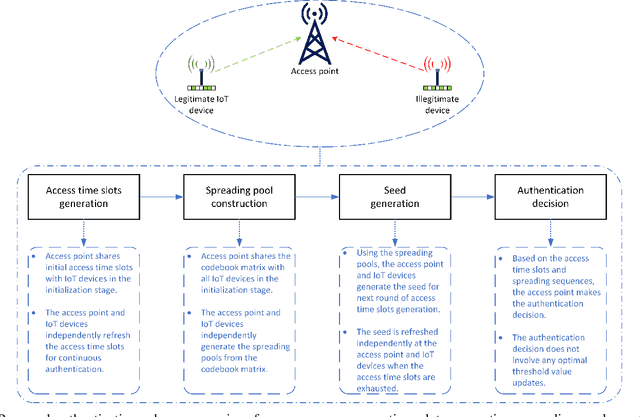
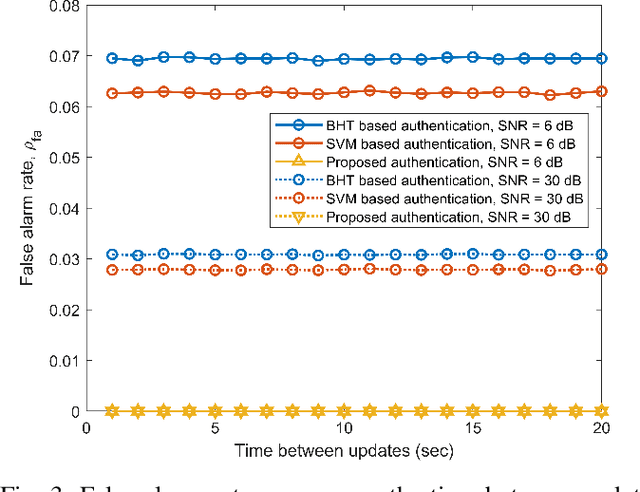
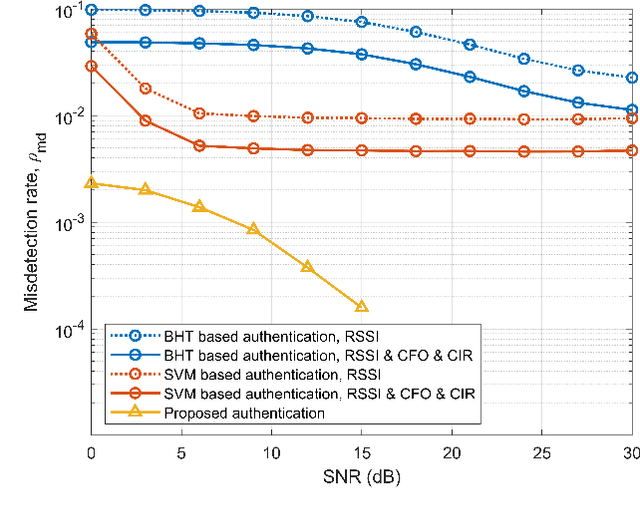
Physical-layer authentication is a popular alternative to the conventional key-based authentication for internet of things (IoT) devices due to their limited computational capacity and battery power. However, this approach has limitations due to poor robustness under channel fluctuations, reconciliation overhead, and no clear safeguard distance to ensure the secrecy of the generated authentication keys. In this regard, we propose a novel, secure, and lightweight continuous authentication scheme for IoT device authentication. Our scheme utilizes the inherent properties of the IoT devices transmission model as its source for seed generation and device authentication. Specifically, our proposed scheme provides continuous authentication by checking the access time slots and spreading sequences of the IoT devices instead of repeatedly generating and verifying shared keys. Due to this, access to a coherent key is not required in our proposed scheme, resulting in the concealment of the seed information from attackers. Our proposed authentication scheme for IoT devices demonstrates improved performance compared to the benchmark schemes relying on physical-channel. Our empirical results find a near threefold decrease in misdetection rate of illegitimate devices and close to zero false alarm rate in various system settings with varied numbers of active devices up to 200 and signal-to-noise ratio from 0 dB to 30 dB. Our proposed authentication scheme also has a lower computational complexity of at least half the computational cost of the benchmark schemes based on support vector machine and binary hypothesis testing in our studies. This further corroborates the practicality of our scheme for IoT deployments.
A Hybrid Genetic Algorithm with Type-Aware Chromosomes for Traveling Salesman Problems with Drone
Mar 01, 2023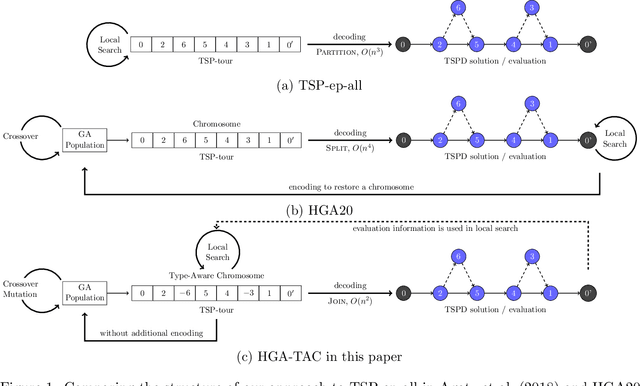
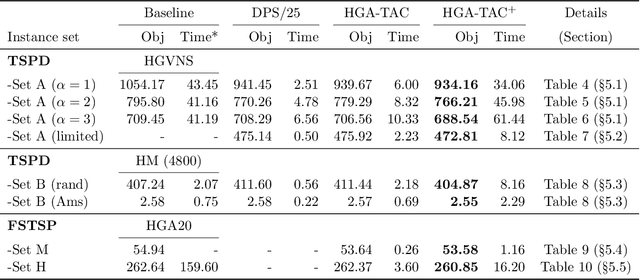
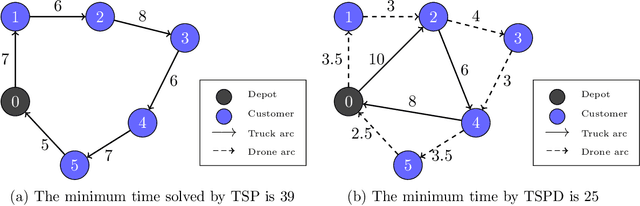
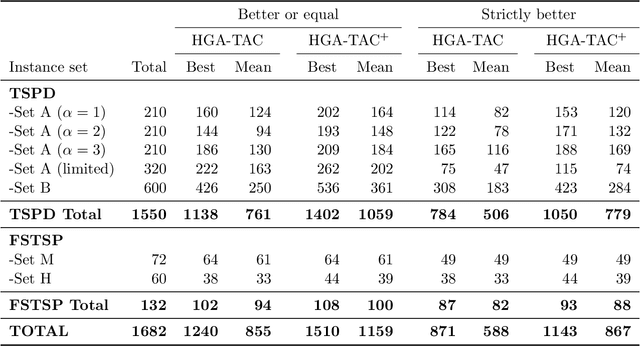
There are emerging transportation problems known as the Traveling Salesman Problem with Drone (TSPD) and the Flying Sidekick Traveling Salesman Problem (FSTSP) that involve the use of a drone in conjunction with a truck for package delivery. This study represents a hybrid genetic algorithm for solving TSPD and FSTSP by combining local search methods and dynamic programming. Similar algorithms exist in the literature. Our algorithm, however, considers more sophisticated chromosomes and simpler dynamic programming to enable broader exploration by the genetic algorithm and efficient exploitation through dynamic programming and local searches. The key contribution of this paper is the discovery of how decision-making processes should be divided among the layers of genetic algorithm, dynamic programming, and local search. In particular, our genetic algorithm generates the truck and the drone sequences separately and encodes them in a type-aware chromosome, wherein each customer is assigned to either the truck or the drone. We apply local searches to each chromosome, which is decoded by dynamic programming for fitness evaluation. Our dynamic programming algorithm merges the two sequences by determining optimal launch and landing locations for the drone to construct a TSPD solution represented by the chromosome. We propose novel type-aware order crossover operations and effective local search methods. A strategy to escape from local optima is proposed. Our new algorithm is shown to outperform existing algorithms on most benchmark instances in both quality and time. Our algorithms found the new best solutions for 538 TSPD instances out of 920 and 93 FSTSP instances out of 132.
Train What You Know -- Precise Pick-and-Place with Transporter Networks
Feb 17, 2023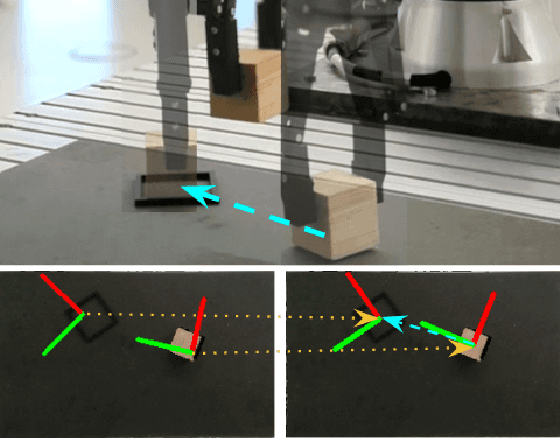
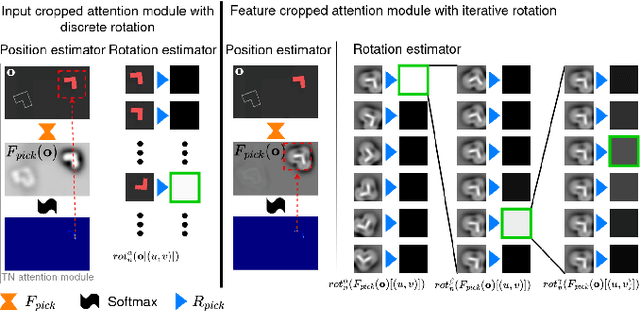
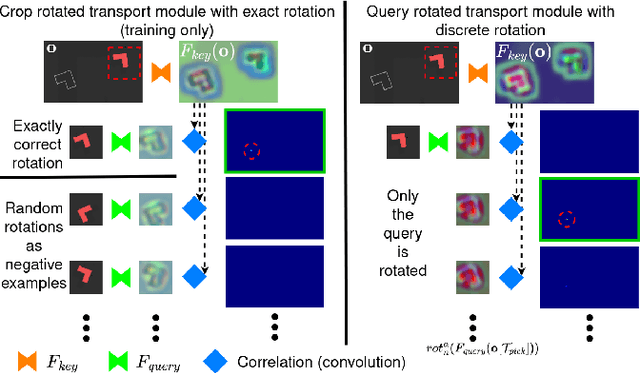
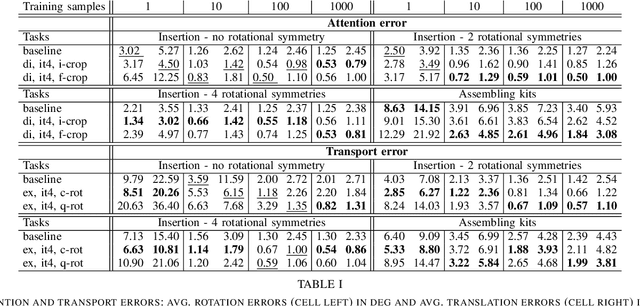
Precise pick-and-place is essential in robotic applications. To this end, we define a novel exact training method and an iterative inference method that improve pick-and-place precision with Transporter Networks. We conduct a large scale experiment on 8 simulated tasks. A systematic analysis shows, that the proposed modifications have a significant positive effect on model performance. Considering picking and placing independently, our methods achieve up to 60% lower rotation and translation errors than baselines. For the whole pick-and-place process we observe 50% lower rotation errors for most tasks with slight improvements in terms of translation errors. Furthermore, we propose architectural changes that retain model performance and reduce computational costs and time. We validate our methods with an interactive teaching procedure on real hardware. Supplementary material will be made available at: https://gergely-soti.github.io/p
Modeling and Forecasting COVID-19 Cases using Latent Subpopulations
Feb 09, 2023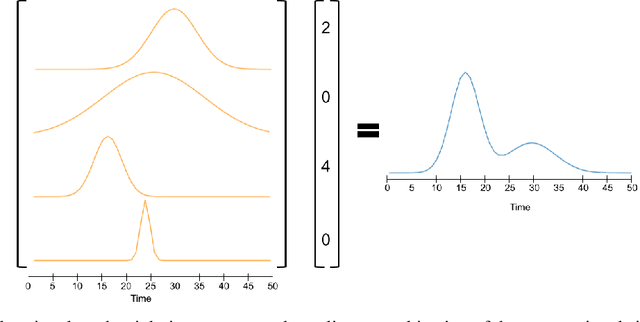
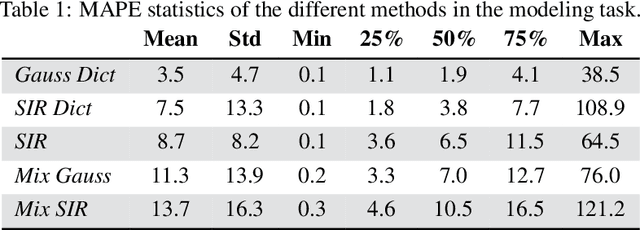
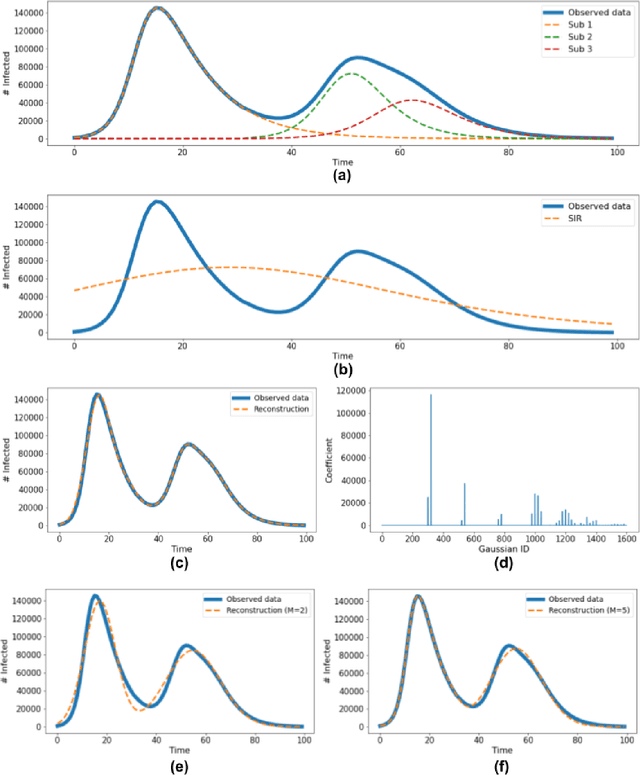
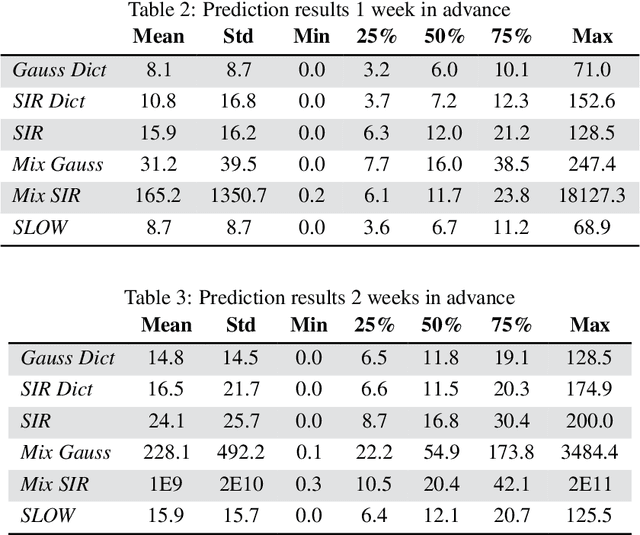
Classical epidemiological models assume homogeneous populations. There have been important extensions to model heterogeneous populations, when the identity of the sub-populations is known, such as age group or geographical location. Here, we propose two new methods to model the number of people infected with COVID-19 over time, each as a linear combination of latent sub-populations -- i.e., when we do not know which person is in which sub-population, and the only available observations are the aggregates across all sub-populations. Method #1 is a dictionary-based approach, which begins with a large number of pre-defined sub-population models (each with its own starting time, shape, etc), then determines the (positive) weight of small (learned) number of sub-populations. Method #2 is a mixture-of-$M$ fittable curves, where $M$, the number of sub-populations to use, is given by the user. Both methods are compatible with any parametric model; here we demonstrate their use with first (a)~Gaussian curves and then (b)~SIR trajectories. We empirically show the performance of the proposed methods, first in (i) modeling the observed data and then in (ii) forecasting the number of infected people 1 to 4 weeks in advance. Across 187 countries, we show that the dictionary approach had the lowest mean absolute percentage error and also the lowest variance when compared with classical SIR models and moreover, it was a strong baseline that outperforms many of the models developed for COVID-19 forecasting.
NeuKron: Constant-Size Lossy Compression of Sparse Reorderable Matrices and Tensors
Feb 09, 2023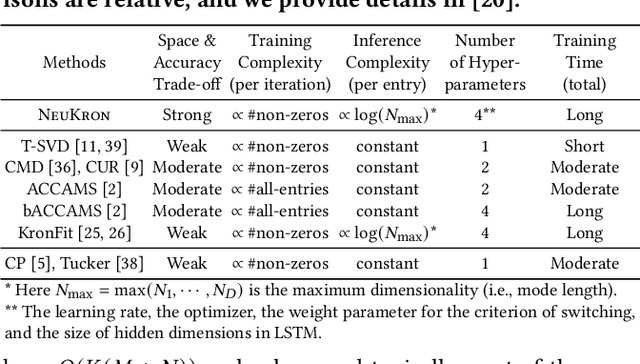
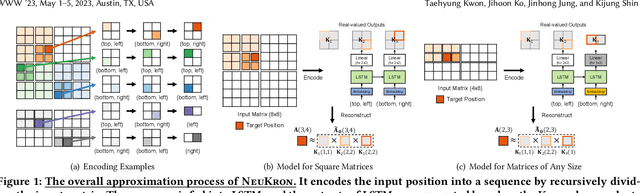
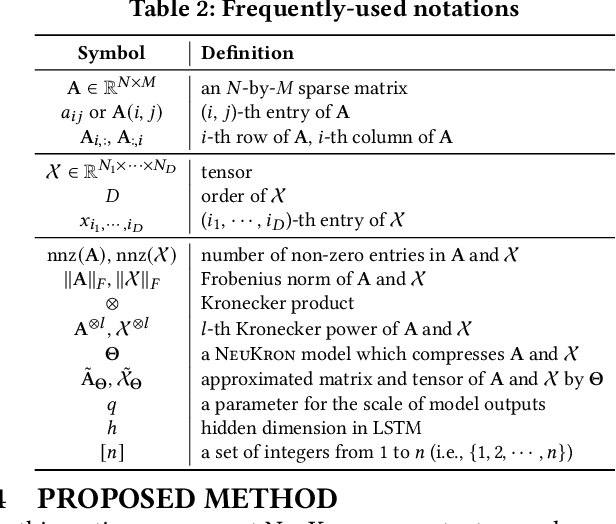
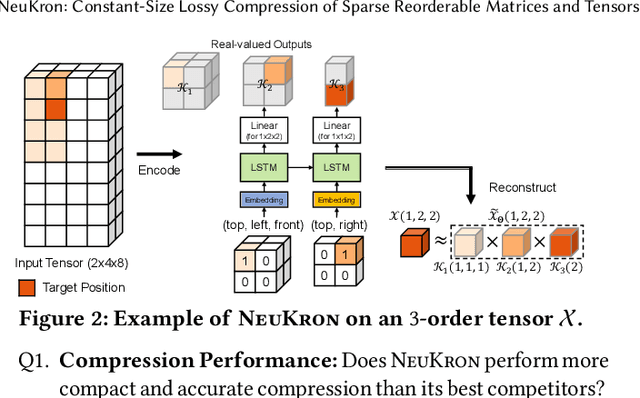
Many real-world data are naturally represented as a sparse reorderable matrix, whose rows and columns can be arbitrarily ordered (e.g., the adjacency matrix of a bipartite graph). Storing a sparse matrix in conventional ways requires an amount of space linear in the number of non-zeros, and lossy compression of sparse matrices (e.g., Truncated SVD) typically requires an amount of space linear in the number of rows and columns. In this work, we propose NeuKron for compressing a sparse reorderable matrix into a constant-size space. NeuKron generalizes Kronecker products using a recurrent neural network with a constant number of parameters. NeuKron updates the parameters so that a given matrix is approximated by the product and reorders the rows and columns of the matrix to facilitate the approximation. The updates take time linear in the number of non-zeros in the input matrix, and the approximation of each entry can be retrieved in logarithmic time. We also extend NeuKron to compress sparse reorderable tensors (e.g. multi-layer graphs), which generalize matrices. Through experiments on ten real-world datasets, we show that NeuKron is (a) Compact: requiring up to five orders of magnitude less space than its best competitor with similar approximation errors, (b) Accurate: giving up to 10x smaller approximation error than its best competitors with similar size outputs, and (c) Scalable: successfully compressing a matrix with over 230 million non-zero entries.
Bi-Phase Enhanced IVFPQ for Time-Efficient Ad-hoc Retrieval
Oct 11, 2022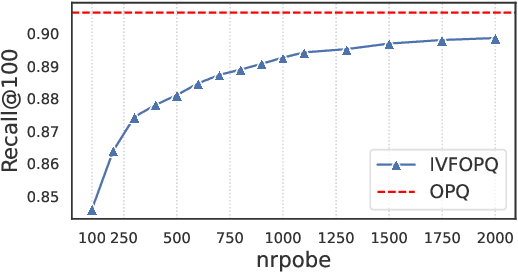
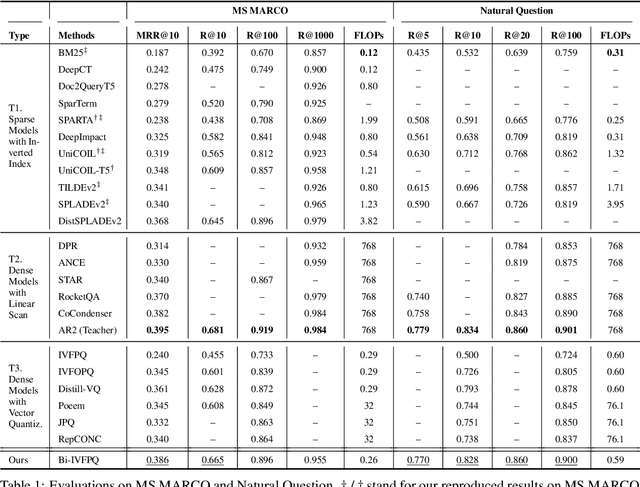
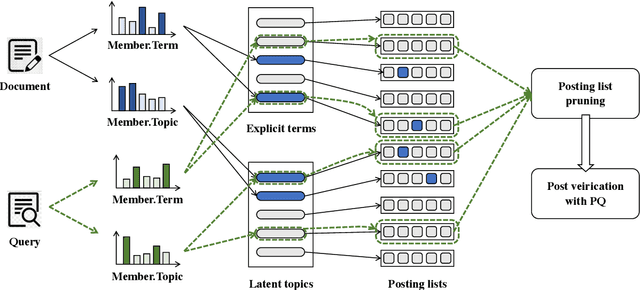
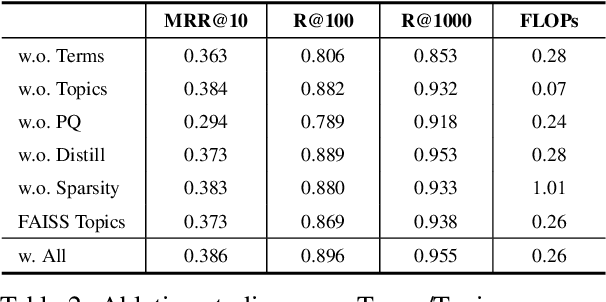
IVFPQ is a popular index paradigm for time-efficient ad-hoc retrieval. Instead of traversing the entire database for relevant documents, it accelerates the retrieval operation by 1) accessing a fraction of the database guided the activation of latent topics in IVF (inverted file system), and 2) approximating the exact relevance measurement based on PQ (product quantization). However, the conventional IVFPQ is limited in retrieval performance due to the coarse granularity of its latent topics. On the one hand, it may result in severe loss of retrieval quality when visiting a small number of topics; on the other hand, it will lead to a huge retrieval cost when visiting a large number of topics. To mitigate the above problem, we propose a novel framework named Bi-Phase IVFPQ. It jointly uses two types of features: the latent topics and the explicit terms, to build the inverted file system. Both types of features are complementary to each other, which helps to achieve better coverage of the relevant documents. Besides, the documents' memberships to different IVF entries are learned by distilling knowledge from deep semantic models, which substantially improves the index quality and retrieval accuracy. We perform comprehensive empirical studies on popular ad-hoc retrieval benchmarks, whose results verify the effectiveness and efficiency of our proposed framework.