 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
From Ambiguity to Explicitness: NLP-Assisted 5G Specification Abstraction for Formal Analysis
Aug 07, 2023
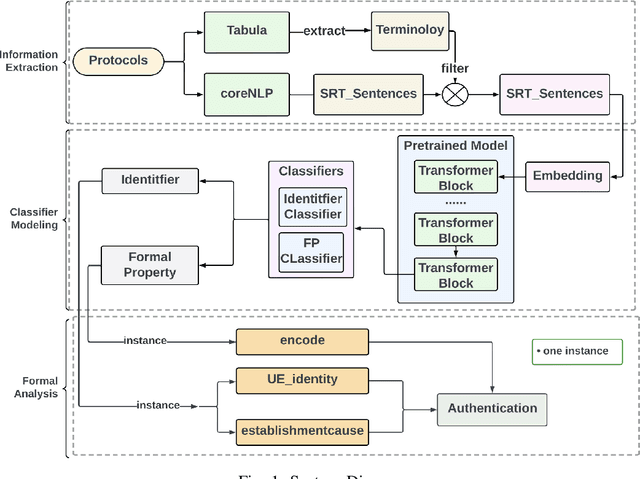
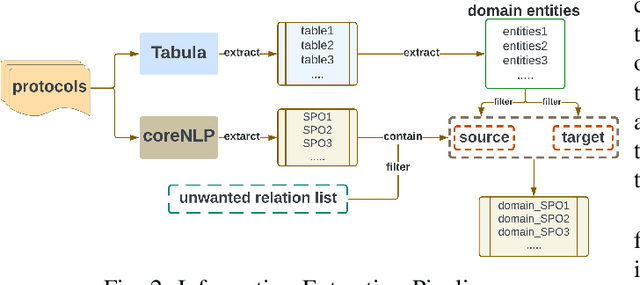
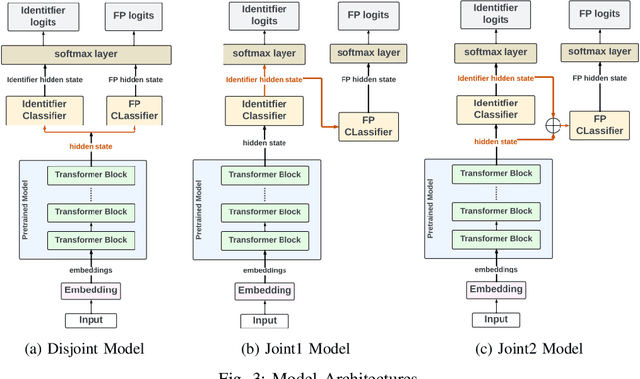
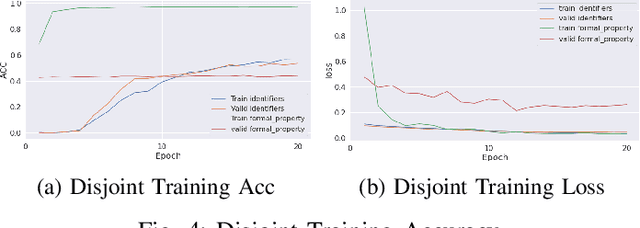
Formal method-based analysis of the 5G Wireless Communication Protocol is crucial for identifying logical vulnerabilities and facilitating an all-encompassing security assessment, especially in the design phase. Natural Language Processing (NLP) assisted techniques and most of the tools are not widely adopted by the industry and research community. Traditional formal verification through a mathematics approach heavily relied on manual logical abstraction prone to being time-consuming, and error-prone. The reason that the NLP-assisted method did not apply in industrial research may be due to the ambiguity in the natural language of the protocol designs nature is controversial to the explicitness of formal verification. To address the challenge of adopting the formal methods in protocol designs, targeting (3GPP) protocols that are written in natural language, in this study, we propose a hybrid approach to streamline the analysis of protocols. We introduce a two-step pipeline that first uses NLP tools to construct data and then uses constructed data to extract identifiers and formal properties by using the NLP model. The identifiers and formal properties are further used for formal analysis. We implemented three models that take different dependencies between identifiers and formal properties as criteria. Our results of the optimal model reach valid accuracy of 39% for identifier extraction and 42% for formal properties predictions. Our work is proof of concept for an efficient procedure in performing formal analysis for largescale complicate specification and protocol analysis, especially for 5G and nextG communications.
GraPhSyM: Graph Physical Synthesis Model
Aug 07, 2023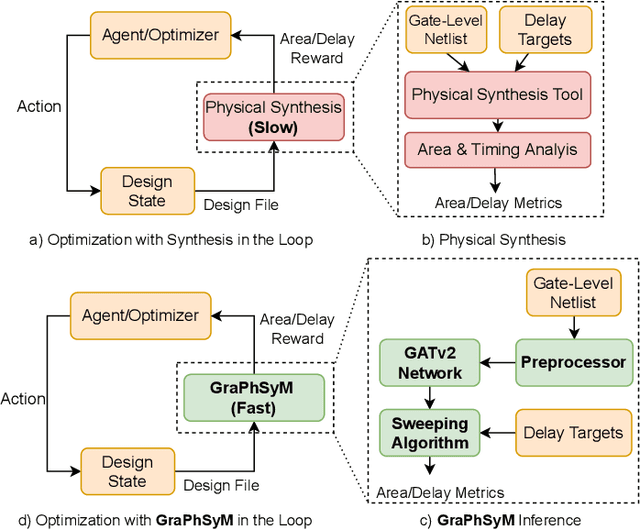

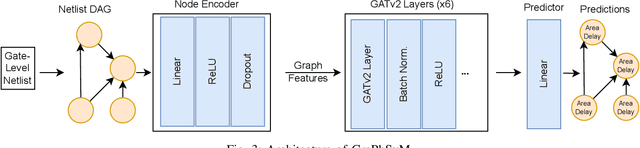
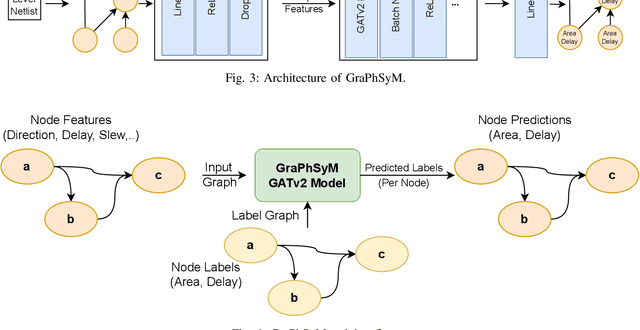
In this work, we introduce GraPhSyM, a Graph Attention Network (GATv2) model for fast and accurate estimation of post-physical synthesis circuit delay and area metrics from pre-physical synthesis circuit netlists. Once trained, GraPhSyM provides accurate visibility of final design metrics to early EDA stages, such as logic synthesis, without running the slow physical synthesis flow, enabling global co-optimization across stages. Additionally, the swift and precise feedback provided by GraPhSym is instrumental for machine-learning-based EDA optimization frameworks. Given a gate-level netlist of a circuit represented as a graph, GraPhSyM utilizes graph structure, connectivity, and electrical property features to predict the impact of physical synthesis transformations such as buffer insertion and gate sizing. When trained on a dataset of 6000 prefix adder designs synthesized at an aggressive delay target, GraPhSyM can accurately predict the post-synthesis delay (98.3%) and area (96.1%) metrics of unseen adders with a fast 0.22s inference time. Furthermore, we illustrate the compositionality of GraPhSyM by employing the model trained on a fixed delay target to accurately anticipate post-synthesis metrics at a variety of unseen delay targets. Lastly, we report promising generalization capabilities of the GraPhSyM model when it is evaluated on circuits different from the adders it was exclusively trained on. The results show the potential for GraPhSyM to serve as a powerful tool for advanced optimization techniques and as an oracle for EDA machine learning frameworks.
Hybrid quantum transfer learning for crack image classification on NISQ hardware
Jul 31, 2023


Quantum computers possess the potential to process data using a remarkably reduced number of qubits compared to conventional bits, as per theoretical foundations. However, recent experiments have indicated that the practical feasibility of retrieving an image from its quantum encoded version is currently limited to very small image sizes. Despite this constraint, variational quantum machine learning algorithms can still be employed in the current noisy intermediate scale quantum (NISQ) era. An example is a hybrid quantum machine learning approach for edge detection. In our study, we present an application of quantum transfer learning for detecting cracks in gray value images. We compare the performance and training time of PennyLane's standard qubits with IBM's qasm\_simulator and real backends, offering insights into their execution efficiency.
NLP-based Cross-Layer 5G Vulnerabilities Detection via Fuzzing Generated Run-Time Profiling
May 14, 2023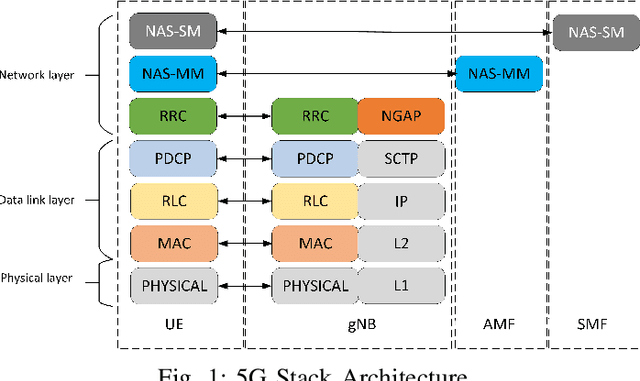
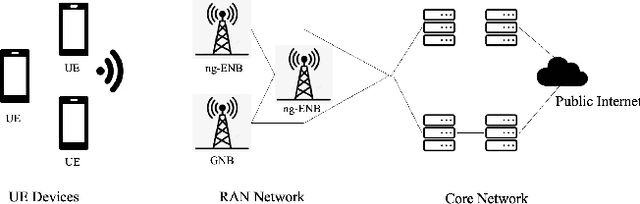
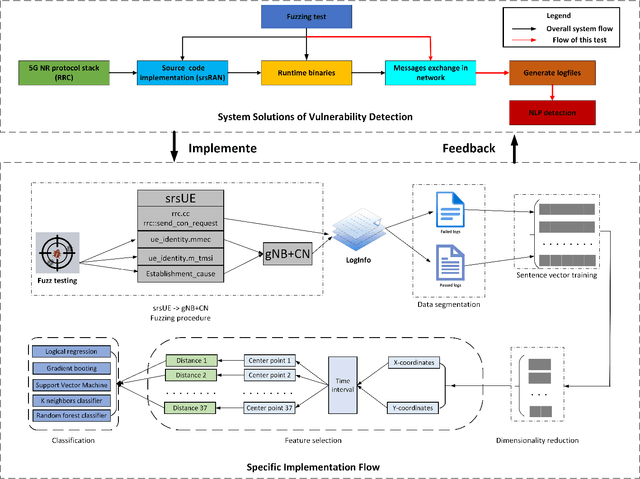
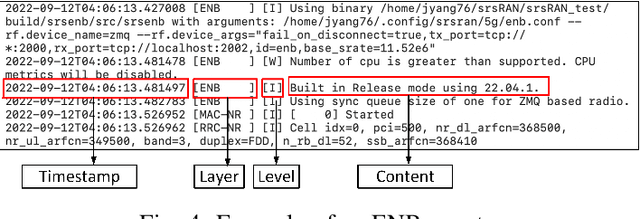
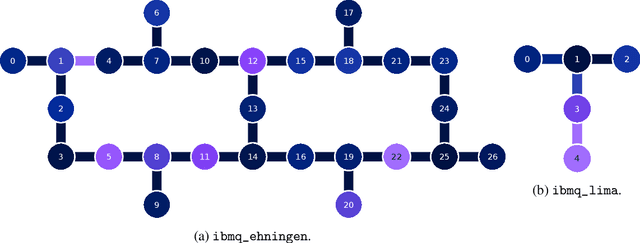
The effectiveness and efficiency of 5G software stack vulnerability and unintended behavior detection are essential for 5G assurance, especially for its applications in critical infrastructures. Scalability and automation are the main challenges in testing approaches and cybersecurity research. In this paper, we propose an innovative approach for automatically detecting vulnerabilities, unintended emergent behaviors, and performance degradation in 5G stacks via run-time profiling documents corresponding to fuzz testing in code repositories. Piloting on srsRAN, we map the run-time profiling via Logging Information (LogInfo) generated by fuzzing test to a high dimensional metric space first and then construct feature spaces based on their timestamp information. Lastly, we further leverage machine learning-based classification algorithms, including Logistic Regression, K-Nearest Neighbors, and Random Forest to categorize the impacts on performance and security attributes. The performance of the proposed approach has high accuracy, ranging from $ 93.4 \% $ to $ 95.9 \% $, in detecting the fuzzing impacts. In addition, the proof of concept could identify and prioritize real-time vulnerabilities on 5G infrastructures and critical applications in various verticals.
Explainable Parallel RCNN with Novel Feature Representation for Time Series Forecasting
May 08, 2023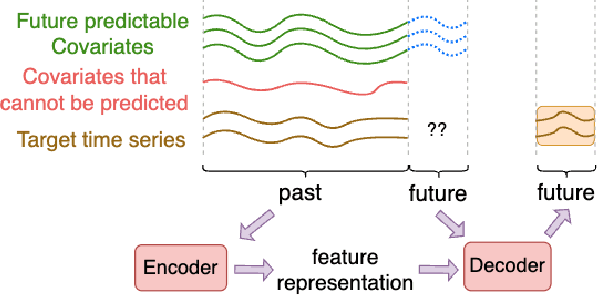
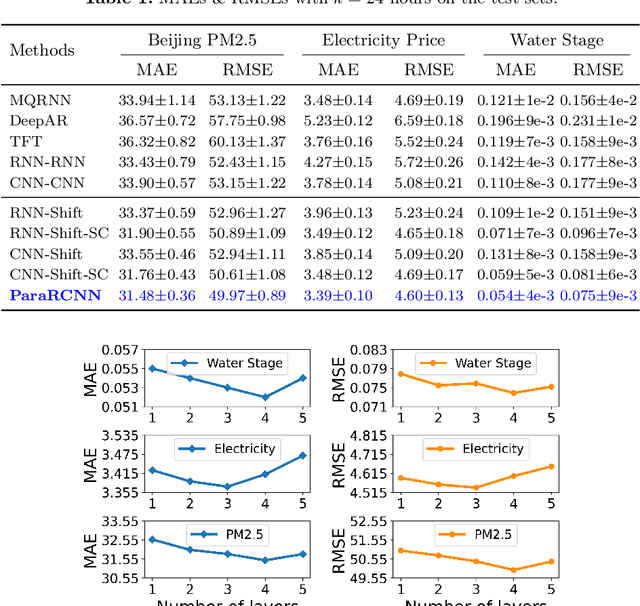
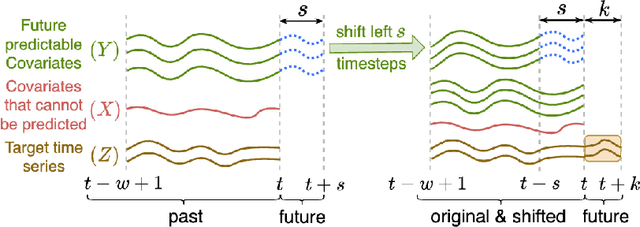
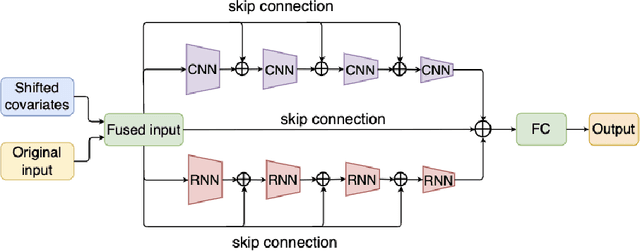
Accurate time series forecasting is a fundamental challenge in data science. It is often affected by external covariates such as weather or human intervention, which in many applications, may be predicted with reasonable accuracy. We refer to them as predicted future covariates. However, existing methods that attempt to predict time series in an iterative manner with autoregressive models end up with exponential error accumulations. Other strategies hat consider the past and future in the encoder and decoder respectively limit themselves by dealing with the historical and future data separately. To address these limitations, a novel feature representation strategy -- shifting -- is proposed to fuse the past data and future covariates such that their interactions can be considered. To extract complex dynamics in time series, we develop a parallel deep learning framework composed of RNN and CNN, both of which are used hierarchically. We also utilize the skip connection technique to improve the model's performance. Extensive experiments on three datasets reveal the effectiveness of our method. Finally, we demonstrate the model interpretability using the Grad-CAM algorithm.
Automatically measuring speech fluency in people with aphasia: first achievements using read-speech data
Aug 09, 2023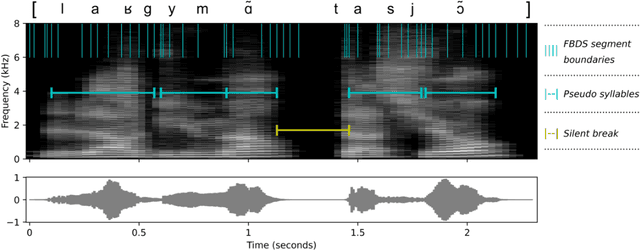
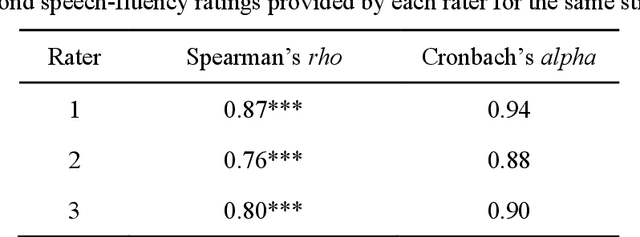

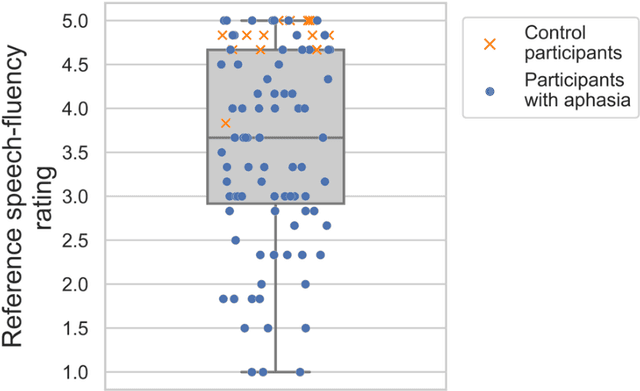
Background: Speech and language pathologists (SLPs) often relyon judgements of speech fluency for diagnosing or monitoringpatients with aphasia. However, such subjective methods havebeen criticised for their lack of reliability and their clinical cost interms of time. Aims: This study aims at assessing the relevance of a signalprocessingalgorithm, initially developed in the field of language acquisition, for the automatic measurement of speech fluency in people with aphasia (PWA). Methods & Procedures: Twenty-nine PWA and five control participantswere recruited via non-profit organizations and SLP networks. All participants were recorded while reading out loud a set ofsentences taken from the French version of the Boston Diagnostic Aphasia Examination. Three trained SLPs assessed the fluency of each sentence on a five-point qualitative scale. A forward-backward divergence segmentation and a clustering algorithm were used to compute, for each sentence, four automatic predictors of speech fluency: pseudo-syllable rate, speech ratio, rate of silent breaks, and standard deviation of pseudo-syllable length. The four predictors were finally combined into multivariate regression models (a multiplelinear regression - MLR, and two non-linear models) to predict the average SLP ratings of speech fluency, using a leave-one speaker-out validation scheme. Outcomes & Results: All models achieved accurate predictions of speech fluency ratings, with average root-mean-square errors as low as 0.5. The MLR yielded a correlation coefficient of 0.87 with reference ratings at the sentence level, and of 0.93 when aggregating the data for each participant. The inclusion of an additional predictor sensitive to repetitions improved further the predictions with a correlation coefficient of 0.91 at the sentence level, and of 0.96 at the participant level. Conclusions: The algorithms used in this study can constitute a cost-effective and reliable tool for the assessment of the speech fluency of patients with aphasia in read-aloud tasks. Perspectives for the assessment of spontaneous speech are discussed.
Advancing Early Detection of Virus Yellows: Developing a Hybrid Convolutional Neural Network for Automatic Aphid Counting in Sugar Beet Fields
Aug 09, 2023Aphids are efficient vectors to transmit virus yellows in sugar beet fields. Timely monitoring and control of their populations are thus critical to prevent the large-scale outbreak of virus yellows. However, the manual counting of aphids, which is the most common practice, is labor-intensive and time-consuming. Additionally, two of the biggest challenges in aphid counting are that aphids are small objects and their density distributions are varied in different areas of the field. To address these challenges, we proposed a hybrid automatic aphid counting network architecture which integrates the detection network and the density map estimation network. When the distribution density of aphids is low, it utilizes an improved Yolov5 to count aphids. Conversely, when the distribution density of aphids is high, its witches to CSRNet to count aphids. To the best of our knowledge, this is the first framework integrating the detection network and the density map estimation network for counting tasks. Through comparison experiments of counting aphids, it verified that our proposed approach outperforms all other methods in counting aphids. It achieved the lowest MAE and RMSE values for both the standard and high-density aphid datasets: 2.93 and 4.01 (standard), and 34.19 and 38.66 (high-density), respectively. Moreover, the AP of the improved Yolov5 is 5% higher than that of the original Yolov5. Especially for extremely small aphids and densely distributed aphids, the detection performance of the improved Yolov5 is significantly better than the original Yolov5. This work provides an effective early warning for the virus yellows risk caused by aphids in sugar beet fields, offering protection for sugar beet growth and ensuring sugar beet yield. The datasets and project code are released at: https://github.com/JunfengGaolab/Counting-Aphids.
Unsupervised Feature Based Algorithms for Time Series Extrinsic Regression
May 02, 2023
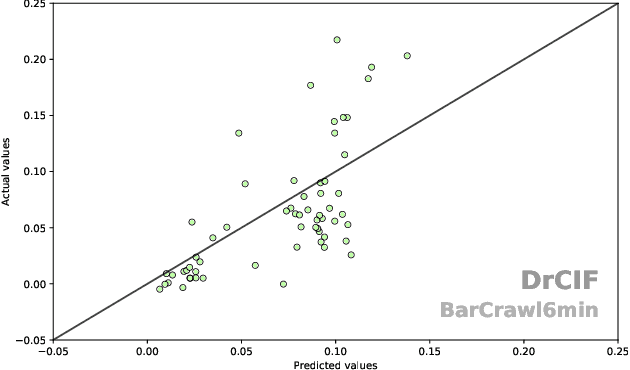
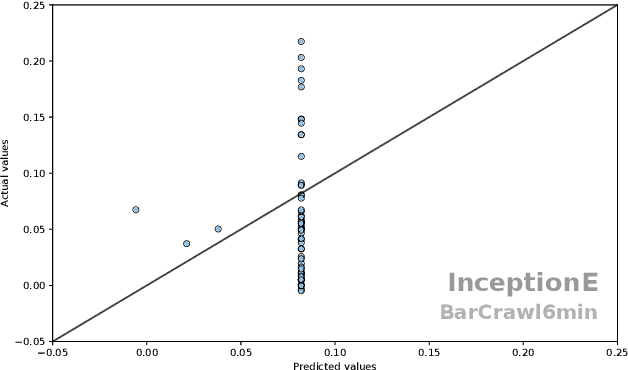
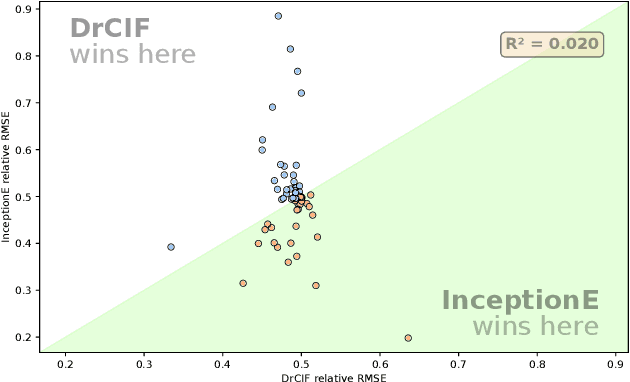
Time Series Extrinsic Regression (TSER) involves using a set of training time series to form a predictive model of a continuous response variable that is not directly related to the regressor series. The TSER archive for comparing algorithms was released in 2022 with 19 problems. We increase the size of this archive to 63 problems and reproduce the previous comparison of baseline algorithms. We then extend the comparison to include a wider range of standard regressors and the latest versions of TSER models used in the previous study. We show that none of the previously evaluated regressors can outperform a regression adaptation of a standard classifier, rotation forest. We introduce two new TSER algorithms developed from related work in time series classification. FreshPRINCE is a pipeline estimator consisting of a transform into a wide range of summary features followed by a rotation forest regressor. DrCIF is a tree ensemble that creates features from summary statistics over random intervals. Our study demonstrates that both algorithms, along with InceptionTime, exhibit significantly better performance compared to the other 18 regressors tested. More importantly, these two proposals (DrCIF and FreshPRINCE) models are the only ones that significantly outperform the standard rotation forest regressor.
Embarrassingly Simple MixUp for Time-series
Apr 09, 2023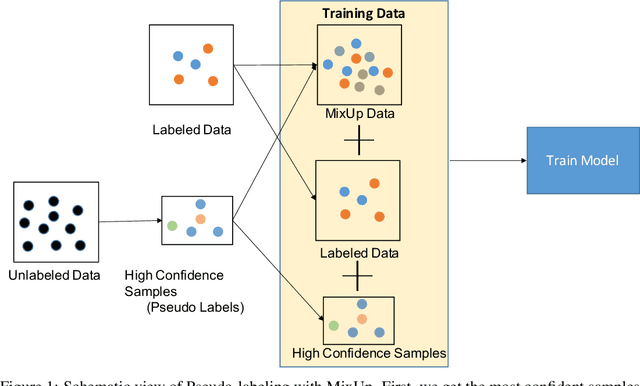
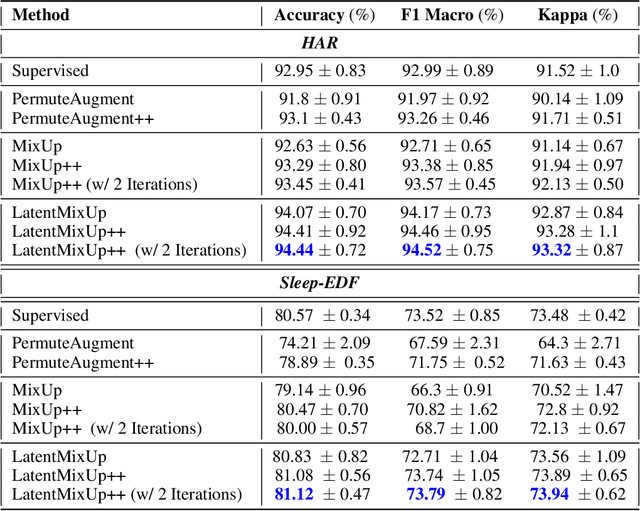
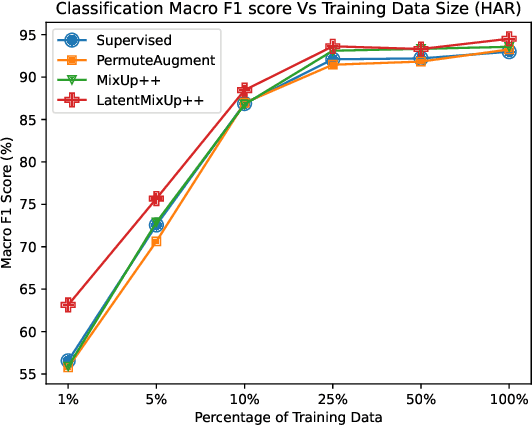
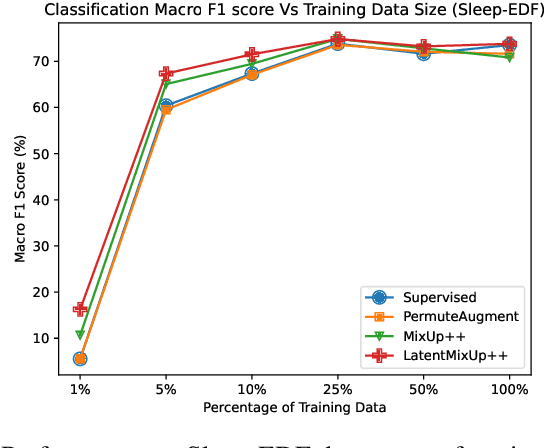
Labeling time series data is an expensive task because of domain expertise and dynamic nature of the data. Hence, we often have to deal with limited labeled data settings. Data augmentation techniques have been successfully deployed in domains like computer vision to exploit the use of existing labeled data. We adapt one of the most commonly used technique called MixUp, in the time series domain. Our proposed, MixUp++ and LatentMixUp++, use simple modifications to perform interpolation in raw time series and classification model's latent space, respectively. We also extend these methods with semi-supervised learning to exploit unlabeled data. We observe significant improvements of 1\% - 15\% on time series classification on two public datasets, for both low labeled data as well as high labeled data regimes, with LatentMixUp++.
Deep Learning Hydrodynamic Forecasting for Flooded Region Assessment in Near-Real-Time (DL Hydro-FRAN)
May 20, 2023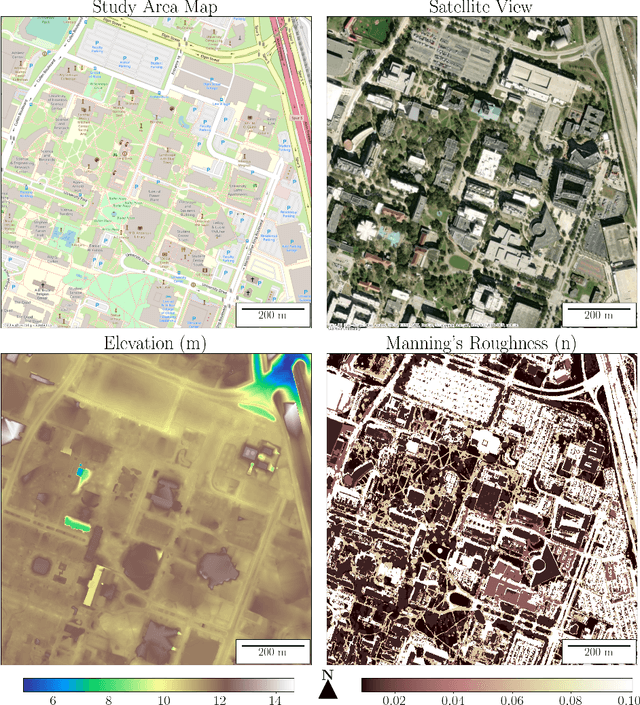
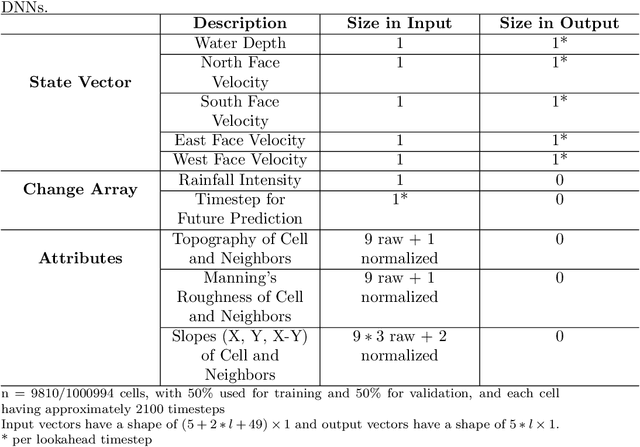
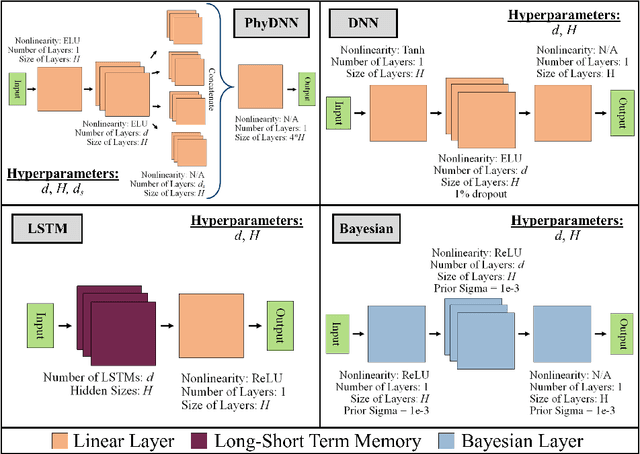
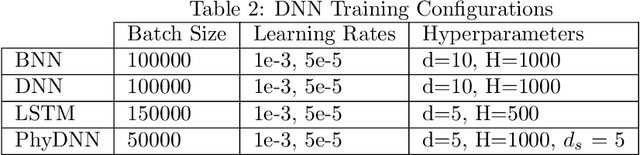
Hydrodynamic flood modeling improves hydrologic and hydraulic prediction of storm events. However, the computationally intensive numerical solutions required for high-resolution hydrodynamics have historically prevented their implementation in near-real-time flood forecasting. This study examines whether several Deep Neural Network (DNN) architectures are suitable for optimizing hydrodynamic flood models. Several pluvial flooding events were simulated in a low-relief high-resolution urban environment using a 2D HEC-RAS hydrodynamic model. These simulations were assembled into a training set for the DNNs, which were then used to forecast flooding depths and velocities. The DNNs' forecasts were compared to the hydrodynamic flood models, and showed good agreement, with a median RMSE of around 2 mm for cell flooding depths in the study area. The DNNs also improved forecast computation time significantly, with the DNNs providing forecasts between 34.2 and 72.4 times faster than conventional hydrodynamic models. The study area showed little change between HEC-RAS' Full Momentum Equations and Diffusion Equations, however, important numerical stability considerations were discovered that impact equation selection and DNN architecture configuration. Overall, the results from this study show that DNNs can greatly optimize hydrodynamic flood modeling, and enable near-real-time hydrodynamic flood forecasting.