 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FedGeo: Privacy-Preserving User Next Location Prediction with Federated Learning
Dec 06, 2023
A User Next Location Prediction (UNLP) task, which predicts the next location that a user will move to given his/her trajectory, is an indispensable task for a wide range of applications. Previous studies using large-scale trajectory datasets in a single server have achieved remarkable performance in UNLP task. However, in real-world applications, legal and ethical issues have been raised regarding privacy concerns leading to restrictions against sharing human trajectory datasets to any other server. In response, Federated Learning (FL) has emerged to address the personal privacy issue by collaboratively training multiple clients (i.e., users) and then aggregating them. While previous studies employed FL for UNLP, they are still unable to achieve reliable performance because of the heterogeneity of clients' mobility. To tackle this problem, we propose the Federated Learning for Geographic Information (FedGeo), a FL framework specialized for UNLP, which alleviates the heterogeneity of clients' mobility and guarantees personal privacy protection. Firstly, we incorporate prior global geographic adjacency information to the local client model, since the spatial correlation between locations is trained partially in each client who has only a heterogeneous subset of the overall trajectories in FL. We also introduce a novel aggregation method that minimizes the gap between client models to solve the problem of client drift caused by differences between client models when learning with their heterogeneous data. Lastly, we probabilistically exclude clients with extremely heterogeneous data from the FL process by focusing on clients who visit relatively diverse locations. We show that FedGeo is superior to other FL methods for model performance in UNLP task. We also validated our model in a real-world application using our own customers' mobile phones and the FL agent system.
TransGlow: Attention-augmented Transduction model based on Graph Neural Networks for Water Flow Forecasting
Dec 10, 2023The hydrometric prediction of water quantity is useful for a variety of applications, including water management, flood forecasting, and flood control. However, the task is difficult due to the dynamic nature and limited data of water systems. Highly interconnected water systems can significantly affect hydrometric forecasting. Consequently, it is crucial to develop models that represent the relationships between other system components. In recent years, numerous hydrological applications have been studied, including streamflow prediction, flood forecasting, and water quality prediction. Existing methods are unable to model the influence of adjacent regions between pairs of variables. In this paper, we propose a spatiotemporal forecasting model that augments the hidden state in Graph Convolution Recurrent Neural Network (GCRN) encoder-decoder using an efficient version of the attention mechanism. The attention layer allows the decoder to access different parts of the input sequence selectively. Since water systems are interconnected and the connectivity information between the stations is implicit, the proposed model leverages a graph learning module to extract a sparse graph adjacency matrix adaptively based on the data. Spatiotemporal forecasting relies on historical data. In some regions, however, historical data may be limited or incomplete, making it difficult to accurately predict future water conditions. Further, we present a new benchmark dataset of water flow from a network of Canadian stations on rivers, streams, and lakes. Experimental results demonstrate that our proposed model TransGlow significantly outperforms baseline methods by a wide margin.
CODEX: A Cluster-Based Method for Explainable Reinforcement Learning
Dec 07, 2023Despite the impressive feats demonstrated by Reinforcement Learning (RL), these algorithms have seen little adoption in high-risk, real-world applications due to current difficulties in explaining RL agent actions and building user trust. We present Counterfactual Demonstrations for Explanation (CODEX), a method that incorporates semantic clustering, which can effectively summarize RL agent behavior in the state-action space. Experimentation on the MiniGrid and StarCraft II gaming environments reveals the semantic clusters retain temporal as well as entity information, which is reflected in the constructed summary of agent behavior. Furthermore, clustering the discrete+continuous game-state latent representations identifies the most crucial episodic events, demonstrating a relationship between the latent and semantic spaces. This work contributes to the growing body of work that strives to unlock the power of RL for widespread use by leveraging and extending techniques from Natural Language Processing.
Constrained Hierarchical Clustering via Graph Coarsening and Optimal Cuts
Dec 07, 2023Motivated by extracting and summarizing relevant information in short sentence settings, such as satisfaction questionnaires, hotel reviews, and X/Twitter, we study the problem of clustering words in a hierarchical fashion. In particular, we focus on the problem of clustering with horizontal and vertical structural constraints. Horizontal constraints are typically cannot-link and must-link among words, while vertical constraints are precedence constraints among cluster levels. We overcome state-of-the-art bottlenecks by formulating the problem in two steps: first, as a soft-constrained regularized least-squares which guides the result of a sequential graph coarsening algorithm towards the horizontal feasible set. Then, flat clusters are extracted from the resulting hierarchical tree by computing optimal cut heights based on the available constraints. We show that the resulting approach compares very well with respect to existing algorithms and is computationally light.
Multi-strategy Collaborative Optimized YOLOv5s and its Application in Distance Estimation
Dec 07, 2023The increasing accident rate brought about by the explosive growth of automobiles has made the research on active safety systems of automobiles increasingly important. The importance of improving the accuracy of vehicle target detection is self-evident. To achieve the goals of vehicle detection and distance estimation and provide safety warnings, a Distance Estimation Safety Warning System (DESWS) based on a new neural network model (YOLOv5s-SE) by replacing the IoU with DIoU, embedding SE attention module, and a distance estimation method through using the principle of similar triangles was proposed. In addition, a method that can give safety suggestions based on the estimated distance using nonparametric testing was presented in this work. Through the simulation experiment, it was verified that the mAP was improved by 5.5% and the purpose of giving safety suggestions based on the estimated distance information can be achieved.
HierCas: Hierarchical Temporal Graph Attention Networks for Popularity Prediction in Information Cascades
Oct 20, 2023Information cascade popularity prediction is critical for many applications, including but not limited to identifying fake news and accurate recommendations. Traditional feature-based methods heavily rely on handcrafted features, which are domain-specific and lack generalizability to new domains. To address this problem, researchers have turned to neural network-based approaches. However, existing methods follow a sampling-based modeling approach, potentially losing continuous dynamic information and structural-temporal dependencies that emerge during the information diffusion process. In this paper, we propose a novel framework called Hierarchical Temporal Graph Attention Networks for cascade popularity prediction (HierCas). Unlike existing methods, HierCas operates on the entire cascade graph by a dynamic graph modeling approach, enabling it to capture the full range of continuous dynamic information and explicitly model the interplay between structural and temporal factors. By leveraging time-aware node embedding, graph attention mechanisms and hierarchical pooling structures, HierCas effectively captures the popularity trend implicit in the complex cascade. Extensive experiments conducted on two real-world datasets in different scenarios demonstrate that our HierCas significantly outperforms the state-of-the-art approaches.
IndoorGNN: A Graph Neural Network based approach for Indoor Localization using WiFi RSSI
Dec 11, 2023Indoor localization is the process of determining the location of a person or object inside a building. Potential usage of indoor localization includes navigation, personalization, safety and security, and asset tracking. Commonly used technologies for indoor localization include WiFi, Bluetooth, RFID, and Ultra-wideband. Among these, WiFi's Received Signal Strength Indicator (RSSI)-based localization is preferred because of widely available WiFi Access Points (APs). We have two main contributions. First, we develop our method, 'IndoorGNN' which involves using a Graph Neural Network (GNN) based algorithm in a supervised manner to classify a specific location into a particular region based on the RSSI values collected at that location. Most of the ML algorithms that perform this classification require a large number of labeled data points (RSSI vectors with location information). Collecting such data points is a labor-intensive and time-consuming task. To overcome this challenge, as our second contribution, we demonstrate the performance of IndoorGNN on the restricted dataset. It shows a comparable prediction accuracy to that of the complete dataset. We performed experiments on the UJIIndoorLoc and MNAV datasets, which are real-world standard indoor localization datasets. Our experiments show that IndoorGNN gives better location prediction accuracies when compared with state-of-the-art existing conventional as well as GNN-based methods for this same task. It continues to outperform these algorithms even with restricted datasets. It is noteworthy that its performance does not decrease a lot with a decrease in the number of available data points. Our method can be utilized for navigation and wayfinding in complex indoor environments, asset tracking and building management, enhancing mobile applications with location-based services, and improving safety and security during emergencies.
Context Retrieval via Normalized Contextual Latent Interaction for Conversational Agent
Dec 01, 2023Conversational agents leveraging AI, particularly deep learning, are emerging in both academic research and real-world applications. However, these applications still face challenges, including disrespecting knowledge and facts, not personalizing to user preferences, and enormous demand for computational resources during training and inference. Recent research efforts have been focused on addressing these challenges from various aspects, including supplementing various types of auxiliary information to the conversational agents. However, existing methods are still not able to effectively and efficiently exploit relevant information from these auxiliary supplements to further unleash the power of the conversational agents and the language models they use. In this paper, we present a novel method, PK-NCLI, that is able to accurately and efficiently identify relevant auxiliary information to improve the quality of conversational responses by learning the relevance among persona, chat history, and knowledge background through low-level normalized contextual latent interaction. Our experimental results indicate that PK-NCLI outperforms the state-of-the-art method, PK-FoCus, by 47.80%/30.61%/24.14% in terms of perplexity, knowledge grounding, and training efficiency, respectively, and maintained the same level of persona grounding performance. We also provide a detailed analysis of how different factors, including language model choices and trade-offs on training weights, would affect the performance of PK-NCLI.
Backbone-based Dynamic Graph Spatio-Temporal Network for Epidemic Forecasting
Dec 01, 2023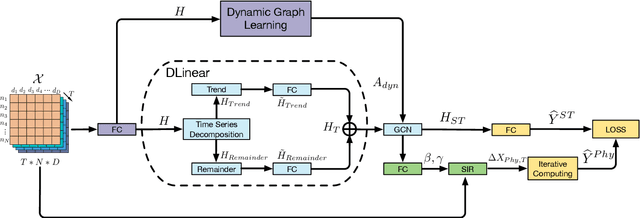

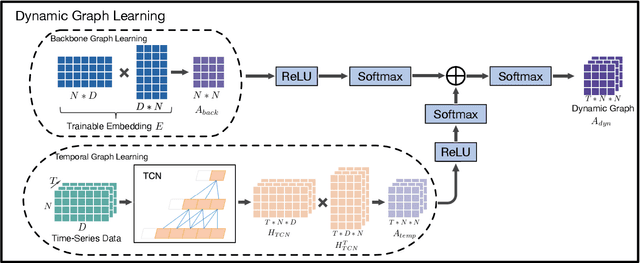
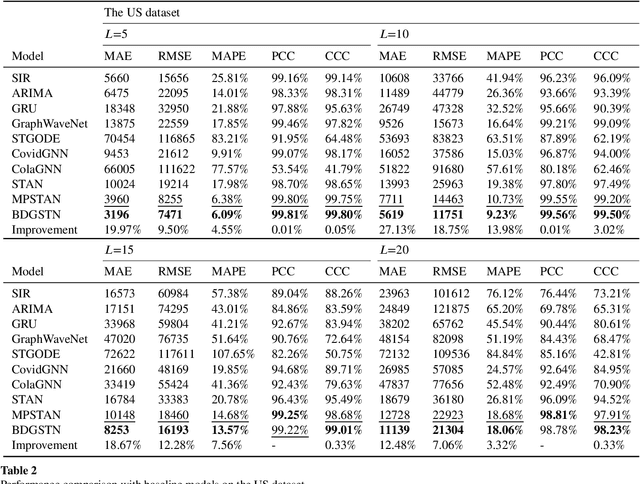
Accurate epidemic forecasting is a critical task in controlling disease transmission. Many deep learning-based models focus only on static or dynamic graphs when constructing spatial information, ignoring their relationship. Additionally, these models often rely on recurrent structures, which can lead to error accumulation and computational time consumption. To address the aforementioned problems, we propose a novel model called Backbone-based Dynamic Graph Spatio-Temporal Network (BDGSTN). Intuitively, the continuous and smooth changes in graph structure, make adjacent graph structures share a basic pattern. To capture this property, we use adaptive methods to generate static backbone graphs containing the primary information and temporal models to generate dynamic temporal graphs of epidemic data, fusing them to generate a backbone-based dynamic graph. To overcome potential limitations associated with recurrent structures, we introduce a linear model DLinear to handle temporal dependencies and combine it with dynamic graph convolution for epidemic forecasting. Extensive experiments on two datasets demonstrate that BDGSTN outperforms baseline models and ablation comparison further verifies the effectiveness of model components. Furthermore, we analyze and measure the significance of backbone and temporal graphs by using information metrics from different aspects. Finally, we compare model parameter volume and training time to confirm the superior complexity and efficiency of BDGSTN.
Multi-source domain adaptation for regression
Dec 09, 2023Multi-source domain adaptation (DA) aims at leveraging information from more than one source domain to make predictions in a target domain, where different domains may have different data distributions. Most existing methods for multi-source DA focus on classification problems while there is only limited investigation in the regression settings. In this paper, we fill in this gap through a two-step procedure. First, we extend a flexible single-source DA algorithm for classification through outcome-coarsening to enable its application to regression problems. We then augment our single-source DA algorithm for regression with ensemble learning to achieve multi-source DA. We consider three learning paradigms in the ensemble algorithm, which combines linearly the target-adapted learners trained with each source domain: (i) a multi-source stacking algorithm to obtain the ensemble weights; (ii) a similarity-based weighting where the weights reflect the quality of DA of each target-adapted learner; and (iii) a combination of the stacking and similarity weights. We illustrate the performance of our algorithms with simulations and a data application where the goal is to predict High-density lipoprotein (HDL) cholesterol levels using gut microbiome. We observe a consistent improvement in prediction performance of our multi-source DA algorithm over the routinely used methods in all these scenarios.