 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning-Enabled Zero-Touch Device Identification: Mitigating the Impact of Channel Variability Through MIMO Diversity
Jun 13, 2023
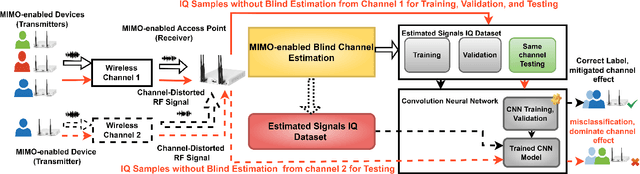
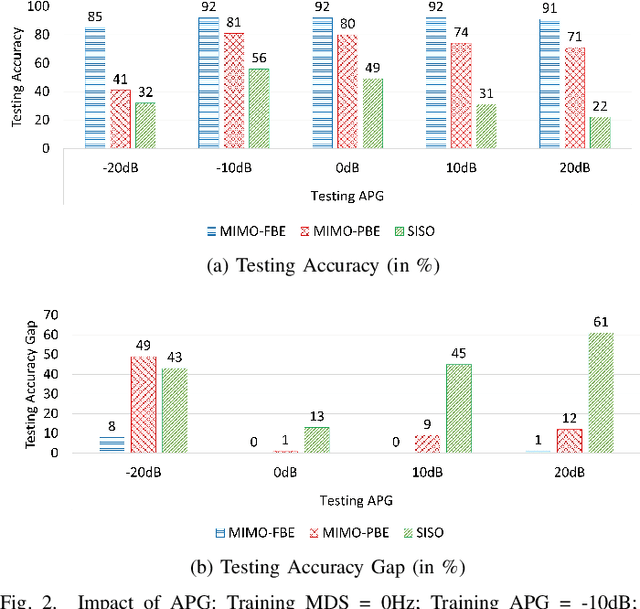

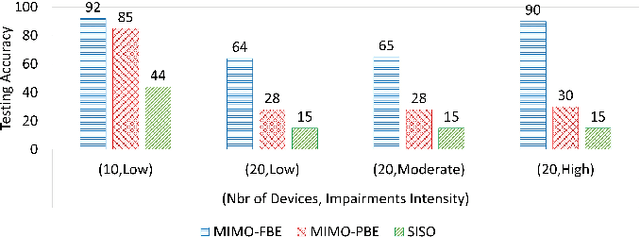
Deep learning-enabled device fingerprinting has proven efficient in enabling automated identification and authentication of transmitting devices. It does so by leveraging the transmitters' unique features that are inherent to hardware impairments caused during manufacturing to extract device-specific signatures that can be exploited to uniquely distinguish and separate between (identical) devices. Though shown to achieve promising performances, hardware fingerprinting approaches are known to suffer greatly when the training data and the testing data are generated under different channels conditions that often change when time and/or location changes. To the best of our knowledge, this work is the first to use MIMO diversity to mitigate the impact of channel variability and provide a channel-resilient device identification over flat fading channels. Specifically, we show that MIMO can increase the device classification accuracy by up to about $50\%$ when model training and testing are done over the same channel and by up to about $70\%$ when training and testing are done over different fading channels.
Monolingual and Cross-Lingual Knowledge Transfer for Topic Classification
Jun 13, 2023This article investigates the knowledge transfer from the RuQTopics dataset. This Russian topical dataset combines a large sample number (361,560 single-label, 170,930 multi-label) with extensive class coverage (76 classes). We have prepared this dataset from the "Yandex Que" raw data. By evaluating the RuQTopics - trained models on the six matching classes of the Russian MASSIVE subset, we have proved that the RuQTopics dataset is suitable for real-world conversational tasks, as the Russian-only models trained on this dataset consistently yield an accuracy around 85\% on this subset. We also have figured out that for the multilingual BERT, trained on the RuQTopics and evaluated on the same six classes of MASSIVE (for all MASSIVE languages), the language-wise accuracy closely correlates (Spearman correlation 0.773 with p-value 2.997e-11) with the approximate size of the pretraining BERT's data for the corresponding language. At the same time, the correlation of the language-wise accuracy with the linguistical distance from Russian is not statistically significant.
Speaker Verification Across Ages: Investigating Deep Speaker Embedding Sensitivity to Age Mismatch in Enrollment and Test Speech
Jun 13, 2023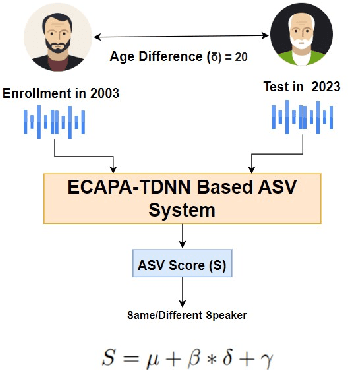
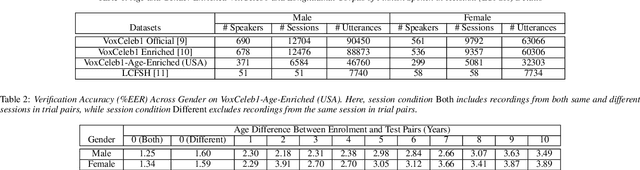

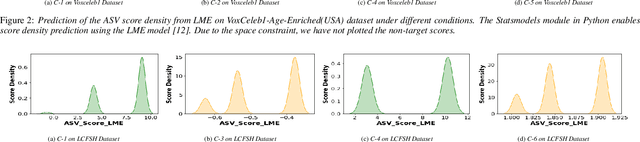
In this paper, we study the impact of the ageing on modern deep speaker embedding based automatic speaker verification (ASV) systems. We have selected two different datasets to examine ageing on the state-of-the-art ECAPA-TDNN system. The first dataset, used for addressing short-term ageing (up to 10 years time difference between enrollment and test) under uncontrolled conditions, is VoxCeleb. The second dataset, used for addressing long-term ageing effect (up to 40 years difference) of Finnish speakers under a more controlled setup, is Longitudinal Corpus of Finnish Spoken in Helsinki (LCFSH). Our study provides new insights into the impact of speaker ageing on modern ASV systems. Specifically, we establish a quantitative measure between ageing and ASV scores. Further, our research indicates that ageing affects female English speakers to a greater degree than male English speakers, while in the case of Finnish, it has a greater impact on male speakers than female speakers.
Multi-Robot Motion Planning: A Learning-Based Artificial Potential Field Solution
Jun 13, 2023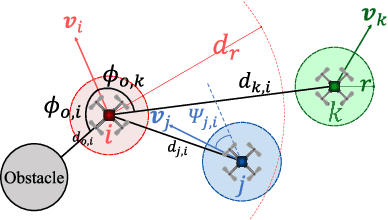
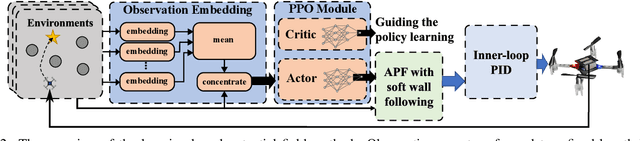
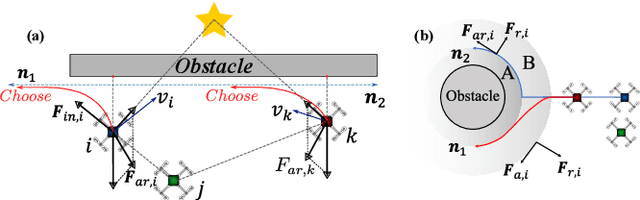
Motion planning is a crucial aspect of robot autonomy as it involves identifying a feasible motion path to a destination while taking into consideration various constraints, such as input, safety, and performance constraints, without violating either system or environment boundaries. This becomes particularly challenging when multiple robots run without communication, which compromises their real-time efficiency, safety, and performance. In this paper, we present a learning-based potential field algorithm that incorporates deep reinforcement learning into an artificial potential field (APF). Specifically, we introduce an observation embedding mechanism that pre-processes dynamic information about the environment and develop a soft wall-following rule to improve trajectory smoothness. Our method, while belonging to reactive planning, implicitly encodes environmental properties. Additionally, our approach can scale up to any number of robots and has demonstrated superior performance compared to APF and RL through numerical simulations. Finally, experiments are conducted to highlight the effectiveness of our proposed method.
Latent Exploration for Reinforcement Learning
May 31, 2023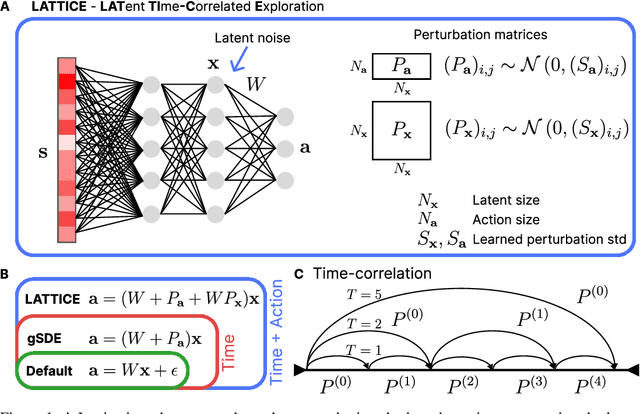
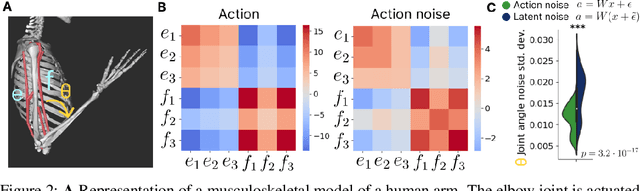
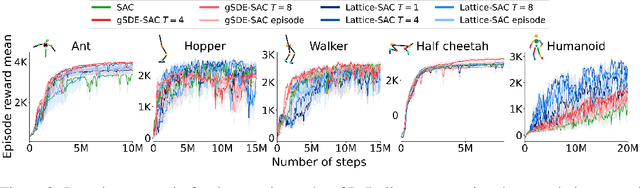
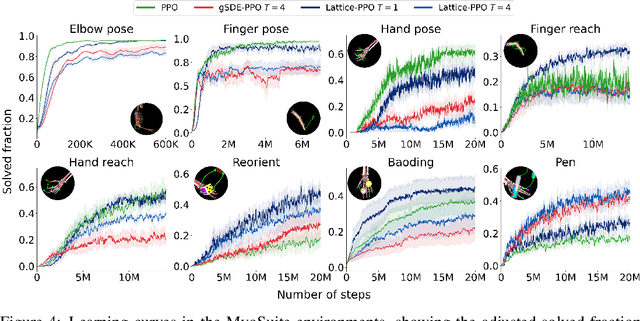
In Reinforcement Learning, agents learn policies by exploring and interacting with the environment. Due to the curse of dimensionality, learning policies that map high-dimensional sensory input to motor output is particularly challenging. During training, state of the art methods (SAC, PPO, etc.) explore the environment by perturbing the actuation with independent Gaussian noise. While this unstructured exploration has proven successful in numerous tasks, it ought to be suboptimal for overactuated systems. When multiple actuators, such as motors or muscles, drive behavior, uncorrelated perturbations risk diminishing each other's effect, or modifying the behavior in a task-irrelevant way. While solutions to introduce time correlation across action perturbations exist, introducing correlation across actuators has been largely ignored. Here, we propose LATent TIme-Correlated Exploration (Lattice), a method to inject temporally-correlated noise into the latent state of the policy network, which can be seamlessly integrated with on- and off-policy algorithms. We demonstrate that the noisy actions generated by perturbing the network's activations can be modeled as a multivariate Gaussian distribution with a full covariance matrix. In the PyBullet locomotion tasks, Lattice-SAC achieves state of the art results, and reaches 18% higher reward than unstructured exploration in the Humanoid environment. In the musculoskeletal control environments of MyoSuite, Lattice-PPO achieves higher reward in most reaching and object manipulation tasks, while also finding more energy-efficient policies with reductions of 20-60%. Overall, we demonstrate the effectiveness of structured action noise in time and actuator space for complex motor control tasks.
Exploring the Responses of Large Language Models to Beginner Programmers' Help Requests
Jun 09, 2023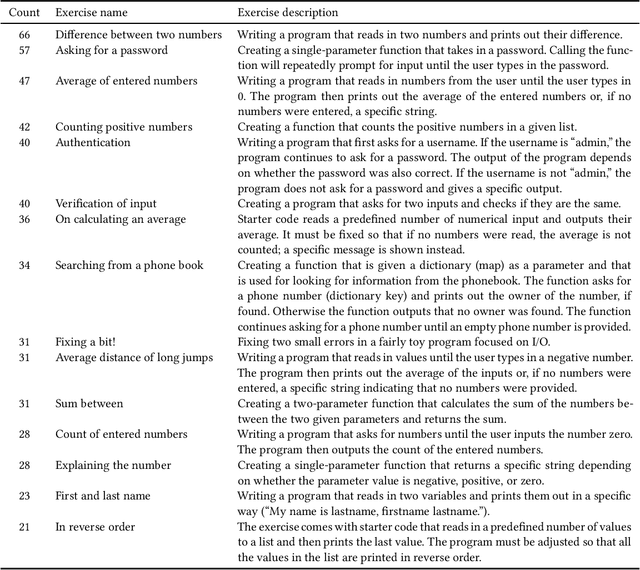

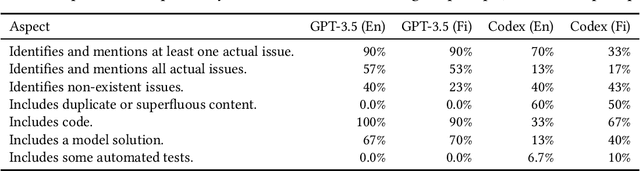

Background and Context: Over the past year, large language models (LLMs) have taken the world by storm. In computing education, like in other walks of life, many opportunities and threats have emerged as a consequence. Objectives: In this article, we explore such opportunities and threats in a specific area: responding to student programmers' help requests. More specifically, we assess how good LLMs are at identifying issues in problematic code that students request help on. Method: We collected a sample of help requests and code from an online programming course. We then prompted two different LLMs (OpenAI Codex and GPT-3.5) to identify and explain the issues in the students' code and assessed the LLM-generated answers both quantitatively and qualitatively. Findings: GPT-3.5 outperforms Codex in most respects. Both LLMs frequently find at least one actual issue in each student program (GPT-3.5 in 90% of the cases). Neither LLM excels at finding all the issues (GPT-3.5 finding them 57% of the time). False positives are common (40% chance for GPT-3.5). The advice that the LLMs provide on the issues is often sensible. The LLMs perform better on issues involving program logic rather than on output formatting. Model solutions are frequently provided even when the LLM is prompted not to. LLM responses to prompts in a non-English language are only slightly worse than responses to English prompts. Implications: Our results continue to highlight the utility of LLMs in programming education. At the same time, the results highlight the unreliability of LLMs: LLMs make some of the same mistakes that students do, perhaps especially when formatting output as required by automated assessment systems. Our study informs teachers interested in using LLMs as well as future efforts to customize LLMs for the needs of programming education.
Lagrangian Flow Networks for Conservation Laws
May 26, 2023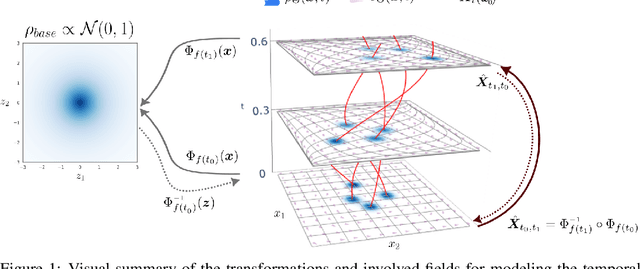

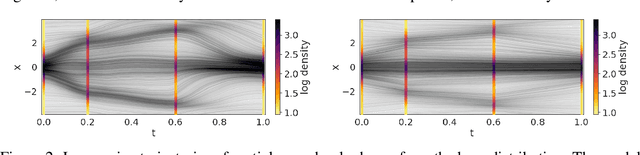
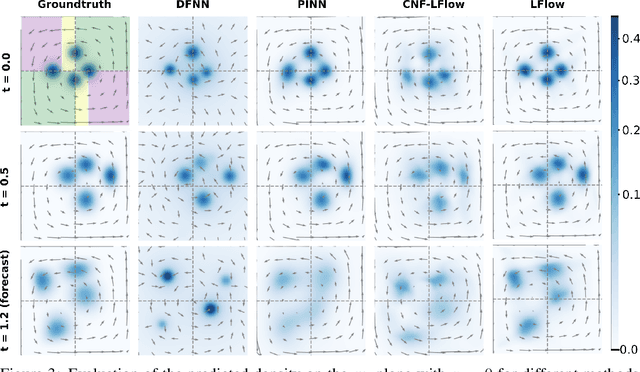
We introduce Lagrangian Flow Networks (LFlows) for modeling fluid densities and velocities continuously in space and time. The proposed LFlows satisfy by construction the continuity equation, a PDE describing mass conservation in its differentiable form. Our model is based on the insight that solutions to the continuity equation can be expressed as time-dependent density transformations via differentiable and invertible maps. This follows from classical theory of existence and uniqueness of Lagrangian flows for smooth vector fields. Hence, we model fluid densities by transforming a base density with parameterized diffeomorphisms conditioned on time. The key benefit compared to methods relying on Neural-ODE or PINNs is that the analytic expression of the velocity is always consistent with the density. Furthermore, there is no need for expensive numerical solvers, nor for enforcing the PDE with penalty methods. Lagrangian Flow Networks show improved predictive accuracy on synthetic density modeling tasks compared to competing models in both 2D and 3D. We conclude with a real-world application of modeling bird migration based on sparse weather radar measurements.
Computational Flash Photography through Intrinsics
Jun 09, 2023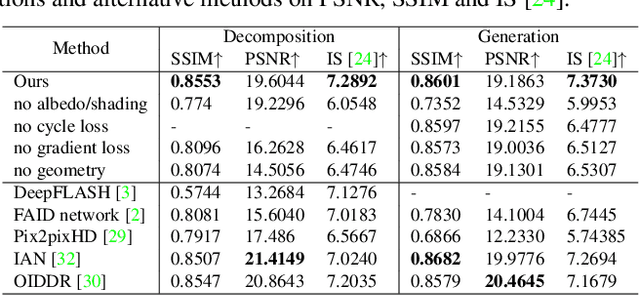



Flash is an essential tool as it often serves as the sole controllable light source in everyday photography. However, the use of flash is a binary decision at the time a photograph is captured with limited control over its characteristics such as strength or color. In this work, we study the computational control of the flash light in photographs taken with or without flash. We present a physically motivated intrinsic formulation for flash photograph formation and develop flash decomposition and generation methods for flash and no-flash photographs, respectively. We demonstrate that our intrinsic formulation outperforms alternatives in the literature and allows us to computationally control flash in in-the-wild images.
Computation Offloading for Edge Computing in RIS-Assisted Symbiotic Radio Systems
May 29, 2023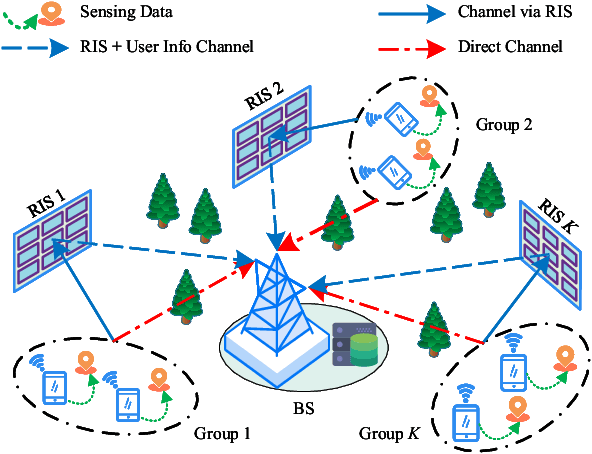

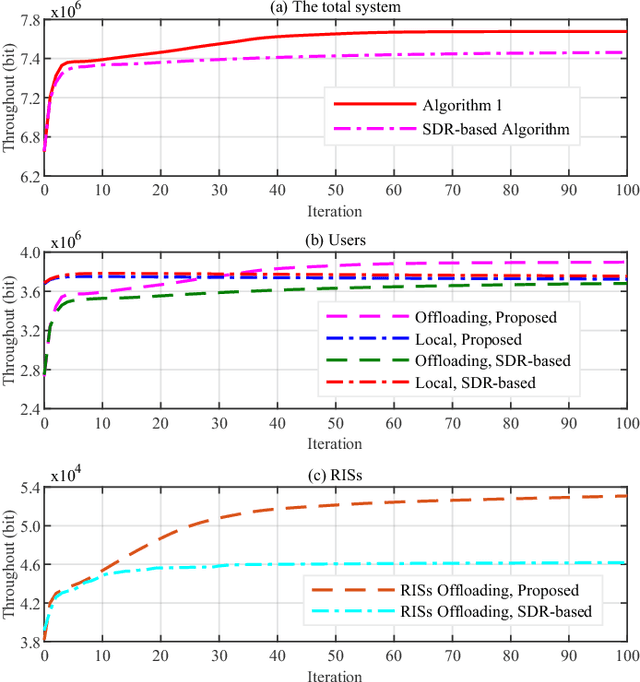
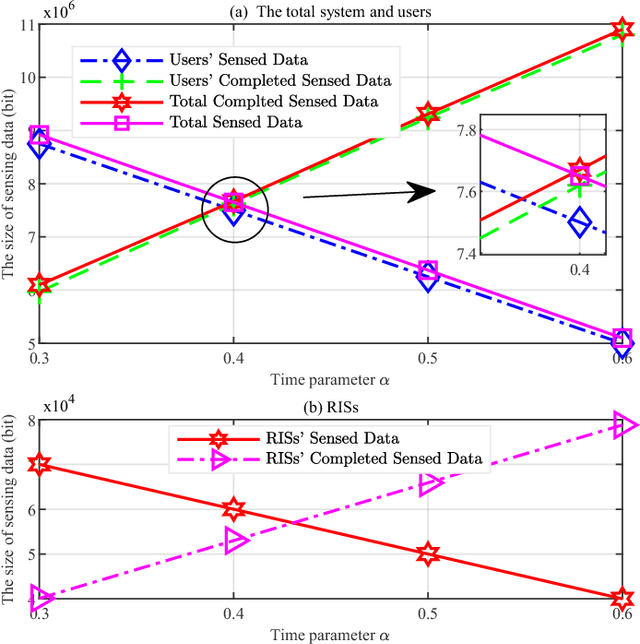
In the paper, we investigate the coordination process of sensing and computation offloading in a reconfigurable intelligent surface (RIS)-aided base station (BS)-centric symbiotic radio (SR) systems. Specifically, the Internet-of-Things (IoT) devices first sense data from environment and then tackle the data locally or offload the data to BS for remote computing, while RISs are leveraged to enhance the quality of blocked channels and also act as IoT devices to transmit its sensed data. To explore the mechanism of cooperative sensing and computation offloading in this system, we aim at maximizing the total completed sensed bits of all users and RISs by jointly optimizing the time allocation parameter, the passive beamforming at each RIS, the transmit beamforming at BS, and the energy partition parameters for all users subject to the size of sensed data, energy supply and given time cycle. The formulated nonconvex problem is tightly coupled by the time allocation parameter and involves the mathematical expectations, which cannot be solved straightly. We use Monte Carlo and fractional programming methods to transform the nonconvex objective function and then propose an alternating optimization-based algorithm to find an approximate solution with guaranteed convergence. Numerical results show that the RIS-aided SR system outperforms other benchmarks in sensing. Furthermore, with the aid of RIS, the channel and system performance can be significantly improved.
Time Encoding Sampling of Bandpass Signals
Jan 31, 2023This paper investigates the problem of sampling and reconstructing bandpass signals using time encoding machine(TEM). It is shown that the sampling in principle is equivalent to periodic non-uniform sampling (PNS). Then the TEM parameters can be set according to the signal bandwidth and amplitude instead of upper-edge frequency and amplitude as in the case of bandlimited/lowpass signals. For a bandpass signal of a single information band, it can be perfectly reconstructed if the TEM parameters are such that the difference between any consecutive values of the time sequence in each channel is bounded by the inverse of the signal bandwidth. A reconstruction method incorporating the interpolation functions of PNS is proposed. Numerical experiments validate the feasibility and effectiveness of the proposed TEM scheme.