 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving End-to-End SLU performance with Prosodic Attention and Distillation
May 14, 2023
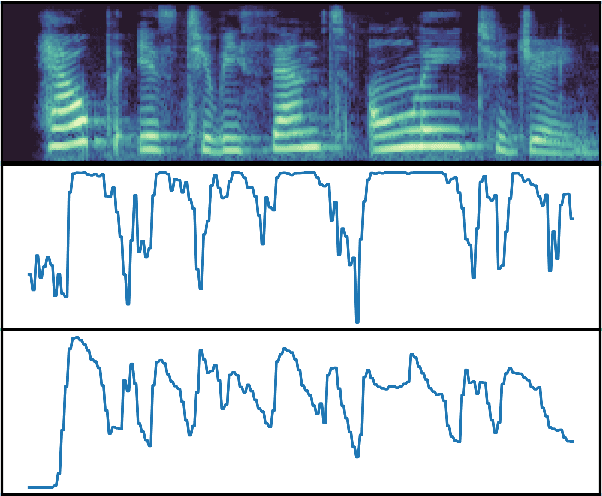
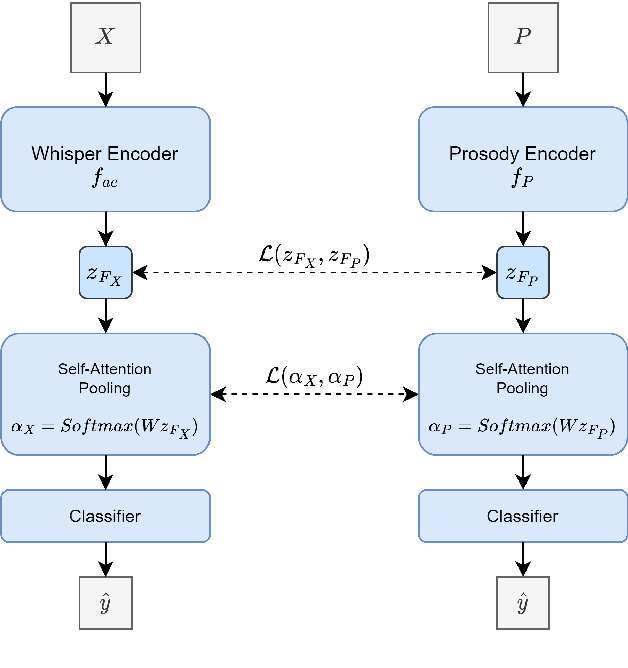
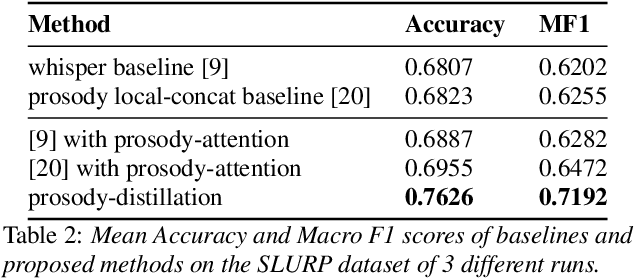
Most End-to-End SLU methods depend on the pretrained ASR or language model features for intent prediction. However, other essential information in speech, such as prosody, is often ignored. Recent research has shown improved results in classifying dialogue acts by incorporating prosodic information. The margins of improvement in these methods are minimal as the neural models ignore prosodic features. In this work, we propose prosody-attention, which uses the prosodic features differently to generate attention maps across time frames of the utterance. Then we propose prosody-distillation to explicitly learn the prosodic information in the acoustic encoder rather than concatenating the implicit prosodic features. Both the proposed methods improve the baseline results, and the prosody-distillation method gives an intent classification accuracy improvement of 8\% and 2\% on SLURP and STOP datasets over the prosody baseline.
Language Model Tokenizers Introduce Unfairness Between Languages
May 17, 2023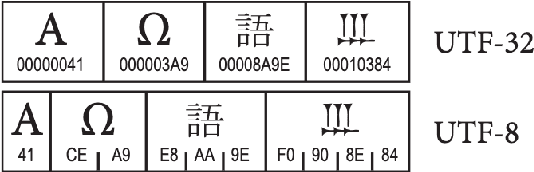
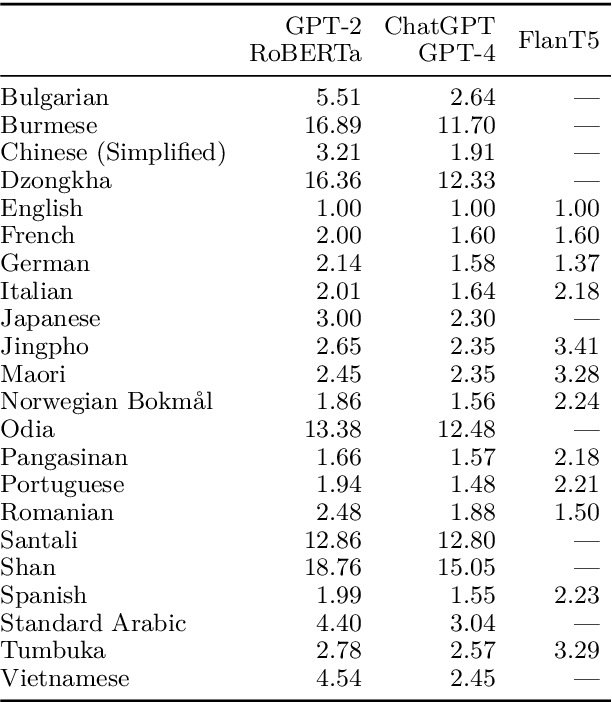
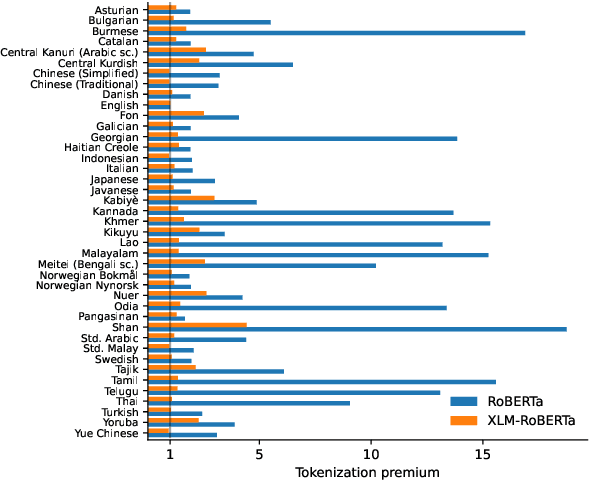
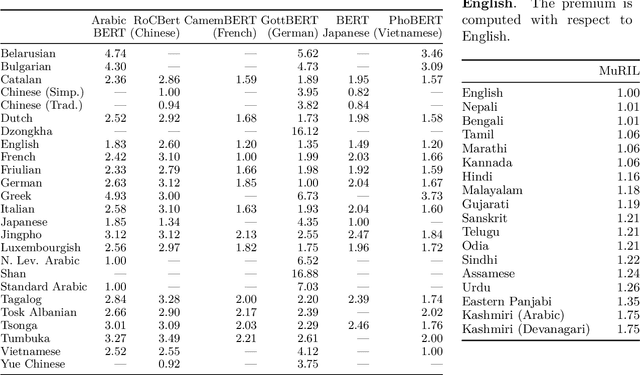
Recent language models have shown impressive multilingual performance, even when not explicitly trained for it. Despite this, concerns have been raised about the quality of their outputs across different languages. In this paper, we show how disparity in the treatment of different languages arises at the tokenization stage, well before a model is even invoked. The same text translated into different languages can have drastically different tokenization lengths, with differences up to 15 times in some cases. These disparities persist across the 17 tokenizers we evaluate, even if they are intentionally trained for multilingual support. Character-level and byte-level models also exhibit over 4 times the difference in the encoding length for some language pairs. This induces unfair treatment for some language communities in regard to the cost of accessing commercial language services, the processing time and latency, as well as the amount of content that can be provided as context to the models. Therefore, we make the case that we should train future language models using multilingually fair tokenizers.
CHMMOTv1 -- Cardiac and Hepatic Multi-Echo (T2*) MRI Images and Clinical Dataset for Iron Overload on Thalassemia Patients
May 17, 2023
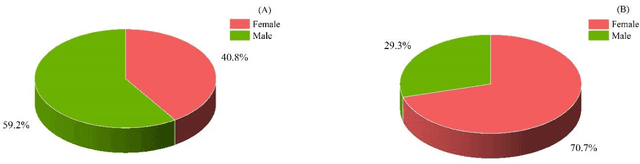
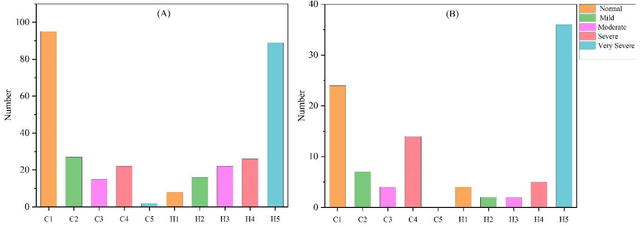
Owing to the invasiveness and low accuracy of other tests, including biopsy and ferritin levels, magnetic resonance imaging (T2 and T2*-MRI) has been considered the standard test for patients with thalassemia (THM). Regarding deep learning networks in medical sciences for improving diagnosis and treatment purposes and the existence of minimal resources for them, we decided to provide a set of magnetic resonance images of the cardiac and hepatic organs. The dataset included 124 patients (67 women and 57 men) with a THM age range of (5-52) years. In addition, patients were divided into two groups: with follow-up (1-5 times) at time intervals of about (5-6) months and without follow-up. Also, T2* and, R2* values, the results of the cardiac and hepatic report (normal, mild, moderate, severe, and very severe), and laboratory tests including Ferritin, Bilirubin (D, and T), AST, ALT, and ALP levels were provided as an Excel file. This dataset CHMMOTv1) has been published in Mendeley Dataverse and is accessible through the web at: http://databiox.com.
Linear Query Approximation Algorithms for Non-monotone Submodular Maximization under Knapsack Constraint
May 17, 2023
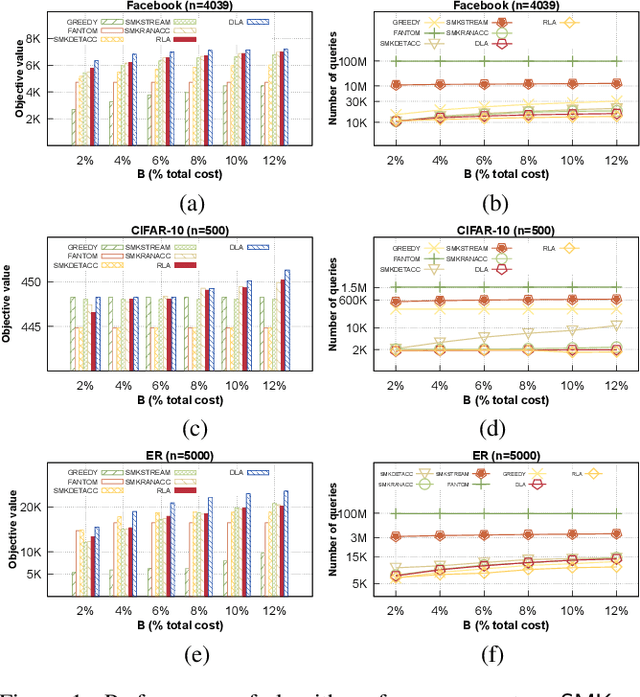
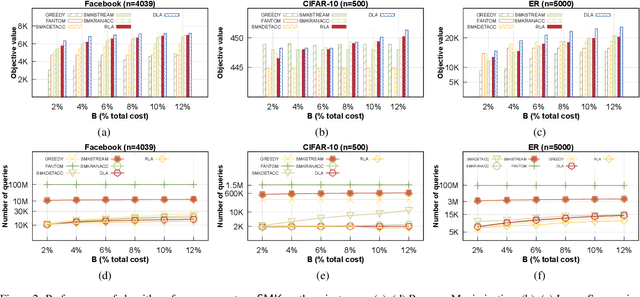
This work, for the first time, introduces two constant factor approximation algorithms with linear query complexity for non-monotone submodular maximization over a ground set of size $n$ subject to a knapsack constraint, $\mathsf{DLA}$ and $\mathsf{RLA}$. $\mathsf{DLA}$ is a deterministic algorithm that provides an approximation factor of $6+\epsilon$ while $\mathsf{RLA}$ is a randomized algorithm with an approximation factor of $4+\epsilon$. Both run in $O(n \log(1/\epsilon)/\epsilon)$ query complexity. The key idea to obtain a constant approximation ratio with linear query lies in: (1) dividing the ground set into two appropriate subsets to find the near-optimal solution over these subsets with linear queries, and (2) combining a threshold greedy with properties of two disjoint sets or a random selection process to improve solution quality. In addition to the theoretical analysis, we have evaluated our proposed solutions with three applications: Revenue Maximization, Image Summarization, and Maximum Weighted Cut, showing that our algorithms not only return comparative results to state-of-the-art algorithms but also require significantly fewer queries.
Digital Twin for Non-Terrestrial Networks: Vision, Challenges, and Enabling Technologies
May 17, 2023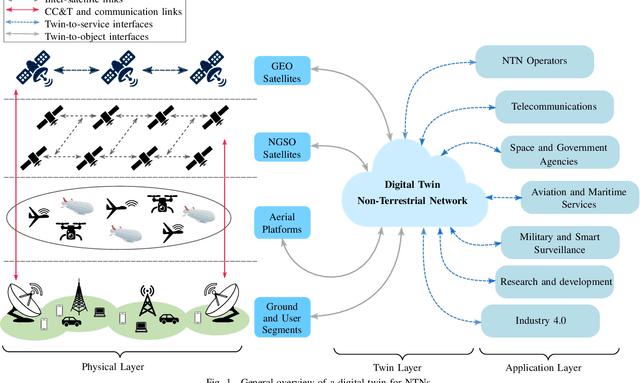
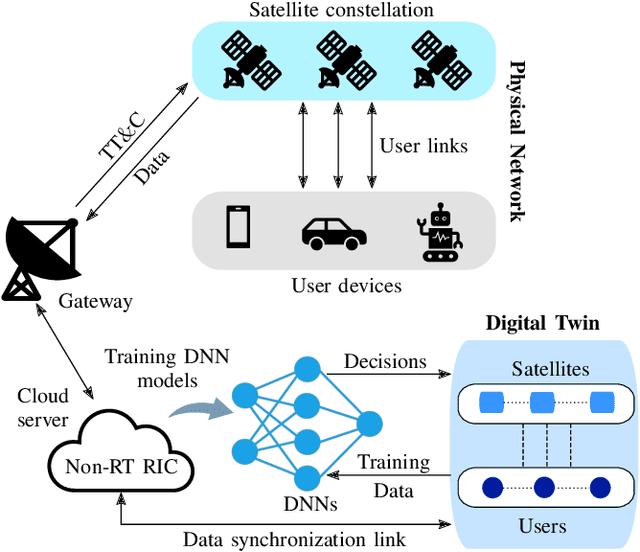
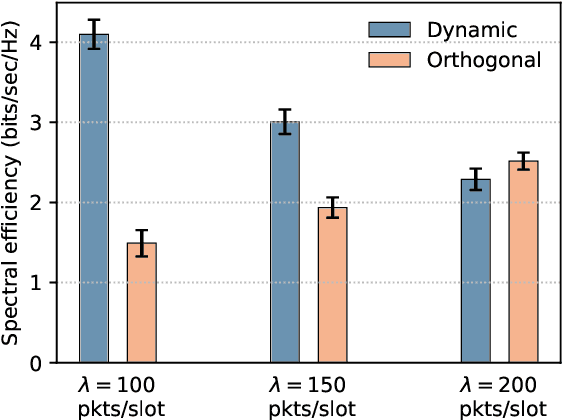
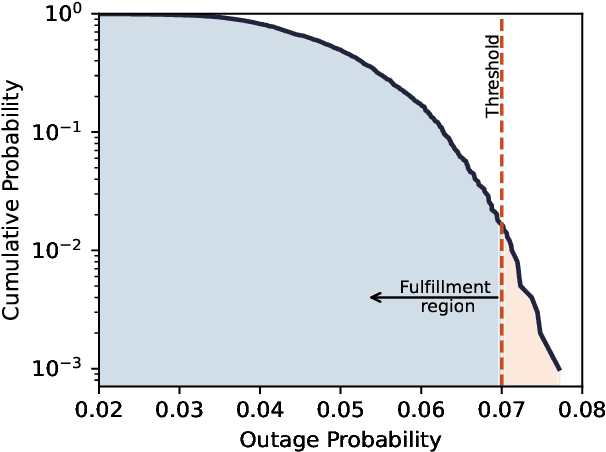
The ongoing digital transformation has sparked the emergence of various new network applications that demand cutting-edge technologies to enhance their efficiency and functionality. One of the promising technologies in this direction is the digital twin, which is a new approach to design and manage complicated cyber-physical systems with a high degree of automation, intelligence, and resilience. This article discusses the use of digital twin technology as a new approach for modeling non-terrestrial networks (NTNs). Digital twin technology can create accurate data-driven NTN models that operate in real-time, allowing for rapid testing and deployment of new NTN technologies and services, besides facilitating innovation and cost reduction. Specifically, we provide a vision on integrating the digital twin into NTNs and explore the primary deployment challenges, as well as the key potential enabling technologies within NTN realm. In closing, we present a case study that employs a data-driven digital twin model for dynamic and service-oriented network slicing within an open radio access network (O-RAN) NTN architecture.
Predicting Side Effect of Drug Molecules using Recurrent Neural Networks
May 17, 2023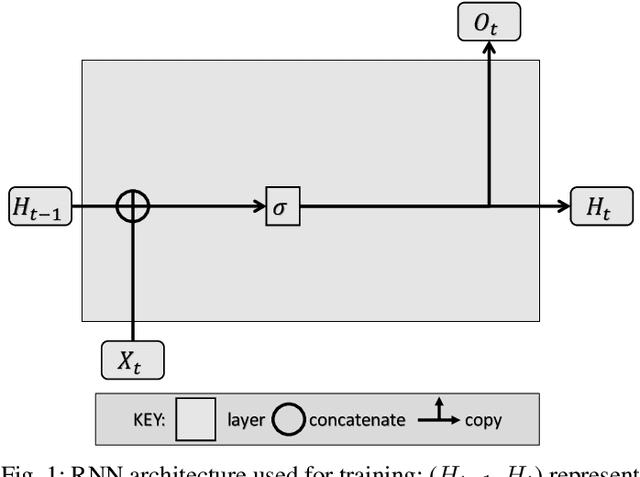
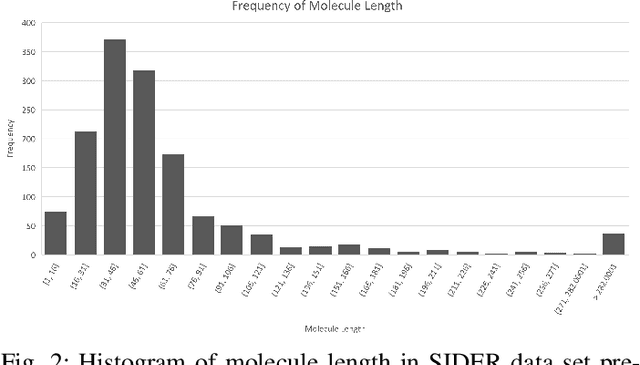
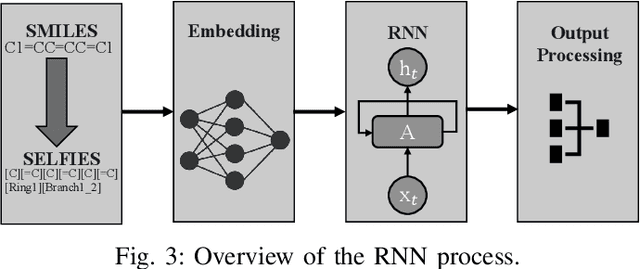
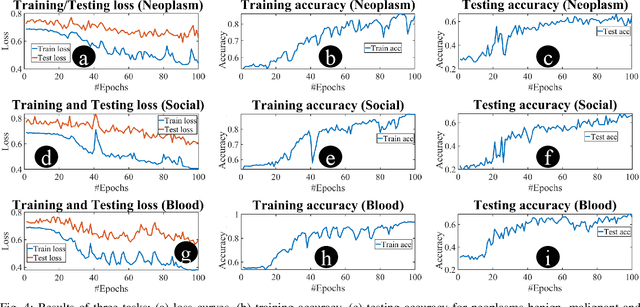
Identification and verification of molecular properties such as side effects is one of the most important and time-consuming steps in the process of molecule synthesis. For example, failure to identify side effects before submission to regulatory groups can cost millions of dollars and months of additional research to the companies. Failure to identify side effects during the regulatory review can also cost lives. The complexity and expense of this task have made it a candidate for a machine learning-based solution. Prior approaches rely on complex model designs and excessive parameter counts for side effect predictions. We believe reliance on complex models only shifts the difficulty away from chemists rather than alleviating the issue. Implementing large models is also expensive without prior access to high-performance computers. We propose a heuristic approach that allows for the utilization of simple neural networks, specifically the recurrent neural network, with a 98+% reduction in the number of required parameters compared to available large language models while still obtaining near identical results as top-performing models.
Mitigating Group Bias in Federated Learning: Beyond Local Fairness
May 17, 2023

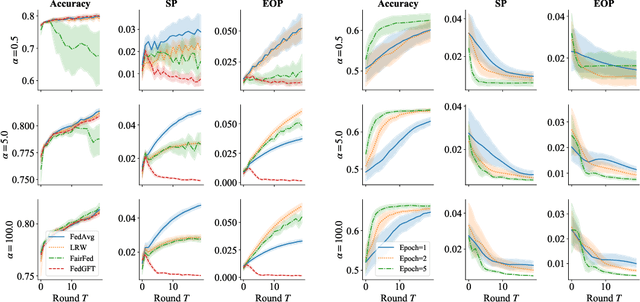
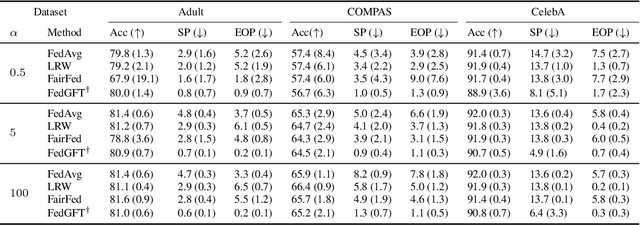
The issue of group fairness in machine learning models, where certain sub-populations or groups are favored over others, has been recognized for some time. While many mitigation strategies have been proposed in centralized learning, many of these methods are not directly applicable in federated learning, where data is privately stored on multiple clients. To address this, many proposals try to mitigate bias at the level of clients before aggregation, which we call locally fair training. However, the effectiveness of these approaches is not well understood. In this work, we investigate the theoretical foundation of locally fair training by studying the relationship between global model fairness and local model fairness. Additionally, we prove that for a broad class of fairness metrics, the global model's fairness can be obtained using only summary statistics from local clients. Based on that, we propose a globally fair training algorithm that directly minimizes the penalized empirical loss. Real-data experiments demonstrate the promising performance of our proposed approach for enhancing fairness while retaining high accuracy compared to locally fair training methods.
QuickVC: Any-to-many Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 23, 2023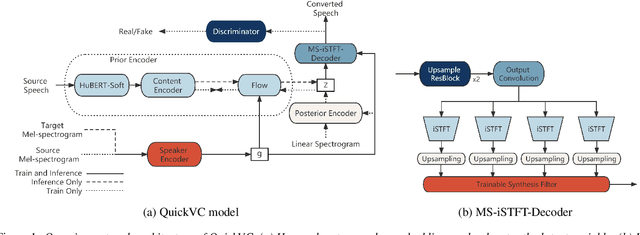
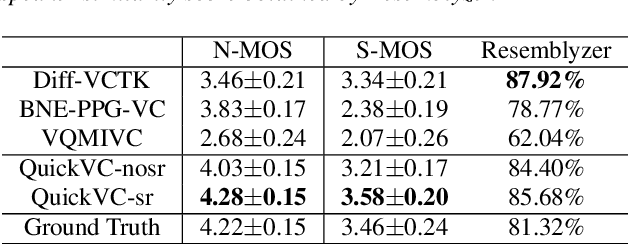

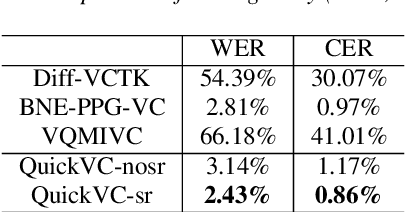
With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.
StockEmotions: Discover Investor Emotions for Financial Sentiment Analysis and Multivariate Time Series
Jan 23, 2023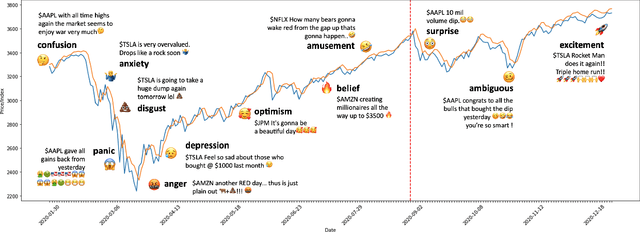
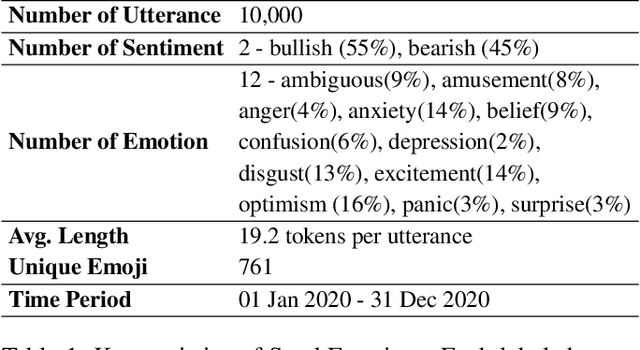
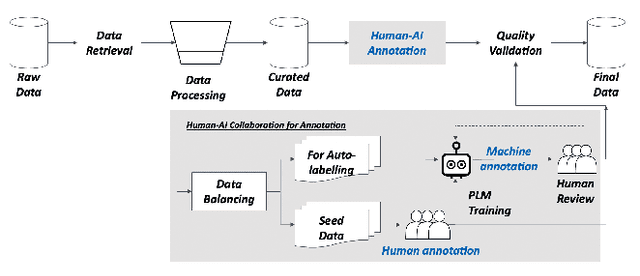
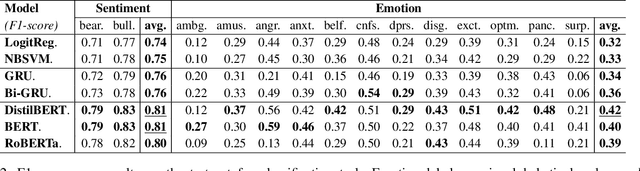
There has been growing interest in applying NLP techniques in the financial domain, however, resources are extremely limited. This paper introduces StockEmotions, a new dataset for detecting emotions in the stock market that consists of 10,000 English comments collected from StockTwits, a financial social media platform. Inspired by behavioral finance, it proposes 12 fine-grained emotion classes that span the roller coaster of investor emotion. Unlike existing financial sentiment datasets, StockEmotions presents granular features such as investor sentiment classes, fine-grained emotions, emojis, and time series data. To demonstrate the usability of the dataset, we perform a dataset analysis and conduct experimental downstream tasks. For financial sentiment/emotion classification tasks, DistilBERT outperforms other baselines, and for multivariate time series forecasting, a Temporal Attention LSTM model combining price index, text, and emotion features achieves the best performance than using a single feature.
Quantile LSTM: A Robust LSTM for Anomaly Detection In Time Series Data
Feb 17, 2023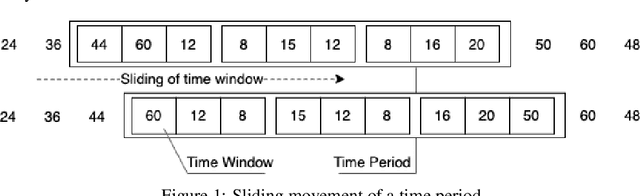
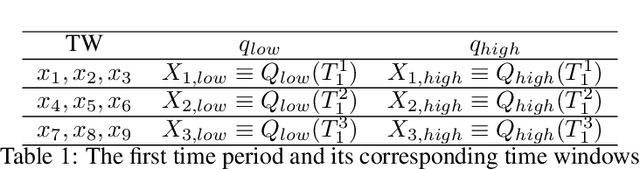
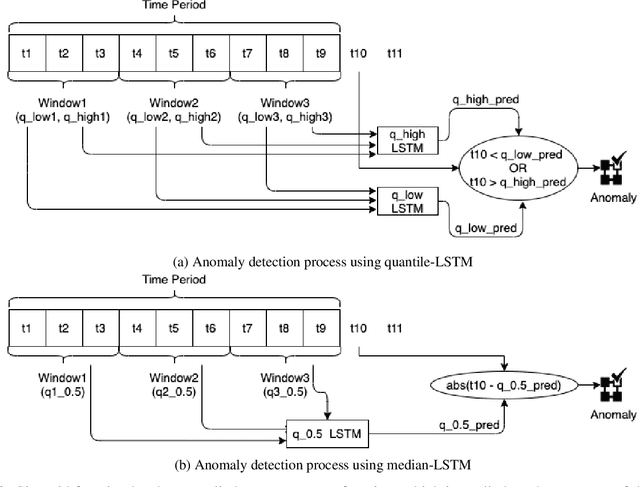
Anomalies refer to the departure of systems and devices from their normal behaviour in standard operating conditions. An anomaly in an industrial device can indicate an upcoming failure, often in the temporal direction. In this paper, we make two contributions: 1) we estimate conditional quantiles and consider three different ways to define anomalies based on the estimated quantiles. 2) we use a new learnable activation function in the popular Long Short Term Memory networks (LSTM) architecture to model temporal long-range dependency. In particular, we propose Parametric Elliot Function (PEF) as an activation function (AF) inside LSTM, which saturates lately compared to sigmoid and tanh. The proposed algorithms are compared with other well-known anomaly detection algorithms, such as Isolation Forest (iForest), Elliptic Envelope, Autoencoder, and modern Deep Learning models such as Deep Autoencoding Gaussian Mixture Model (DAGMM), Generative Adversarial Networks (GAN). The algorithms are evaluated in terms of various performance metrics, such as Precision and Recall. The algorithms have been tested on multiple industrial time-series datasets such as Yahoo, AWS, GE, and machine sensors. We have found that the LSTM-based quantile algorithms are very effective and outperformed the existing algorithms in identifying anomalies.