 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SuryaKiran at MEDIQA-Sum 2023: Leveraging LoRA for Clinical Dialogue Summarization
Jul 11, 2023
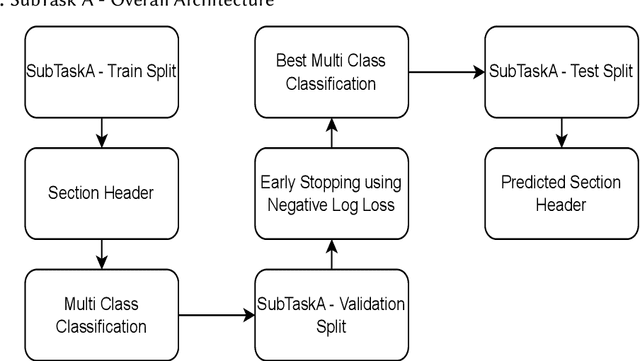
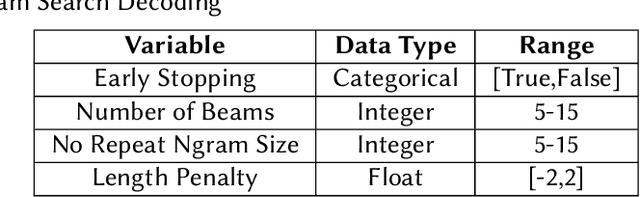
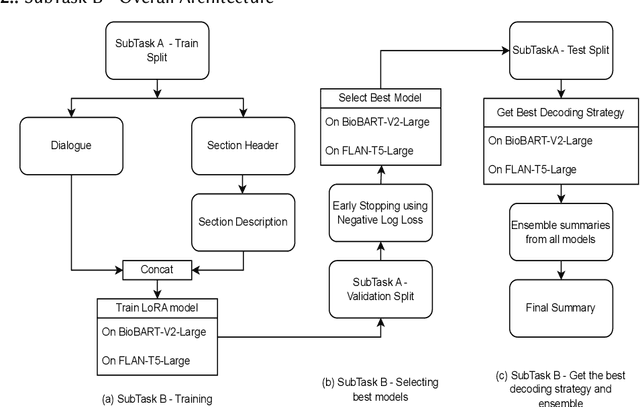
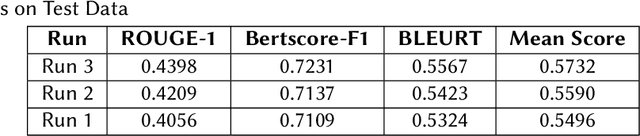
Finetuning Large Language Models helps improve the results for domain-specific use cases. End-to-end finetuning of large language models is time and resource intensive and has high storage requirements to store the finetuned version of the large language model. Parameter Efficient Fine Tuning (PEFT) methods address the time and resource challenges by keeping the large language model as a fixed base and add additional layers, which the PEFT methods finetune. This paper demonstrates the evaluation results for one such PEFT method Low Rank Adaptation (LoRA), for Clinical Dialogue Summarization. The evaluation results show that LoRA works at par with end-to-end finetuning for a large language model. The paper presents the evaluations done for solving both the Subtask A and B from ImageCLEFmedical {https://www.imageclef.org/2023/medical}
A Novel Explainable Artificial Intelligence Model in Image Classification problem
Jul 09, 2023
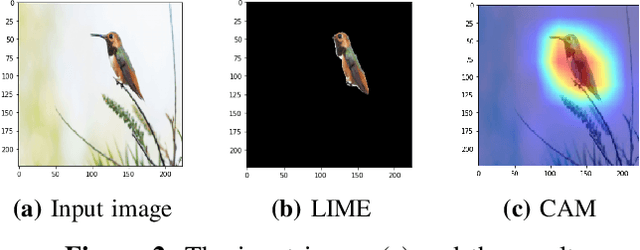
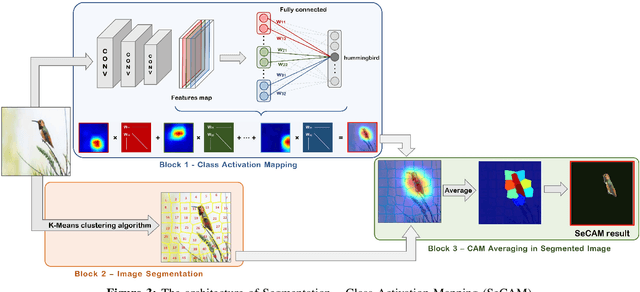
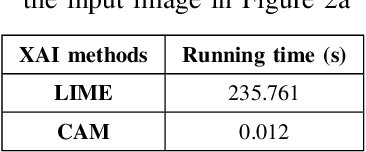
In recent years, artificial intelligence is increasingly being applied widely in many different fields and has a profound and direct impact on human life. Following this is the need to understand the principles of the model making predictions. Since most of the current high-precision models are black boxes, neither the AI scientist nor the end-user deeply understands what's going on inside these models. Therefore, many algorithms are studied for the purpose of explaining AI models, especially those in the problem of image classification in the field of computer vision such as LIME, CAM, GradCAM. However, these algorithms still have limitations such as LIME's long execution time and CAM's confusing interpretation of concreteness and clarity. Therefore, in this paper, we propose a new method called Segmentation - Class Activation Mapping (SeCAM) that combines the advantages of these algorithms above, while at the same time overcoming their disadvantages. We tested this algorithm with various models, including ResNet50, Inception-v3, VGG16 from ImageNet Large Scale Visual Recognition Challenge (ILSVRC) data set. Outstanding results when the algorithm has met all the requirements for a specific explanation in a remarkably concise time.
Learning Nonlinear Projections for Reduced-Order Modeling of Dynamical Systems using Constrained Autoencoders
Jul 28, 2023Recently developed reduced-order modeling techniques aim to approximate nonlinear dynamical systems on low-dimensional manifolds learned from data. This is an effective approach for modeling dynamics in a post-transient regime where the effects of initial conditions and other disturbances have decayed. However, modeling transient dynamics near an underlying manifold, as needed for real-time control and forecasting applications, is complicated by the effects of fast dynamics and nonnormal sensitivity mechanisms. To begin to address these issues, we introduce a parametric class of nonlinear projections described by constrained autoencoder neural networks in which both the manifold and the projection fibers are learned from data. Our architecture uses invertible activation functions and biorthogonal weight matrices to ensure that the encoder is a left inverse of the decoder. We also introduce new dynamics-aware cost functions that promote learning of oblique projection fibers that account for fast dynamics and nonnormality. To demonstrate these methods and the specific challenges they address, we provide a detailed case study of a three-state model of vortex shedding in the wake of a bluff body immersed in a fluid, which has a two-dimensional slow manifold that can be computed analytically. In anticipation of future applications to high-dimensional systems, we also propose several techniques for constructing computationally efficient reduced-order models using our proposed nonlinear projection framework. This includes a novel sparsity-promoting penalty for the encoder that avoids detrimental weight matrix shrinkage via computation on the Grassmann manifold.
D2S: Representing local descriptors and global scene coordinates for camera relocalization
Jul 28, 2023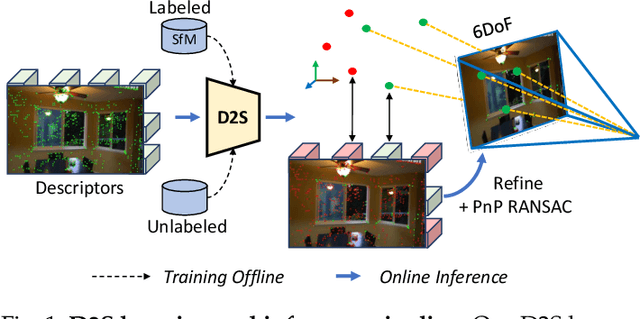
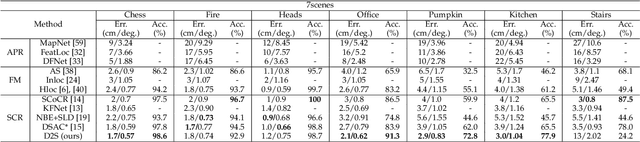
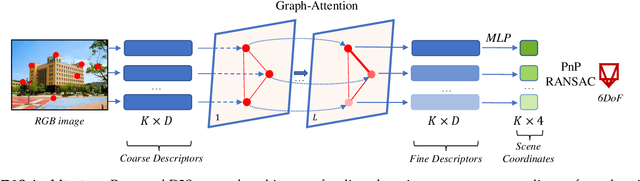

State-of-the-art visual localization methods mostly rely on complex procedures to match local descriptors and 3D point clouds. However, these procedures can incur significant cost in terms of inference, storage, and updates over time. In this study, we propose a direct learning-based approach that utilizes a simple network named D2S to represent local descriptors and their scene coordinates. Our method is characterized by its simplicity and cost-effectiveness. It solely leverages a single RGB image for localization during the testing phase and only requires a lightweight model to encode a complex sparse scene. The proposed D2S employs a combination of a simple loss function and graph attention to selectively focus on robust descriptors while disregarding areas such as clouds, trees, and several dynamic objects. This selective attention enables D2S to effectively perform a binary-semantic classification for sparse descriptors. Additionally, we propose a new outdoor dataset to evaluate the capabilities of visual localization methods in terms of scene generalization and self-updating from unlabeled observations. Our approach outperforms the state-of-the-art CNN-based methods in scene coordinate regression in indoor and outdoor environments. It demonstrates the ability to generalize beyond training data, including scenarios involving transitions from day to night and adapting to domain shifts, even in the absence of the labeled data sources. The source code, trained models, dataset, and demo videos are available at the following link: https://thpjp.github.io/d2s
PUF Probe: A PUF-based Hardware Authentication Equipment for IEDs
Jul 28, 2023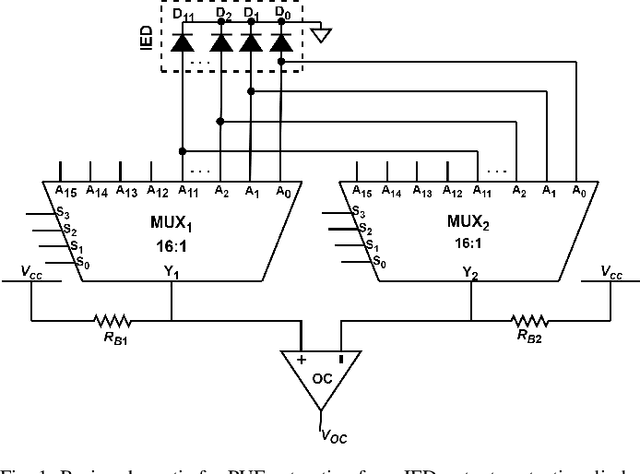
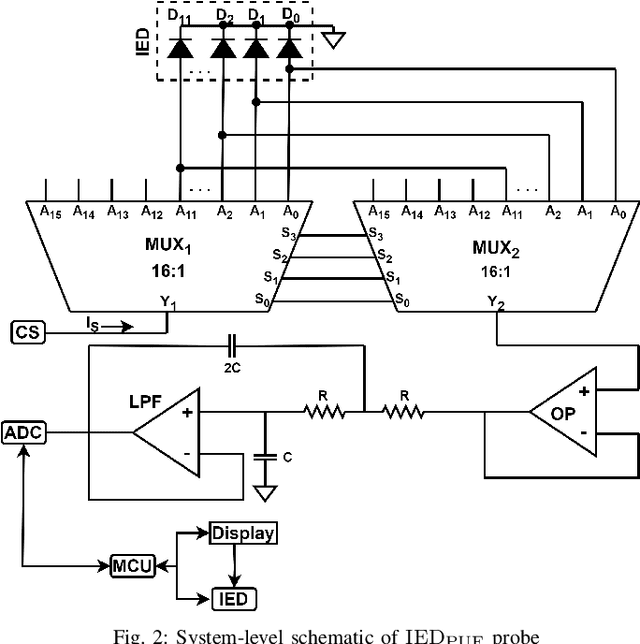
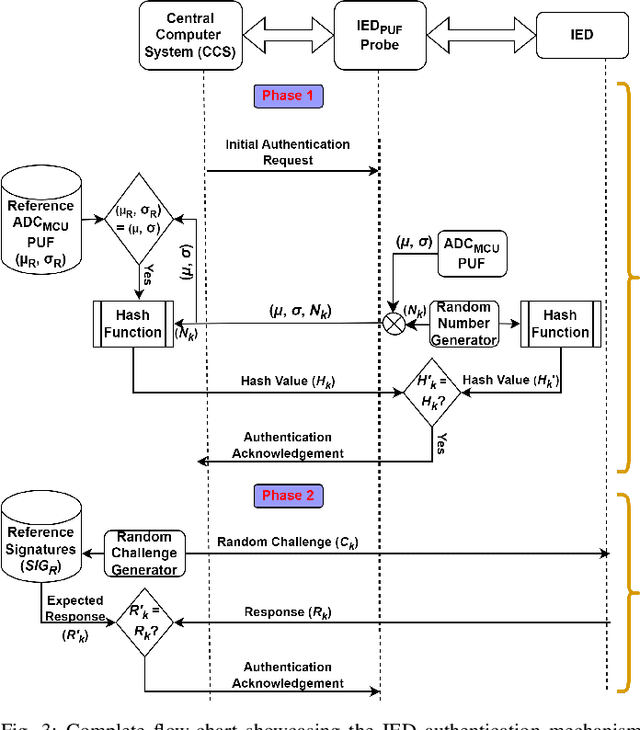
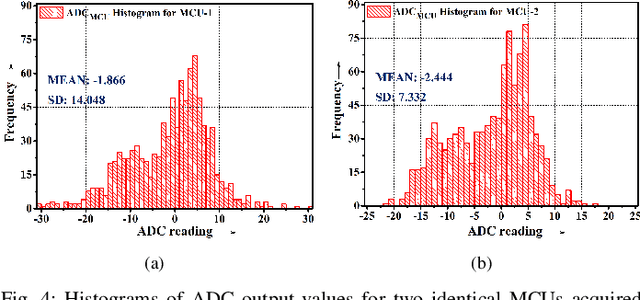
Intelligent Electronic Devices (IEDs) are vital components in modern electrical substations, collectively responsible for monitoring electrical parameters and performing protective functions. As a result, ensuring the integrity of IEDs is an essential criteria. While standards like IEC 61850 and IEC 60870-5-104 establish cyber-security protocols for secure information exchange in IED-based power systems, the physical integrity of IEDs is often overlooked, leading to a rise in counterfeit and tainted electronic products. This paper proposes a physical unclonable function (PUF)-based device (IEDPUF probe) capable of extracting unique hardware signatures from commercial IEDs. These signatures can serve as identifiers, facilitating the authentication and protection of IEDs against counterfeiting. The paper presents the complete hardware architecture of the IEDPUF probe, along with algorithms for signature extraction and authentication. The process involves the central computer system (CCS) initiating IED authentication requests by sending random challenges to the IEDPUF probe. Based on the challenges, the IEDPUF probe generates responses, which are then verified by the CCS to authenticate the IED. Additionally, a two-way authentication technique is employed to ensure that only verified requests are granted access for signature extraction. Experimental results confirm the efficacy of the proposed IEDPUF probe. The results demonstrate its ability to provide real-time responses possessing randomness while uniquely identifying the IED under investigation. The proposed IEDPUF probe offers a simple, cost-effective, accurate solution with minimal storage requirements, enhancing the authenticity and integrity of IEDs within electrical substations
Efficient Convolution and Transformer-Based Network for Video Frame Interpolation
Jul 12, 2023
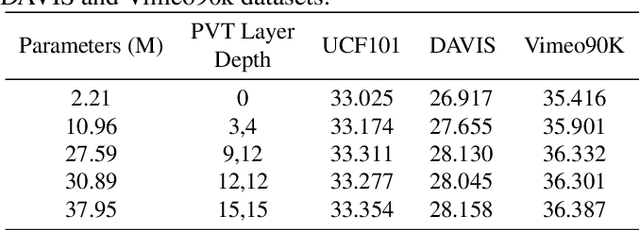
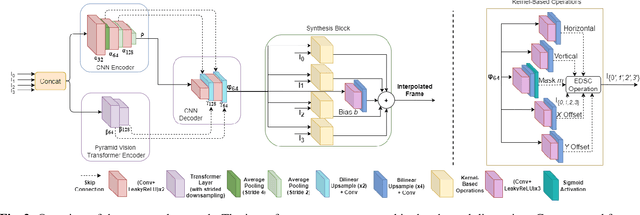

Video frame interpolation is an increasingly important research task with several key industrial applications in the video coding, broadcast and production sectors. Recently, transformers have been introduced to the field resulting in substantial performance gains. However, this comes at a cost of greatly increased memory usage, training and inference time. In this paper, a novel method integrating a transformer encoder and convolutional features is proposed. This network reduces the memory burden by close to 50% and runs up to four times faster during inference time compared to existing transformer-based interpolation methods. A dual-encoder architecture is introduced which combines the strength of convolutions in modelling local correlations with those of the transformer for long-range dependencies. Quantitative evaluations are conducted on various benchmarks with complex motion to showcase the robustness of the proposed method, achieving competitive performance compared to state-of-the-art interpolation networks.
No Train No Gain: Revisiting Efficient Training Algorithms For Transformer-based Language Models
Jul 12, 2023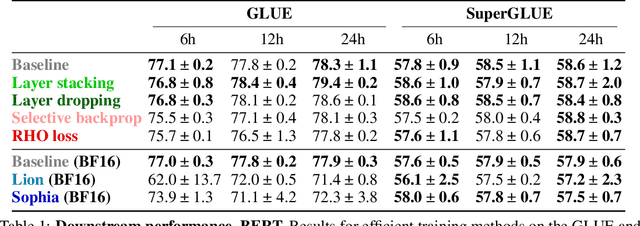
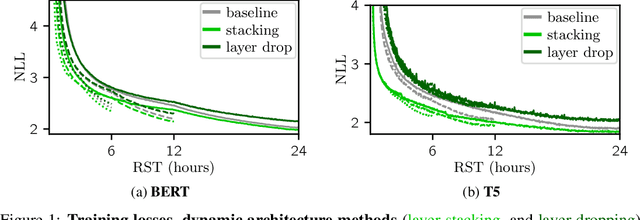
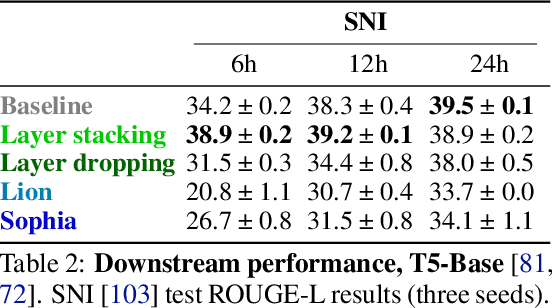
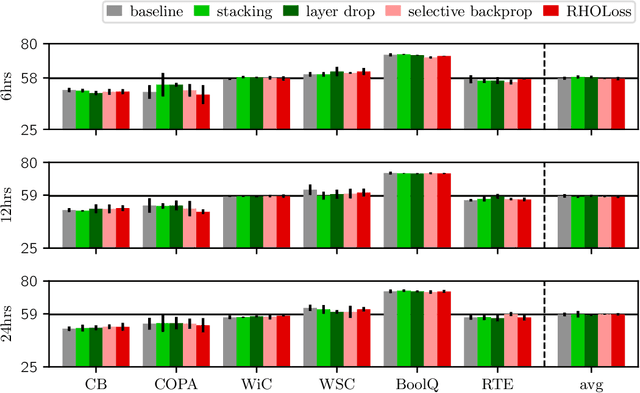
The computation necessary for training Transformer-based language models has skyrocketed in recent years. This trend has motivated research on efficient training algorithms designed to improve training, validation, and downstream performance faster than standard training. In this work, we revisit three categories of such algorithms: dynamic architectures (layer stacking, layer dropping), batch selection (selective backprop, RHO loss), and efficient optimizers (Lion, Sophia). When pre-training BERT and T5 with a fixed computation budget using such methods, we find that their training, validation, and downstream gains vanish compared to a baseline with a fully-decayed learning rate. We define an evaluation protocol that enables computation to be done on arbitrary machines by mapping all computation time to a reference machine which we call reference system time. We discuss the limitations of our proposed protocol and release our code to encourage rigorous research in efficient training procedures: https://github.com/JeanKaddour/NoTrainNoGain.
FinGPT: Democratizing Internet-scale Data for Financial Large Language Models
Jul 19, 2023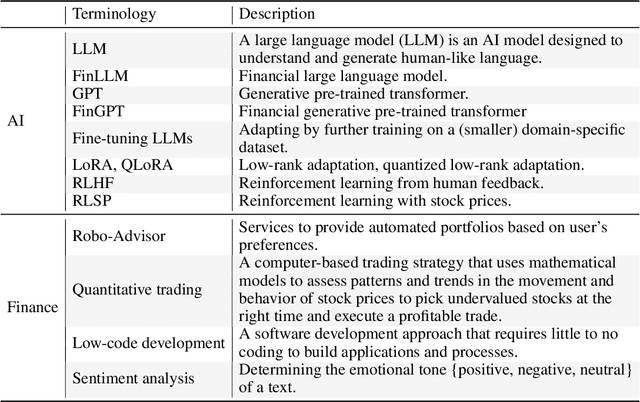
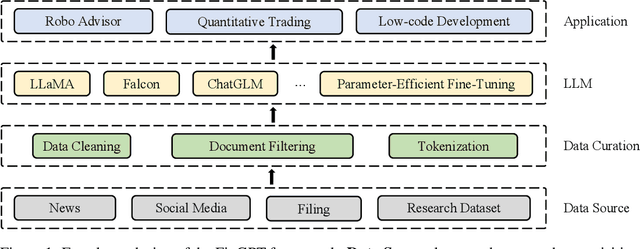
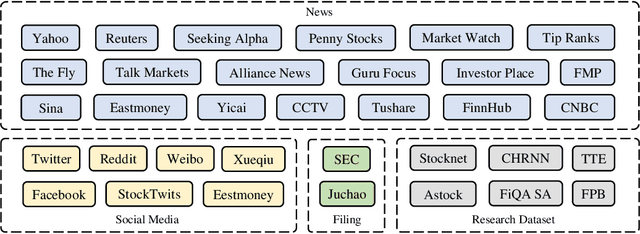
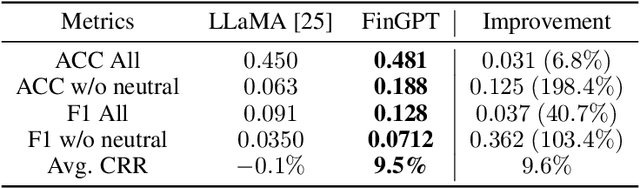
Large language models (LLMs) have demonstrated remarkable proficiency in understanding and generating human-like texts, which may potentially revolutionize the finance industry. However, existing LLMs often fall short in the financial field, which is mainly attributed to the disparities between general text data and financial text data. Unfortunately, there is only a limited number of financial text datasets available (quite small size), and BloombergGPT, the first financial LLM (FinLLM), is close-sourced (only the training logs were released). In light of this, we aim to democratize Internet-scale financial data for LLMs, which is an open challenge due to diverse data sources, low signal-to-noise ratio, and high time-validity. To address the challenges, we introduce an open-sourced and data-centric framework, \textit{Financial Generative Pre-trained Transformer (FinGPT)}, that automates the collection and curation of real-time financial data from >34 diverse sources on the Internet, providing researchers and practitioners with accessible and transparent resources to develop their FinLLMs. Additionally, we propose a simple yet effective strategy for fine-tuning FinLLM using the inherent feedback from the market, dubbed Reinforcement Learning with Stock Prices (RLSP). We also adopt the Low-rank Adaptation (LoRA, QLoRA) method that enables users to customize their own FinLLMs from open-source general-purpose LLMs at a low cost. Finally, we showcase several FinGPT applications, including robo-advisor, sentiment analysis for algorithmic trading, and low-code development. FinGPT aims to democratize FinLLMs, stimulate innovation, and unlock new opportunities in open finance. The codes are available at https://github.com/AI4Finance-Foundation/FinGPT and https://github.com/AI4Finance-Foundation/FinNLP
Implementing Edge Based Object Detection For Microplastic Debris
Jul 30, 2023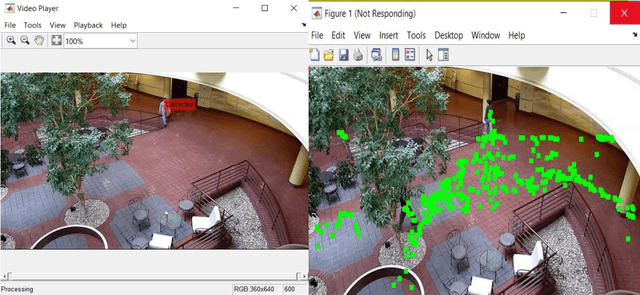

Plastic has imbibed itself as an indispensable part of our day to day activities, becoming a source of problems due to its non-biodegradable nature and cheaper production prices. With these problems, comes the challenge of mitigating and responding to the aftereffects of disposal or the lack of proper disposal which leads to waste concentrating in locations and disturbing ecosystems for both plants and animals. As plastic debris levels continue to rise with the accumulation of waste in garbage patches in landfills and more hazardously in natural water bodies, swift action is necessary to plug or cease this flow. While manual sorting operations and detection can offer a solution, they can be augmented using highly advanced computer imagery linked with robotic appendages for removing wastes. The primary application of focus in this report are the much-discussed Computer Vision and Open Vision which have gained novelty for their light dependence on internet and ability to relay information in remote areas. These applications can be applied to the creation of edge-based mobility devices that can as a counter to the growing problem of plastic debris in oceans and rivers, demanding little connectivity and still offering the same results with reasonably timed maintenance. The principal findings of this project cover the various methods that were tested and deployed to detect waste in images, as well as comparing them against different waste types. The project has been able to produce workable models that can perform on time detection of sampled images using an augmented CNN approach. Latter portions of the project have also achieved a better interpretation of the necessary preprocessing steps required to arrive at the best accuracies, including the best hardware for expanding waste detection studies to larger environments.
HUTFormer: Hierarchical U-Net Transformer for Long-Term Traffic Forecasting
Jul 27, 2023Traffic forecasting, which aims to predict traffic conditions based on historical observations, has been an enduring research topic and is widely recognized as an essential component of intelligent transportation. Recent proposals on Spatial-Temporal Graph Neural Networks (STGNNs) have made significant progress by combining sequential models with graph convolution networks. However, due to high complexity issues, STGNNs only focus on short-term traffic forecasting, e.g., 1-hour forecasting, while ignoring more practical long-term forecasting. In this paper, we make the first attempt to explore long-term traffic forecasting, e.g., 1-day forecasting. To this end, we first reveal its unique challenges in exploiting multi-scale representations. Then, we propose a novel Hierarchical U-net TransFormer (HUTFormer) to address the issues of long-term traffic forecasting. HUTFormer consists of a hierarchical encoder and decoder to jointly generate and utilize multi-scale representations of traffic data. Specifically, for the encoder, we propose window self-attention and segment merging to extract multi-scale representations from long-term traffic data. For the decoder, we design a cross-scale attention mechanism to effectively incorporate multi-scale representations. In addition, HUTFormer employs an efficient input embedding strategy to address the complexity issues. Extensive experiments on four traffic datasets show that the proposed HUTFormer significantly outperforms state-of-the-art traffic forecasting and long time series forecasting baselines.