 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Estimating fire Duration using regression methods
Aug 17, 2023
Wildfire forecasting problems usually rely on complex grid-based mathematical models, mostly involving Computational fluid dynamics(CFD) and Celluar Automata, but these methods have always been computationally expensive and difficult to deliver a fast decision pattern. In this paper, we provide machine learning based approaches that solve the problem of high computational effort and time consumption. This paper predicts the burning duration of a known wildfire by RF(random forest), KNN, and XGBoost regression models and also image-based, like CNN and Encoder. Model inputs are based on the map of landscape features provided by satellites and the corresponding historical fire data in this area. This model is trained by happened fire data and landform feature maps and tested with the most recent real value in the same area. By processing the input differently to obtain the optimal outcome, the system is able to make fast and relatively accurate future predictions based on landscape images of known fires.
Volterra Accentuated Non-Linear Dynamical Admittance (VANYA) to model Deforestation: An Exemplification from the Amazon Rainforest
Aug 12, 2023
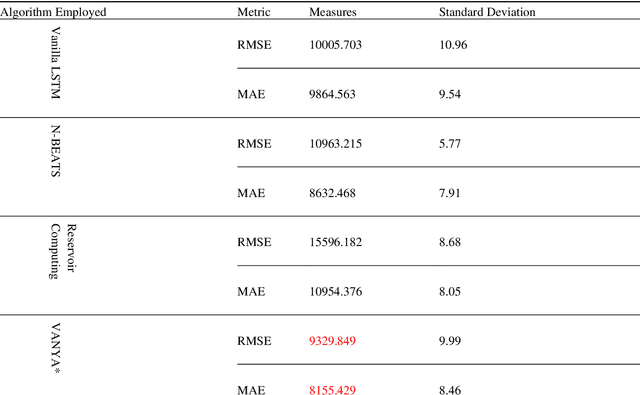
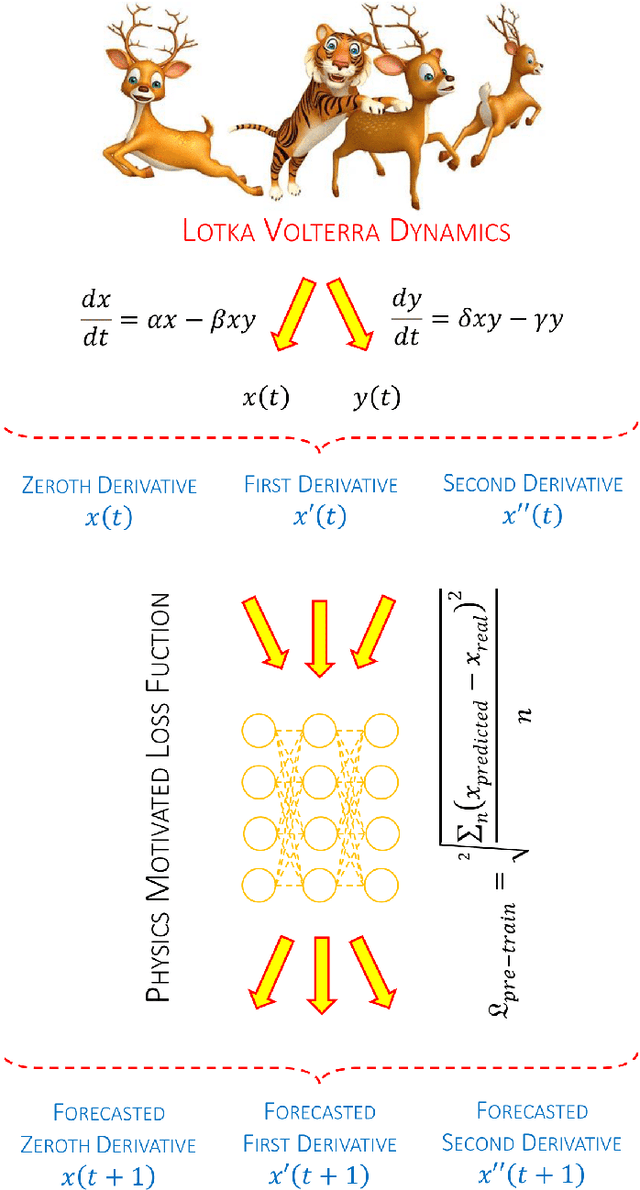
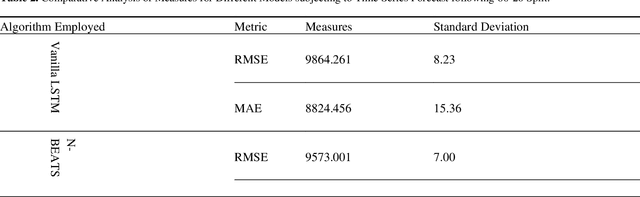
Intelligent automation supports us against cyclones, droughts, and seismic events with recent technology advancements. Algorithmic learning has advanced fields like neuroscience, genetics, and human-computer interaction. Time-series data boosts progress. Challenges persist in adopting these approaches in traditional fields. Neural networks face comprehension and bias issues. AI's expansion across scientific areas is due to adaptable descriptors and combinatorial argumentation. This article focuses on modeling Forest loss using the VANYA Model, incorporating Prey Predator Dynamics. VANYA predicts forest cover, demonstrated on Amazon Rainforest data against other forecasters like Long Short-Term Memory, N-BEATS, RCN.
Make Transformer Great Again for Time Series Forecasting: Channel Aligned Robust Dual Transformer
May 24, 2023
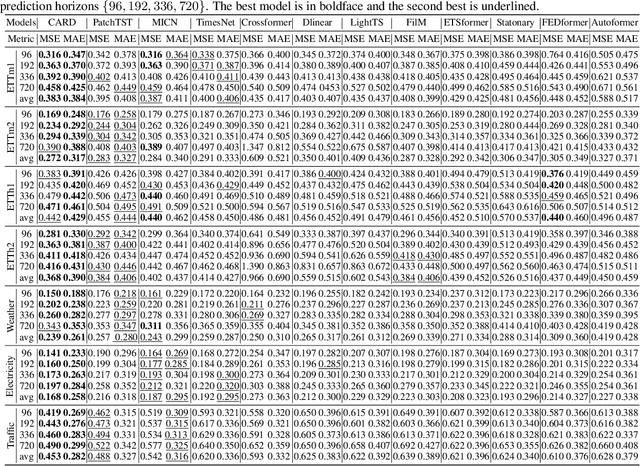
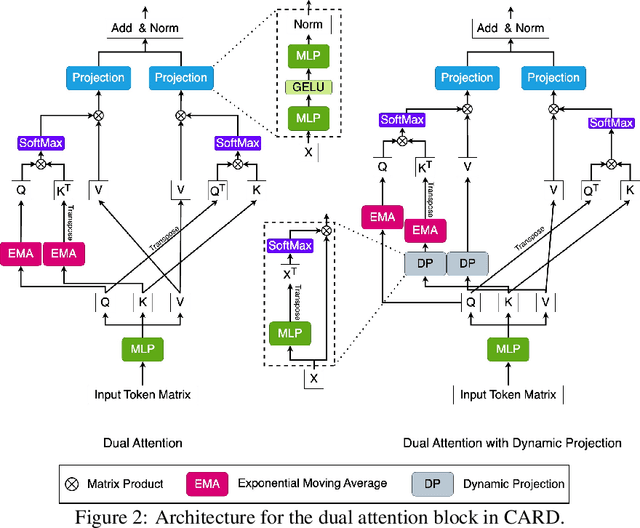
Recent studies have demonstrated the great power of deep learning methods, particularly Transformer and MLP, for time series forecasting. Despite its success in NLP and CV, many studies found that Transformer is less effective than MLP for time series forecasting. In this work, we design a special Transformer, i.e., channel-aligned robust dual Transformer (CARD for short), that addresses key shortcomings of Transformer in time series forecasting. First, CARD introduces a dual Transformer structure that allows it to capture both temporal correlations among signals and dynamical dependence among multiple variables over time. Second, we introduce a robust loss function for time series forecasting to alleviate the potential overfitting issue. This new loss function weights the importance of forecasting over a finite horizon based on prediction uncertainties. Our evaluation of multiple long-term and short-term forecasting datasets demonstrates that CARD significantly outperforms state-of-the-art time series forecasting methods, including both Transformer and MLP-based models.
CyberForce: A Federated Reinforcement Learning Framework for Malware Mitigation
Aug 11, 2023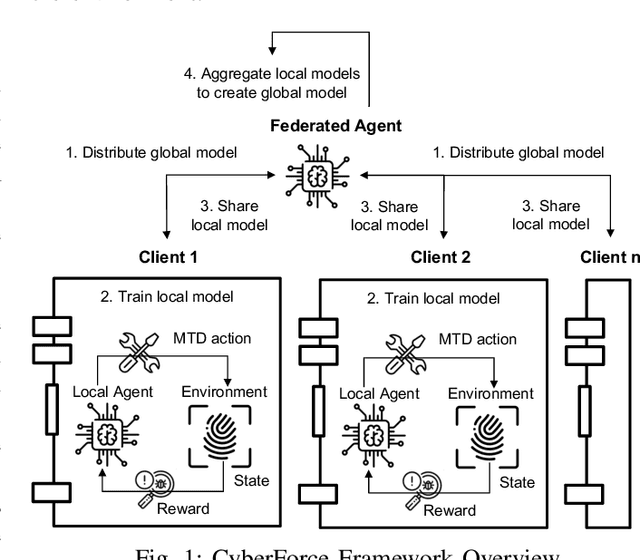
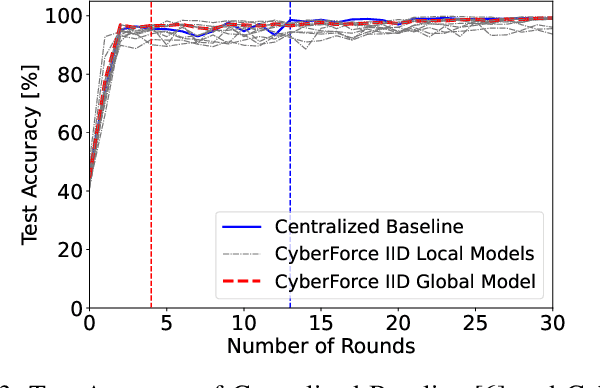
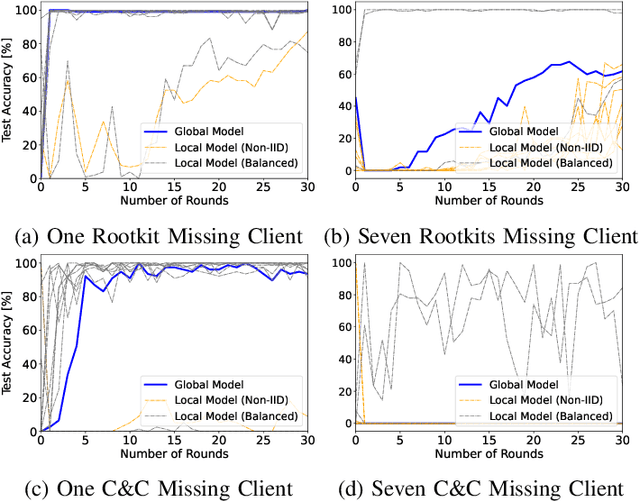
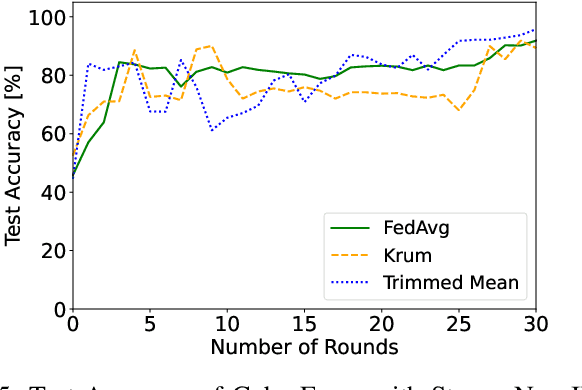
The expansion of the Internet-of-Things (IoT) paradigm is inevitable, but vulnerabilities of IoT devices to malware incidents have become an increasing concern. Recent research has shown that the integration of Reinforcement Learning with Moving Target Defense (MTD) mechanisms can enhance cybersecurity in IoT devices. Nevertheless, the numerous new malware attacks and the time that agents take to learn and select effective MTD techniques make this approach impractical for real-world IoT scenarios. To tackle this issue, this work presents CyberForce, a framework that employs Federated Reinforcement Learning (FRL) to collectively and privately determine suitable MTD techniques for mitigating diverse zero-day attacks. CyberForce integrates device fingerprinting and anomaly detection to reward or penalize MTD mechanisms chosen by an FRL-based agent. The framework has been evaluated in a federation consisting of ten devices of a real IoT platform. A pool of experiments with six malware samples affecting the devices has demonstrated that CyberForce can precisely learn optimum MTD mitigation strategies. When all clients are affected by all attacks, the FRL agent exhibits high accuracy and reduced training time when compared to a centralized RL agent. In cases where different clients experience distinct attacks, the CyberForce clients gain benefits through the transfer of knowledge from other clients and similar attack behavior. Additionally, CyberForce showcases notable robustness against data poisoning attacks.
RDumb: A simple approach that questions our progress in continual test-time adaptation
Jun 08, 2023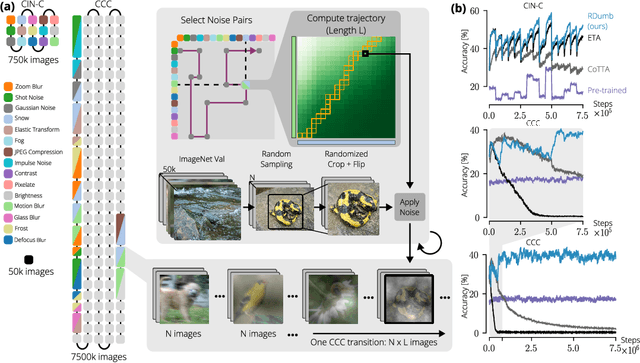
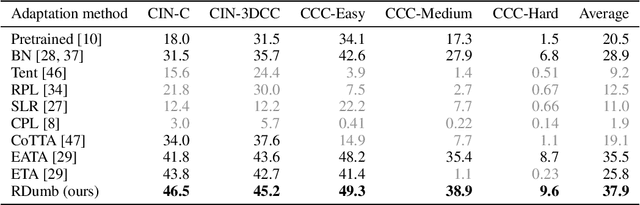
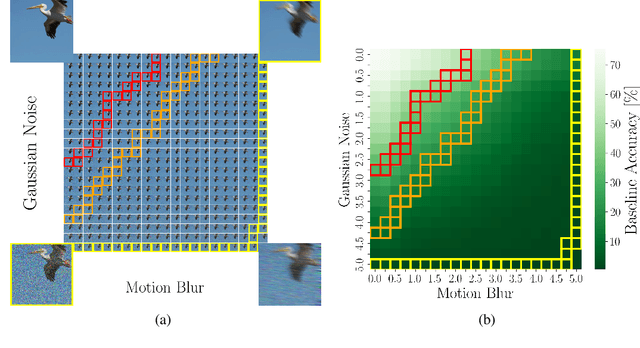
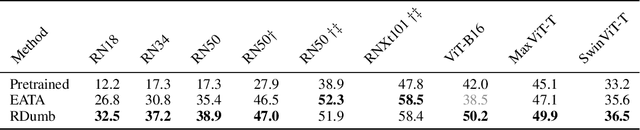
Test-Time Adaptation (TTA) allows to update pretrained models to changing data distributions at deployment time. While early work tested these algorithms for individual fixed distribution shifts, recent work proposed and applied methods for continual adaptation over long timescales. To examine the reported progress in the field, we propose the Continuously Changing Corruptions (CCC) benchmark to measure asymptotic performance of TTA techniques. We find that eventually all but one state-of-the-art methods collapse and perform worse than a non-adapting model, including models specifically proposed to be robust to performance collapse. In addition, we introduce a simple baseline, "RDumb", that periodically resets the model to its pretrained state. RDumb performs better or on par with the previously proposed state-of-the-art in all considered benchmarks. Our results show that previous TTA approaches are neither effective at regularizing adaptation to avoid collapse nor able to outperform a simplistic resetting strategy.
DNFOMP: Dynamic Neural Field Optimal Motion Planner for Navigation of Autonomous Robots in Cluttered Environment
Aug 07, 2023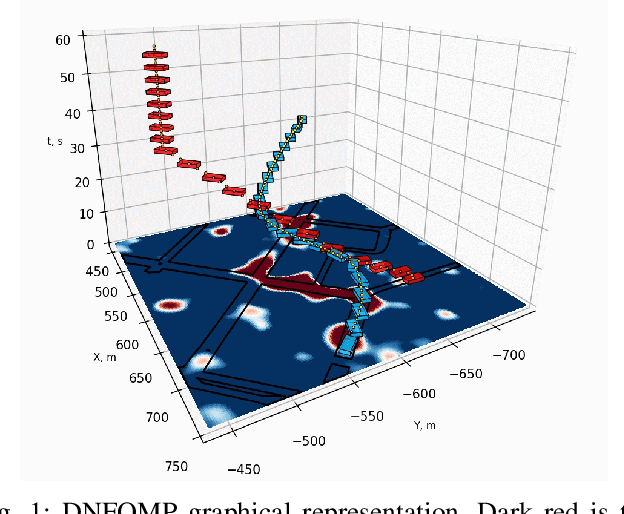
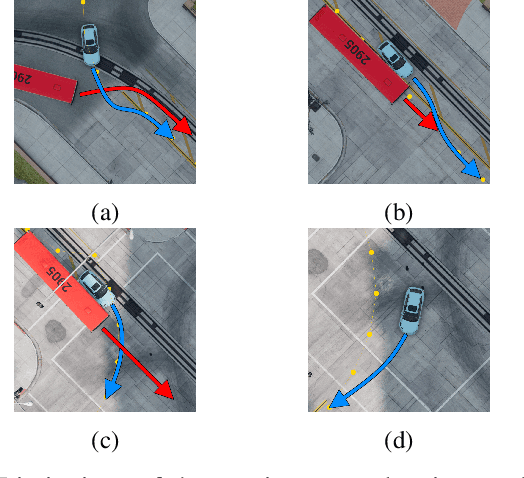
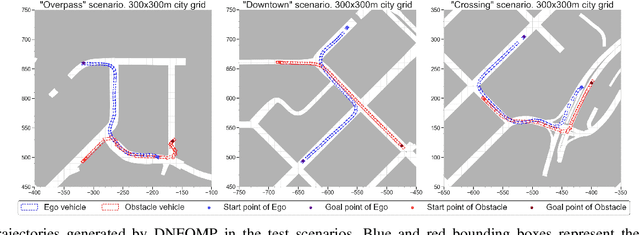
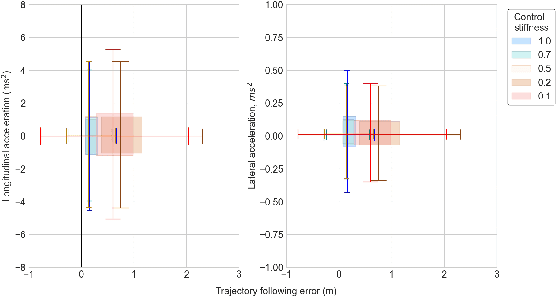
Motion planning in dynamically changing environments is one of the most complex challenges in autonomous driving. Safety is a crucial requirement, along with driving comfort and speed limits. While classical sampling-based, lattice-based, and optimization-based planning methods can generate smooth and short paths, they often do not consider the dynamics of the environment. Some techniques do consider it, but they rely on updating the environment on-the-go rather than explicitly accounting for the dynamics, which is not suitable for self-driving. To address this, we propose a novel method based on the Neural Field Optimal Motion Planner (NFOMP), which outperforms state-of-the-art approaches in terms of normalized curvature and the number of cusps. Our approach embeds previously known moving obstacles into the neural field collision model to account for the dynamics of the environment. We also introduce time profiling of the trajectory and non-linear velocity constraints by adding Lagrange multipliers to the trajectory loss function. We applied our method to solve the optimal motion planning problem in an urban environment using the BeamNG.tech driving simulator. An autonomous car drove the generated trajectories in three city scenarios while sharing the road with the obstacle vehicle. Our evaluation shows that the maximum acceleration the passenger can experience instantly is -7.5 m/s^2 and that 89.6% of the driving time is devoted to normal driving with accelerations below 3.5 m/s^2. The driving style is characterized by 46.0% and 31.4% of the driving time being devoted to the light rail transit style and the moderate driving style, respectively.
InverseSR: 3D Brain MRI Super-Resolution Using a Latent Diffusion Model
Aug 23, 2023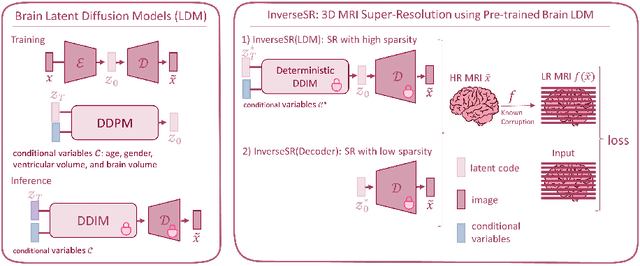
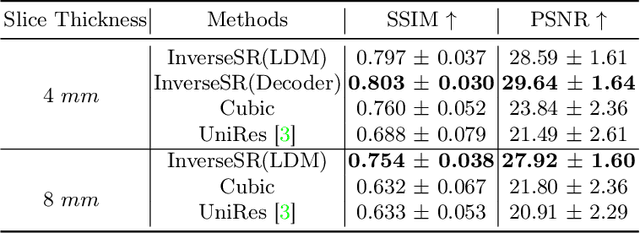
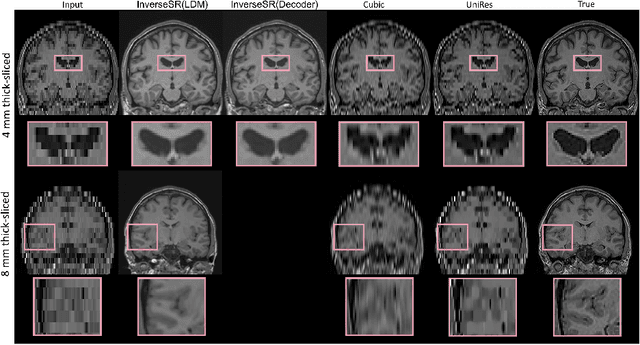
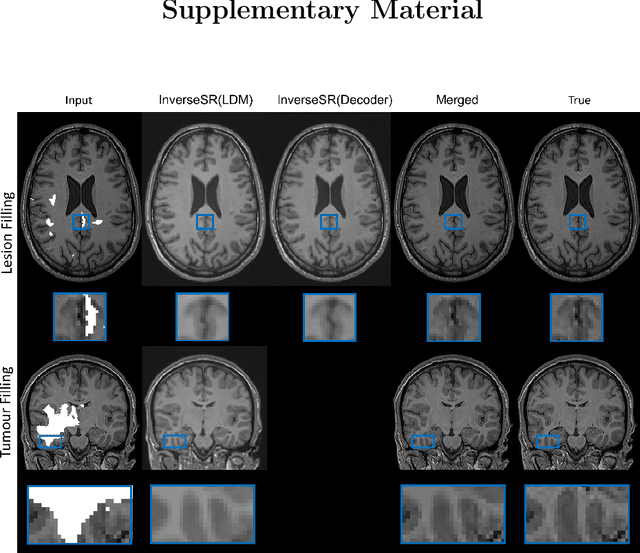
High-resolution (HR) MRI scans obtained from research-grade medical centers provide precise information about imaged tissues. However, routine clinical MRI scans are typically in low-resolution (LR) and vary greatly in contrast and spatial resolution due to the adjustments of the scanning parameters to the local needs of the medical center. End-to-end deep learning methods for MRI super-resolution (SR) have been proposed, but they require re-training each time there is a shift in the input distribution. To address this issue, we propose a novel approach that leverages a state-of-the-art 3D brain generative model, the latent diffusion model (LDM) trained on UK BioBank, to increase the resolution of clinical MRI scans. The LDM acts as a generative prior, which has the ability to capture the prior distribution of 3D T1-weighted brain MRI. Based on the architecture of the brain LDM, we find that different methods are suitable for different settings of MRI SR, and thus propose two novel strategies: 1) for SR with more sparsity, we invert through both the decoder of the LDM and also through a deterministic Denoising Diffusion Implicit Models (DDIM), an approach we will call InverseSR(LDM); 2) for SR with less sparsity, we invert only through the LDM decoder, an approach we will call InverseSR(Decoder). These two approaches search different latent spaces in the LDM model to find the optimal latent code to map the given LR MRI into HR. The training process of the generative model is independent of the MRI under-sampling process, ensuring the generalization of our method to many MRI SR problems with different input measurements. We validate our method on over 100 brain T1w MRIs from the IXI dataset. Our method can demonstrate that powerful priors given by LDM can be used for MRI reconstruction.
Sample Complexity of Robust Learning against Evasion Attacks
Aug 23, 2023It is becoming increasingly important to understand the vulnerability of machine learning models to adversarial attacks. One of the fundamental problems in adversarial machine learning is to quantify how much training data is needed in the presence of evasion attacks, where data is corrupted at test time. In this thesis, we work with the exact-in-the-ball notion of robustness and study the feasibility of adversarially robust learning from the perspective of learning theory, considering sample complexity. We first explore the setting where the learner has access to random examples only, and show that distributional assumptions are essential. We then focus on learning problems with distributions on the input data that satisfy a Lipschitz condition and show that robustly learning monotone conjunctions has sample complexity at least exponential in the adversary's budget (the maximum number of bits it can perturb on each input). However, if the adversary is restricted to perturbing $O(\log n)$ bits, then one can robustly learn conjunctions and decision lists w.r.t. log-Lipschitz distributions. We then study learning models where the learner is given more power. We first consider local membership queries, where the learner can query the label of points near the training sample. We show that, under the uniform distribution, the exponential dependence on the adversary's budget to robustly learn conjunctions remains inevitable. We then introduce a local equivalence query oracle, which returns whether the hypothesis and target concept agree in a given region around a point in the training sample, and a counterexample if it exists. We show that if the query radius is equal to the adversary's budget, we can develop robust empirical risk minimization algorithms in the distribution-free setting. We give general query complexity upper and lower bounds, as well as for concrete concept classes.
AutoML4ETC: Automated Neural Architecture Search for Real-World Encrypted Traffic Classification
Aug 04, 2023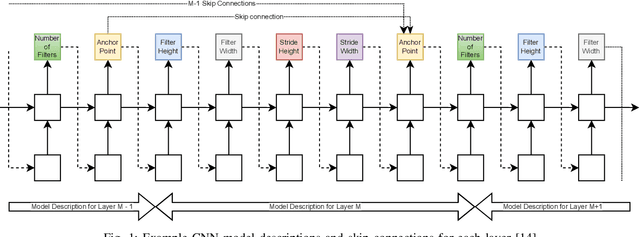
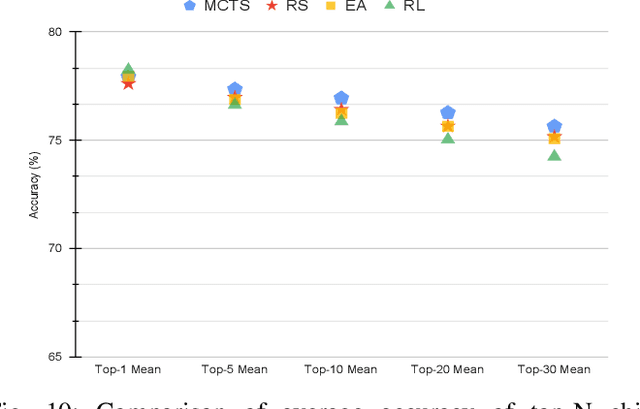
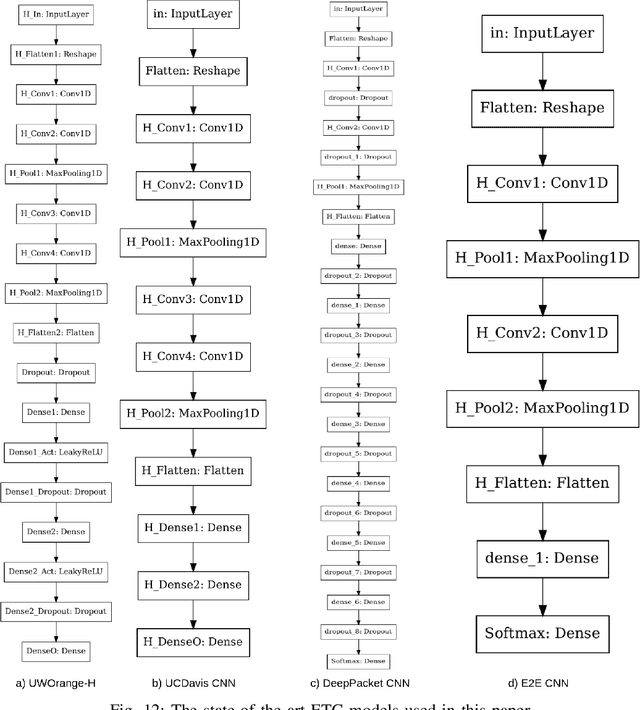
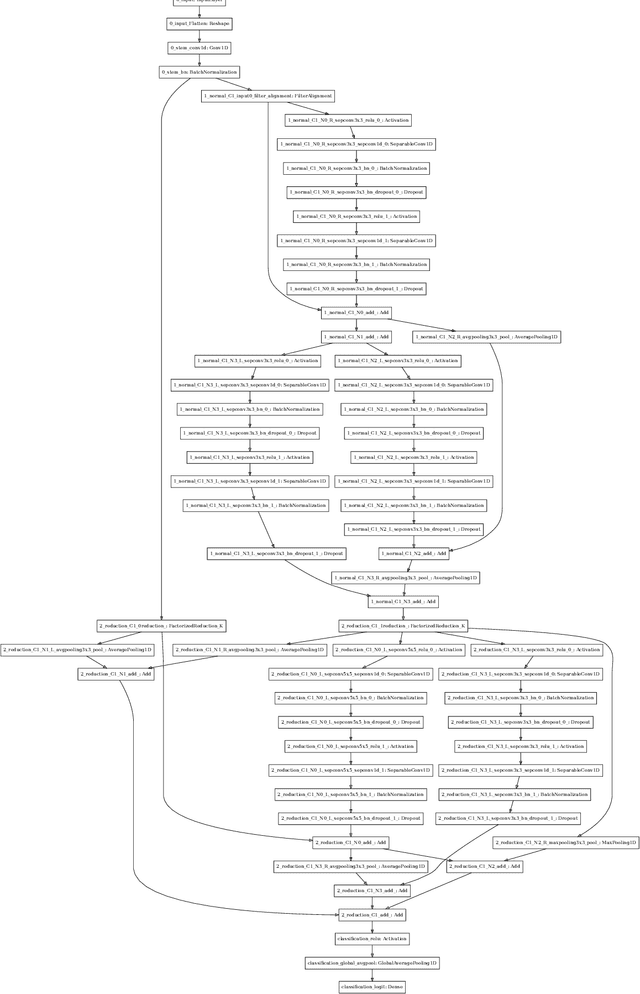
Deep learning (DL) has been successfully applied to encrypted network traffic classification in experimental settings. However, in production use, it has been shown that a DL classifier's performance inevitably decays over time. Re-training the model on newer datasets has been shown to only partially improve its performance. Manually re-tuning the model architecture to meet the performance expectations on newer datasets is time-consuming and requires domain expertise. We propose AutoML4ETC, a novel tool to automatically design efficient and high-performing neural architectures for encrypted traffic classification. We define a novel, powerful search space tailored specifically for the near real-time classification of encrypted traffic using packet header bytes. We show that with different search strategies over our search space, AutoML4ETC generates neural architectures that outperform the state-of-the-art encrypted traffic classifiers on several datasets, including public benchmark datasets and real-world TLS and QUIC traffic collected from the Orange mobile network. In addition to being more accurate, AutoML4ETC's architectures are significantly more efficient and lighter in terms of the number of parameters. Finally, we make AutoML4ETC publicly available for future research.
Interferometric speckle visibility spectroscopy (iSVS) for measuring decorrelation time and dynamics of moving samples with enhanced signal-to-noise ratio and relaxed reference requirements
Jun 30, 2023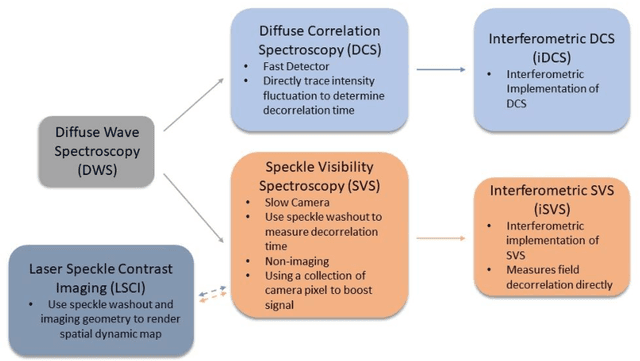
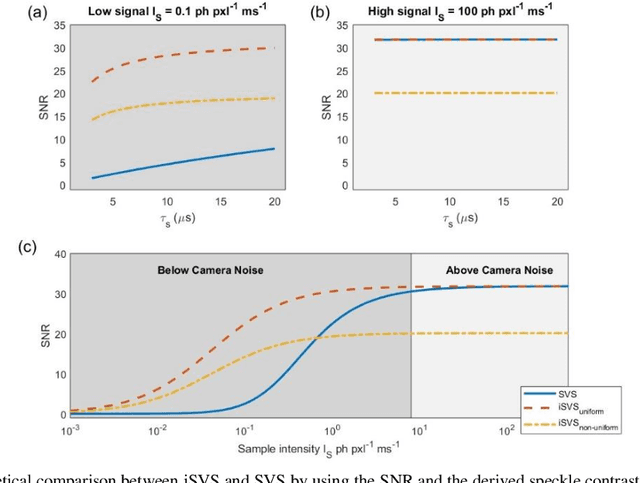
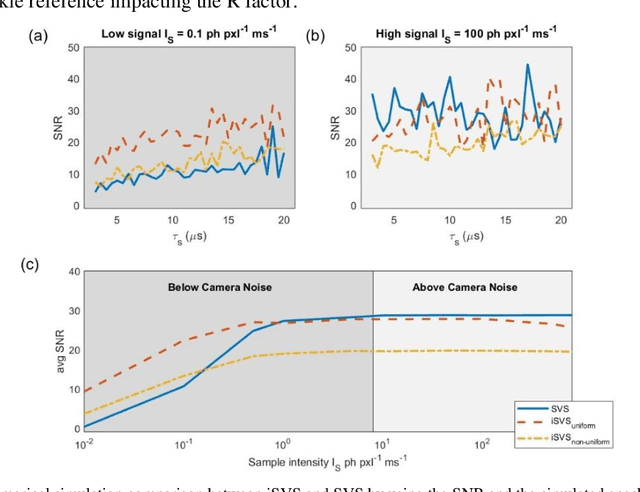
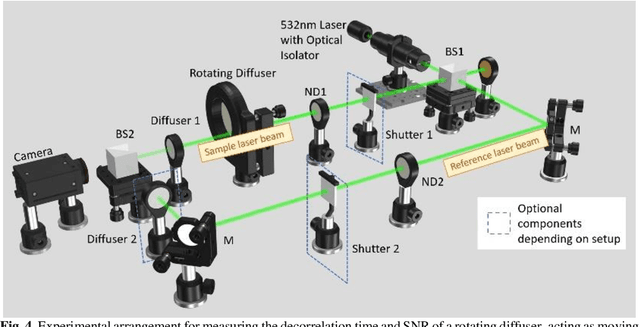
Diffusing wave spectroscopy (DWS) is a group of techniques used to measure the dynamics of a scattering medium in a non-invasive manner. DWS methods rely on detecting the speckle light field from the moving scattering media and measuring the speckle decorrelation time to quantify the scattering mediums dynamics. For DWS, the signal-to-noise (SNR) is determined by the ratio between measured decorrelation time to the standard error of the measurement. This SNR is often low in certain applications because of high noise variances and low signal intensity, especially in biological applications with restricted exposure and emission levels. To address this photon-limited signal-to-noise ratio problem, we investigated, theoretically and experimentally, the SNR of an interferometric speckle visibility spectroscopy (iSVS) compared to more traditional DWS methods. We found that iSVS can provide excellent SNR performance through its ability to overcome camera noise. We also proved iSVS system has more relaxed constraints on the reference beam properties than most other interferometric systems. For an iSVS to function properly, we simply require the reference beam to exhibit local temporal stability, while incident angle, reference phase, and intensity uniformity do not need to be constrained. This flexibility can potentially enable more unconventional iSVS implementation schemes.