 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcite, Attend and Segment (EASe): Domain-Agnostic Fine-Grained Mask Discovery with Feature Calibration and Self-Supervised Upsampling
Mar 31, 2026Unsupervised segmentation approaches have increasingly leveraged foundation models (FM) to improve salient object discovery. However, these methods often falter in scenes with complex, multi-component morphologies, where fine-grained structural detail is indispensable. Many state-of-the-art unsupervised segmentation pipelines rely on mask discovery approaches that utilize coarse, patch-level representations. These coarse representations inherently suppress the fine-grained detail required to resolve such complex morphologies. To overcome this limitation, we propose Excite, Attend and Segment (EASe), an unsupervised domain-agnostic semantic segmentation framework for easy fine-grained mask discovery across challenging real-world scenes. EASe utilizes novel Semantic-Aware Upsampling with Channel Excitation (SAUCE) to excite low-resolution FM feature channels for selective calibration and attends across spatially-encoded image and FM features to recover full-resolution semantic representations. Finally, EASe segments the aggregated features into multi-granularity masks using a novel training-free Cue-Attentive Feature Aggregator (CAFE) which leverages SAUCE attention scores as a semantic grouping signal. EASe, together with SAUCE and CAFE, operate directly at pixel-level feature representations to enable accurate fine-grained dense semantic mask discovery. Our evaluation demonstrates superior performance of EASe over previous state-of-the-arts (SOTAs) across major standard benchmarks and diverse datasets with complex morphologies. Code is available at https://ease-project.github.io
BridgeEQA: Virtual Embodied Agents for Real Bridge Inspections
Nov 16, 2025Deploying embodied agents that can answer questions about their surroundings in realistic real-world settings remains difficult, partly due to the scarcity of benchmarks that faithfully capture practical operating conditions. We propose infrastructure inspection as a compelling domain for open-vocabulary Embodied Question Answering (EQA): it naturally demands multi-scale reasoning, long-range spatial understanding, and complex semantic relationships, while offering unique evaluation advantages via standardized National Bridge Inventory (NBI) condition ratings (0-9), professional inspection reports, and egocentric imagery. We introduce BridgeEQA, a benchmark of 2,200 open-vocabulary question-answer pairs (in the style of OpenEQA) grounded in professional inspection reports across 200 real-world bridge scenes with 47.93 images on average per scene. Questions require synthesizing visual evidence across multiple images and aligning responses with NBI condition ratings. We further propose a new EQA metric Image Citation Relevance to evaluate the ability of a model to cite relevant images. Evaluations of state-of-the-art vision-language models reveal substantial performance gaps under episodic memory EQA settings. To address this, we propose Embodied Memory Visual Reasoning (EMVR), which formulates inspection as sequential navigation over an image-based scene graph: images are nodes, and an agent takes actions to traverse views, compare evidence, and reason within a Markov decision process. EMVR shows strong performance over the baselines. We publicly release both the dataset and code.
RAGalyst: Automated Human-Aligned Agentic Evaluation for Domain-Specific RAG
Nov 06, 2025



Retrieval-Augmented Generation (RAG) is a critical technique for grounding Large Language Models (LLMs) in factual evidence, yet evaluating RAG systems in specialized, safety-critical domains remains a significant challenge. Existing evaluation frameworks often rely on heuristic-based metrics that fail to capture domain-specific nuances and other works utilize LLM-as-a-Judge approaches that lack validated alignment with human judgment. This paper introduces RAGalyst, an automated, human-aligned agentic framework designed for the rigorous evaluation of domain-specific RAG systems. RAGalyst features an agentic pipeline that generates high-quality, synthetic question-answering (QA) datasets from source documents, incorporating an agentic filtering step to ensure data fidelity. The framework refines two key LLM-as-a-Judge metrics-Answer Correctness and Answerability-using prompt optimization to achieve a strong correlation with human annotations. Applying this framework to evaluate various RAG components across three distinct domains (military operations, cybersecurity, and bridge engineering), we find that performance is highly context-dependent. No single embedding model, LLM, or hyperparameter configuration proves universally optimal. Additionally, we provide an analysis on the most common low Answer Correctness reasons in RAG. These findings highlight the necessity of a systematic evaluation framework like RAGalyst, which empowers practitioners to uncover domain-specific trade-offs and make informed design choices for building reliable and effective RAG systems. RAGalyst is available on our Github.
ViewDelta: Text-Prompted Change Detection in Unaligned Images
Dec 10, 2024Detecting changes between images is a fundamental problem in computer vision with broad applications in situational awareness, infrastructure assessment, environment monitoring, and industrial automation. Existing supervised models are typically limited to detecting specific types of changes, necessitating retraining for new tasks. To address these limitations with a single approach, we propose a novel change detection method that is the first to utilize unaligned images and textual prompts to output a binary segmentation of changes relevant to user-provided text. Our architecture not only enables flexible detection across diverse change detection use cases, but also yields state-of-the art performance on established benchmarks. Additionally, we release an accompanying dataset comprising of 100,311 pairs of images with text prompts and the corresponding change detection labels. We demonstrate the effectiveness of our method both quantitatively and qualitatively on datasets with a wide variety of viewpoints in indoor, outdoor, street level, synthetic, and satellite images.
Multiclass Post-Earthquake Building Assessment Integrating Optical and SAR Satellite Imagery, Ground Motion, and Soil Data with Transformers
Dec 05, 2024



Timely and accurate assessments of building damage are crucial for effective response and recovery in the aftermath of earthquakes. Conventional preliminary damage assessments (PDA) often rely on manual door-to-door inspections, which are not only time-consuming but also pose significant safety risks. To safely expedite the PDA process, researchers have studied the applicability of satellite imagery processed with heuristic and machine learning approaches. These approaches output binary or, more recently, multiclass damage states at the scale of a block or a single building. However, the current performance of such approaches limits practical applicability. To address this limitation, we introduce a metadata-enriched, transformer based framework that combines high-resolution post-earthquake satellite imagery with building-specific metadata relevant to the seismic performance of the structure. Our model achieves state-of-the-art performance in multiclass post-earthquake damage identification for buildings from the Turkey-Syria earthquake on February 6, 2023. Specifically, we demonstrate that incorporating metadata, such as seismic intensity indicators, soil properties, and SAR damage proxy maps not only enhances the model's accuracy and ability to distinguish between damage classes, but also improves its generalizability across various regions. Furthermore, we conducted a detailed, class-wise analysis of feature importance to understand the model's decision-making across different levels of building damage. This analysis reveals how individual metadata features uniquely contribute to predictions for each damage class. By leveraging both satellite imagery and metadata, our proposed framework enables faster and more accurate damage assessments for precise, multiclass, building-level evaluations that can improve disaster response and accelerate recovery efforts for affected communities.
Instance Segmentation of Reinforced Concrete Bridges with Synthetic Point Clouds
Sep 24, 2024The National Bridge Inspection Standards require detailed element-level bridge inspections. Traditionally, inspectors manually assign condition ratings by rating structural components based on damage, but this process is labor-intensive and time-consuming. Automating the element-level bridge inspection process can facilitate more comprehensive condition documentation to improve overall bridge management. While semantic segmentation of bridge point clouds has been studied, research on instance segmentation of bridge elements is limited, partly due to the lack of annotated datasets, and the difficulty in generalizing trained models. To address this, we propose a novel approach for generating synthetic data using three distinct methods. Our framework leverages the Mask3D transformer model, optimized with hyperparameter tuning and a novel occlusion technique. The model achieves state-of-the-art performance on real LiDAR and photogrammetry bridge point clouds, respectively, demonstrating the potential of the framework for automating element-level bridge inspections.
Vision-Based Adaptive Robotics for Autonomous Surface Crack Repair
Jul 23, 2024

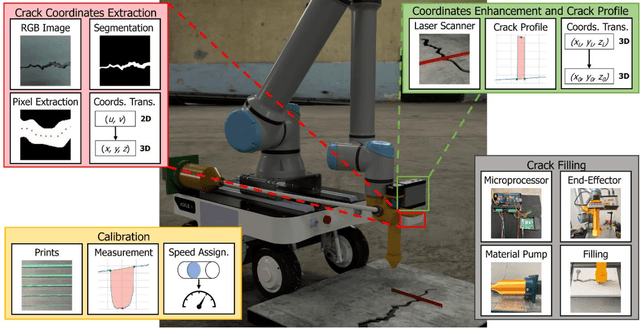
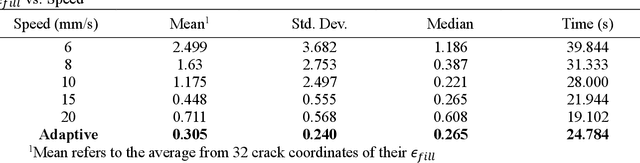
Surface cracks in infrastructure can lead to significant deterioration and costly maintenance if not efficiently repaired. Manual repair methods are labor-intensive, time-consuming, and imprecise and thus difficult to scale to large areas. Breakthroughs in robotic perception and manipulation have advanced autonomous crack repair, but proposed methods lack end-to-end testing and adaptability to changing crack size. This paper presents an adaptive, autonomous system for surface crack detection and repair using robotics with advanced sensing technologies. The system uses an RGB-D camera for crack detection, a laser scanner for precise measurement, and an extruder and pump for material deposition. A novel validation procedure with 3D-printed crack specimens simulates real-world cracks and ensures testing repeatability. Our study shows that an adaptive system for crack filling is more efficient and effective than a fixed-speed approach, with experimental results confirming precision and consistency. This research paves the way for versatile, reliable robotic infrastructure maintenance.
View-Invariant Pixelwise Anomaly Detection in Multi-object Scenes with Adaptive View Synthesis
Jun 26, 2024



The inspection and monitoring of infrastructure assets typically requires identifying visual anomalies in scenes periodically photographed over time. Images collected manually or with robots such as unmanned aerial vehicles from the same scene at different instances in time are typically not perfectly aligned. Supervised segmentation methods can be applied to identify known problems, but unsupervised anomaly detection approaches are required when unknown anomalies occur. Current unsupervised pixel-level anomaly detection methods have mainly been developed for industrial settings where the camera position is known and constant. However, we find that these methods fail to generalize to the case when images are not perfectly aligned. We term the problem of unsupervised anomaly detection between two such imperfectly aligned sets of images as Scene Anomaly Detection (Scene AD). We present a novel network termed OmniAD to address the Scene AD problem posed. Specifically, we refine the anomaly detection method reverse distillation to achieve a 40% increase in pixel-level anomaly detection performance. The network's performance is further demonstrated to improve with two new data augmentation strategies proposed that leverage novel view synthesis and camera localization to improve generalization. We validate our approach with qualitative and quantitative results on a new dataset, ToyCity, the first Scene AD dataset with multiple objects, as well as on the established single object-centric dataset, MAD. https://drags99.github.io/OmniAD/
Deep Learning Hydrodynamic Forecasting for Flooded Region Assessment in Near-Real-Time (DL Hydro-FRAN)
May 20, 2023Hydrodynamic flood modeling improves hydrologic and hydraulic prediction of storm events. However, the computationally intensive numerical solutions required for high-resolution hydrodynamics have historically prevented their implementation in near-real-time flood forecasting. This study examines whether several Deep Neural Network (DNN) architectures are suitable for optimizing hydrodynamic flood models. Several pluvial flooding events were simulated in a low-relief high-resolution urban environment using a 2D HEC-RAS hydrodynamic model. These simulations were assembled into a training set for the DNNs, which were then used to forecast flooding depths and velocities. The DNNs' forecasts were compared to the hydrodynamic flood models, and showed good agreement, with a median RMSE of around 2 mm for cell flooding depths in the study area. The DNNs also improved forecast computation time significantly, with the DNNs providing forecasts between 34.2 and 72.4 times faster than conventional hydrodynamic models. The study area showed little change between HEC-RAS' Full Momentum Equations and Diffusion Equations, however, important numerical stability considerations were discovered that impact equation selection and DNN architecture configuration. Overall, the results from this study show that DNNs can greatly optimize hydrodynamic flood modeling, and enable near-real-time hydrodynamic flood forecasting.
Automated Bridge Component Recognition using Video Data
Sep 28, 2018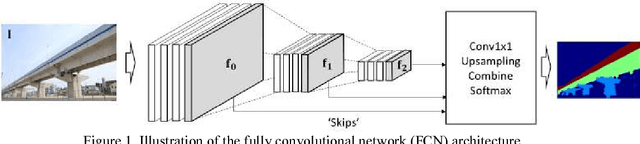
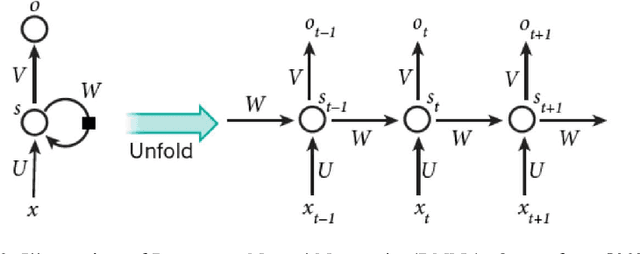
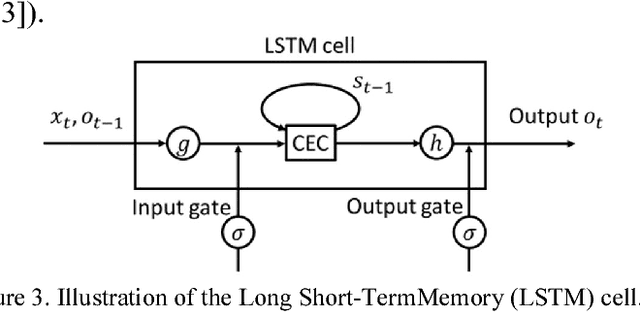
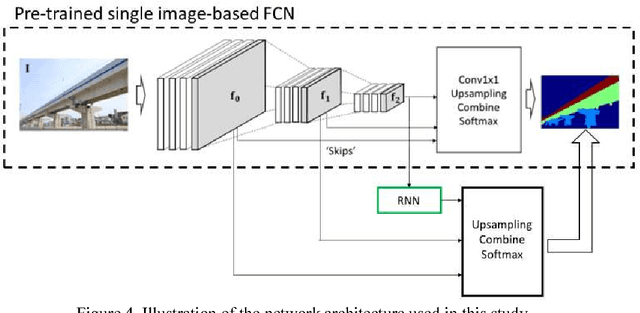
This paper investigates the automated recognition of structural bridge components using video data. Although understanding video data for structural inspections is straightforward for human inspectors, the implementation of the same task using machine learning methods has not been fully realized. In particular, single-frame image processing techniques, such as convolutional neural networks (CNNs), are not expected to identify structural components accurately when the image is a close-up view, lacking contextual information regarding where on the structure the image originates. Inspired by the significant progress in video processing techniques, this study investigates automated bridge component recognition using video data, where the information from the past frames is used to augment the understanding of the current frame. A new simulated video dataset is created to train the machine learning algorithms. Then, convolutional Neural Networks (CNNs) with recurrent architectures are designed and applied to implement the automated bridge component recognition task. Results are presented for simulated video data, as well as video collected in the field.