 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Classifying vaccine sentiment tweets by modelling domain-specific representation and commonsense knowledge into context-aware attentive GRU
Jun 17, 2021

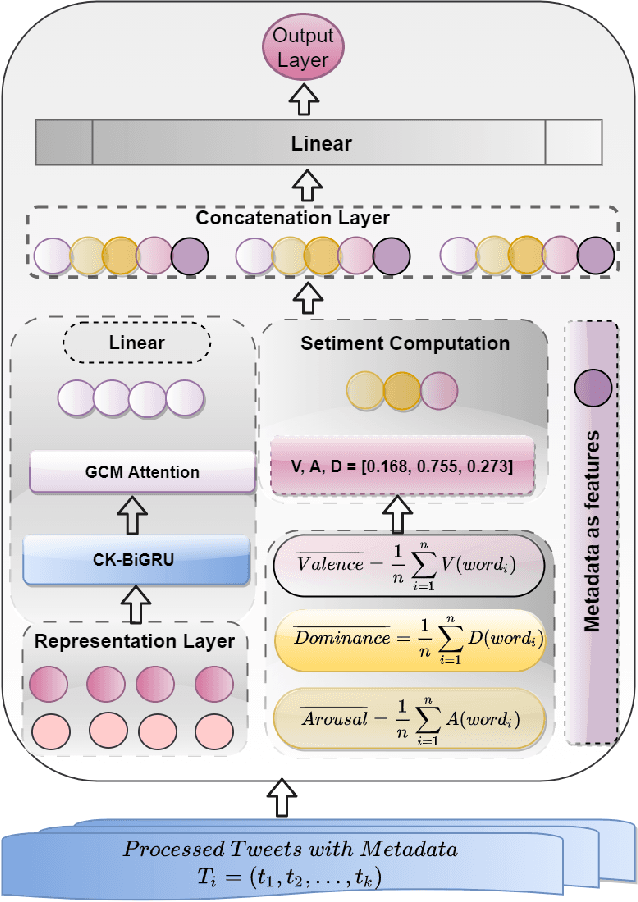
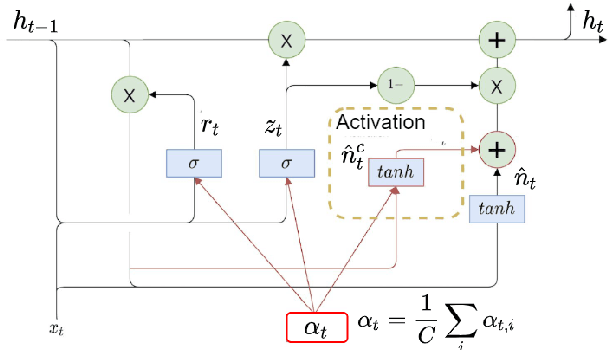
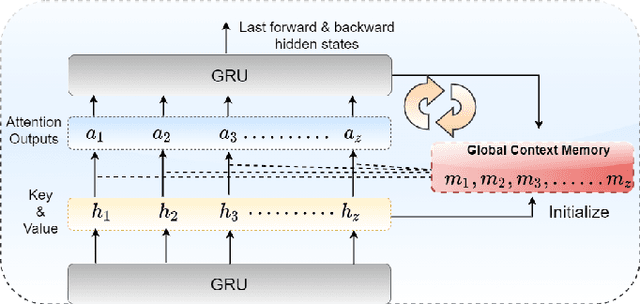
Vaccines are an important public health measure, but vaccine hesitancy and refusal can create clusters of low vaccine coverage and reduce the effectiveness of vaccination programs. Social media provides an opportunity to estimate emerging risks to vaccine acceptance by including geographical location and detailing vaccine-related concerns. Methods for classifying social media posts, such as vaccine-related tweets, use language models (LMs) trained on general domain text. However, challenges to measuring vaccine sentiment at scale arise from the absence of tonal stress and gestural cues and may not always have additional information about the user, e.g., past tweets or social connections. Another challenge in LMs is the lack of commonsense knowledge that are apparent in users metadata, i.e., emoticons, positive and negative words etc. In this study, to classify vaccine sentiment tweets with limited information, we present a novel end-to-end framework consisting of interconnected components that use domain-specific LM trained on vaccine-related tweets and models commonsense knowledge into a bidirectional gated recurrent network (CK-BiGRU) with context-aware attention. We further leverage syntactical, user metadata and sentiment information to capture the sentiment of a tweet. We experimented using two popular vaccine-related Twitter datasets and demonstrate that our proposed approach outperforms state-of-the-art models in identifying pro-vaccine, anti-vaccine and neutral tweets.
InfoGram and Admissible Machine Learning
Aug 17, 2021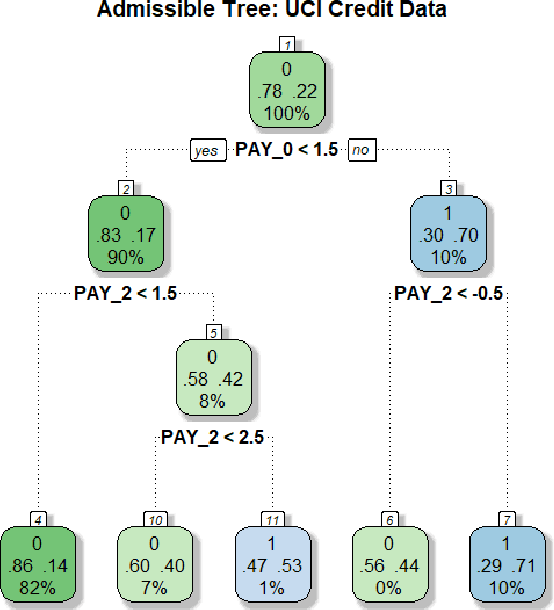

We have entered a new era of machine learning (ML), where the most accurate algorithm with superior predictive power may not even be deployable, unless it is admissible under the regulatory constraints. This has led to great interest in developing fair, transparent and trustworthy ML methods. The purpose of this article is to introduce a new information-theoretic learning framework (admissible machine learning) and algorithmic risk-management tools (InfoGram, L-features, ALFA-testing) that can guide an analyst to redesign off-the-shelf ML methods to be regulatory compliant, while maintaining good prediction accuracy. We have illustrated our approach using several real-data examples from financial sectors, biomedical research, marketing campaigns, and the criminal justice system.
Tensor Full Feature Measure and Its Nonconvex Relaxation Applications to Tensor Recovery
Sep 25, 2021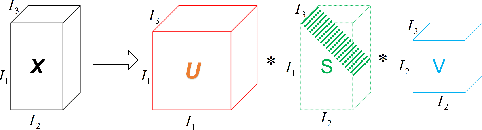
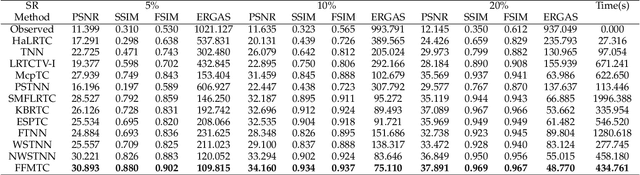

Tensor sparse modeling as a promising approach, in the whole of science and engineering has been a huge success. As is known to all, various data in practical application are often generated by multiple factors, so the use of tensors to represent the data containing the internal structure of multiple factors came into being. However, different from the matrix case, constructing reasonable sparse measure of tensor is a relatively difficult and very important task. Therefore, in this paper, we propose a new tensor sparsity measure called Tensor Full Feature Measure (FFM). It can simultaneously describe the feature information of each dimension of the tensor and the related features between two dimensions, and connect the Tucker rank with the tensor tube rank. This measurement method can describe the sparse features of the tensor more comprehensively. On this basis, we establish its non-convex relaxation, and apply FFM to low rank tensor completion (LRTC) and tensor robust principal component analysis (TRPCA). LRTC and TRPCA models based on FFM are proposed, and two efficient Alternating Direction Multiplier Method (ADMM) algorithms are developed to solve the proposed model. A variety of real numerical experiments substantiate the superiority of the proposed methods beyond state-of-the-arts.
Understanding Information Processing in Human Brain by Interpreting Machine Learning Models
Oct 17, 2020
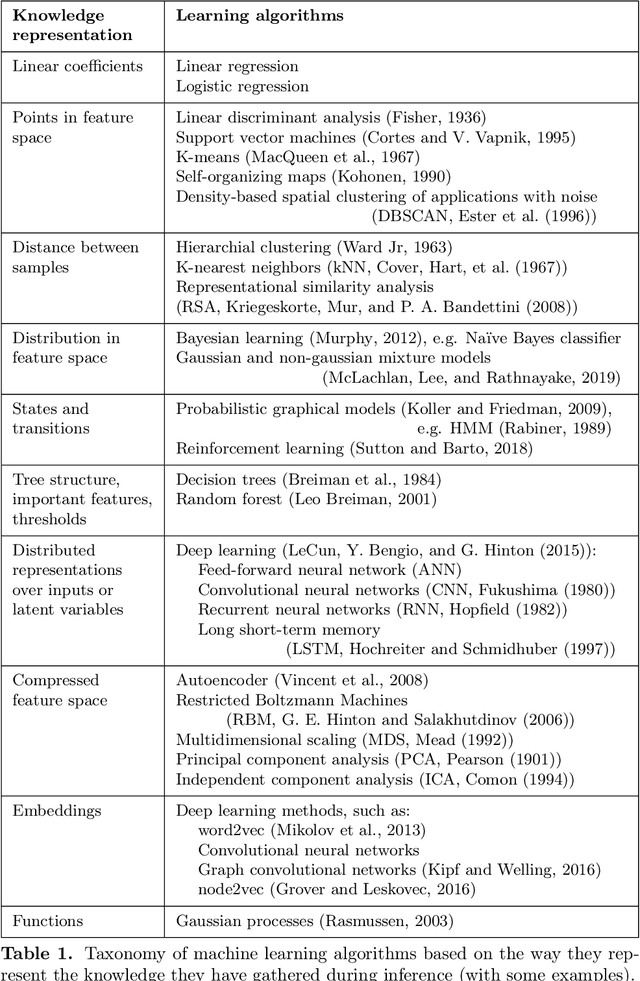
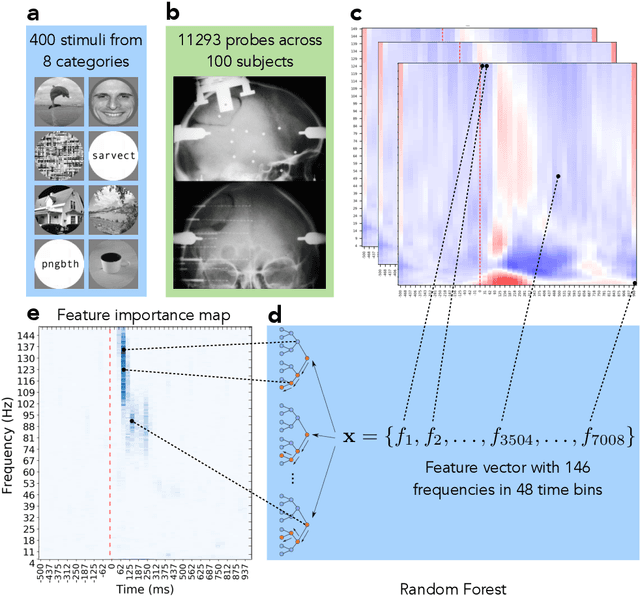

The thesis explores the role machine learning methods play in creating intuitive computational models of neural processing. Combined with interpretability techniques, machine learning could replace human modeler and shift the focus of human effort to extracting the knowledge from the ready-made models and articulating that knowledge into intuitive descroptions of reality. This perspective makes the case in favor of the larger role that exploratory and data-driven approach to computational neuroscience could play while coexisting alongside the traditional hypothesis-driven approach. We exemplify the proposed approach in the context of the knowledge representation taxonomy with three research projects that employ interpretability techniques on top of machine learning methods at three different levels of neural organization. The first study (Chapter 3) explores feature importance analysis of a random forest decoder trained on intracerebral recordings from 100 human subjects to identify spectrotemporal signatures that characterize local neural activity during the task of visual categorization. The second study (Chapter 4) employs representation similarity analysis to compare the neural responses of the areas along the ventral stream with the activations of the layers of a deep convolutional neural network. The third study (Chapter 5) proposes a method that allows test subjects to visually explore the state representation of their neural signal in real time. This is achieved by using a topology-preserving dimensionality reduction technique that allows to transform the neural data from the multidimensional representation used by the computer into a two-dimensional representation a human can grasp. The approach, the taxonomy, and the examples, present a strong case for the applicability of machine learning methods to automatic knowledge discovery in neuroscience.
Coverless information hiding based on Generative Model
Feb 10, 2018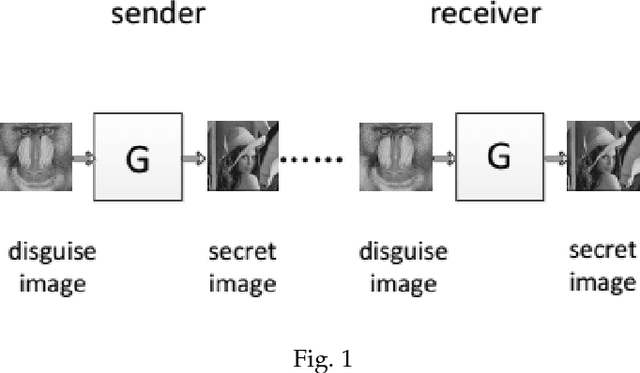
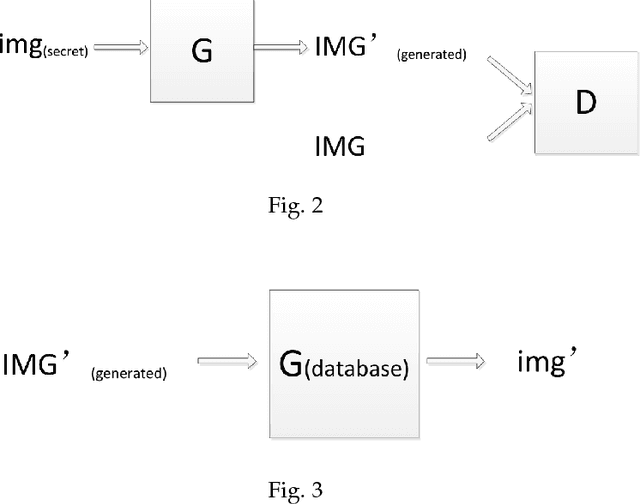
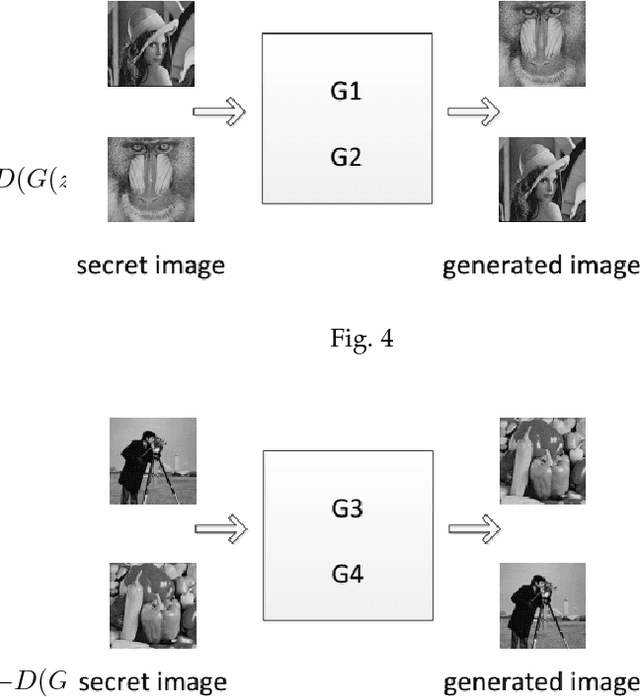
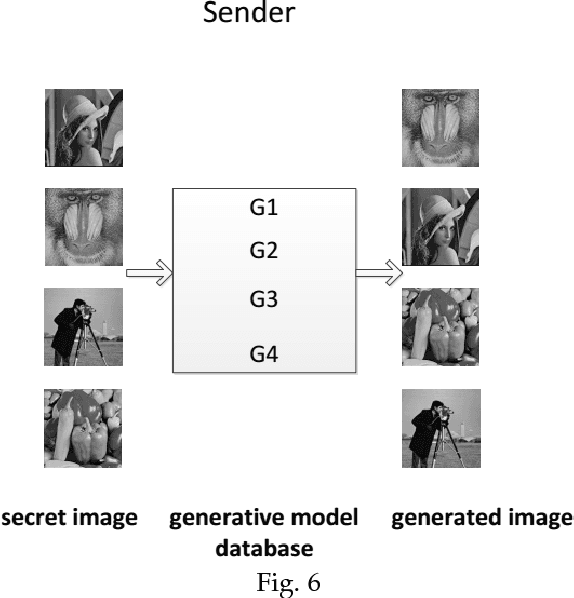
A new coverless image information hiding method based on generative model is proposed, we feed the secret image to the generative model database, and generate a meaning-normal and independent image different from the secret image, then, the generated image is transmitted to the receiver and is fed to the generative model database to generate another image visually the same as the secret image. So we only need to transmit the meaning-normal image which is not related to the secret image, and we can achieve the same effect as the transmission of the secret image. This is the first time to propose the coverless image information hiding method based on generative model, compared with the traditional image steganography, the transmitted image does not embed any information of the secret image in this method, therefore, can effectively resist steganalysis tools. Experimental results show that our method has high capacity, safety and reliability.
Source-Free Domain Adaptive Fundus Image Segmentation with Denoised Pseudo-Labeling
Sep 19, 2021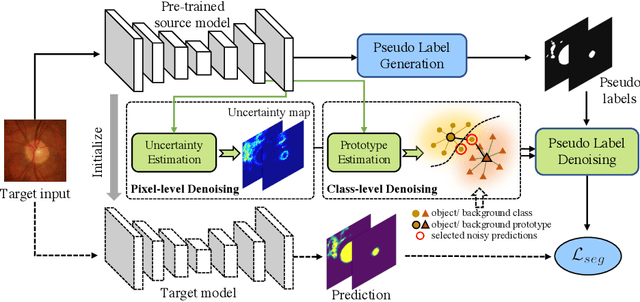
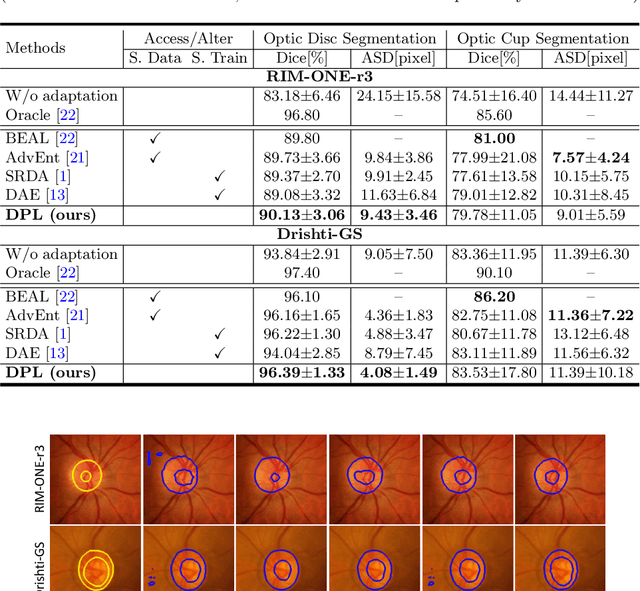

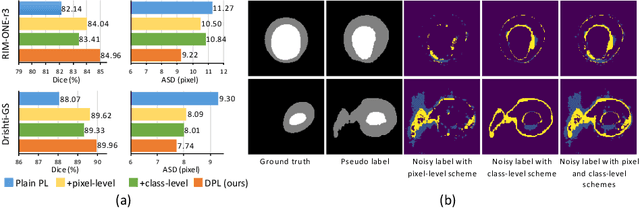
Domain adaptation typically requires to access source domain data to utilize their distribution information for domain alignment with the target data. However, in many real-world scenarios, the source data may not be accessible during the model adaptation in the target domain due to privacy issue. This paper studies the practical yet challenging source-free unsupervised domain adaptation problem, in which only an existing source model and the unlabeled target data are available for model adaptation. We present a novel denoised pseudo-labeling method for this problem, which effectively makes use of the source model and unlabeled target data to promote model self-adaptation from pseudo labels. Importantly, considering that the pseudo labels generated from source model are inevitably noisy due to domain shift, we further introduce two complementary pixel-level and class-level denoising schemes with uncertainty estimation and prototype estimation to reduce noisy pseudo labels and select reliable ones to enhance the pseudo-labeling efficacy. Experimental results on cross-domain fundus image segmentation show that without using any source images or altering source training, our approach achieves comparable or even higher performance than state-of-the-art source-dependent unsupervised domain adaptation methods.
Ethereum Data Structures
Aug 12, 2021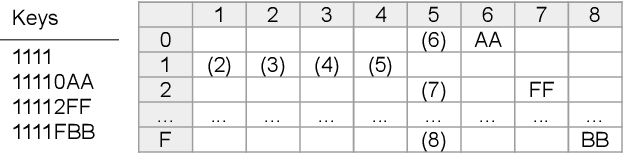
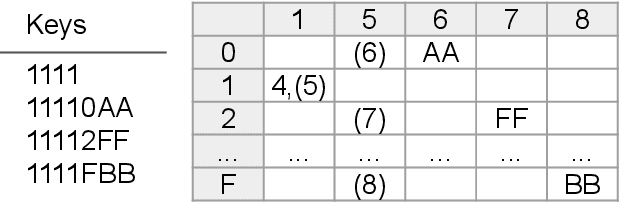
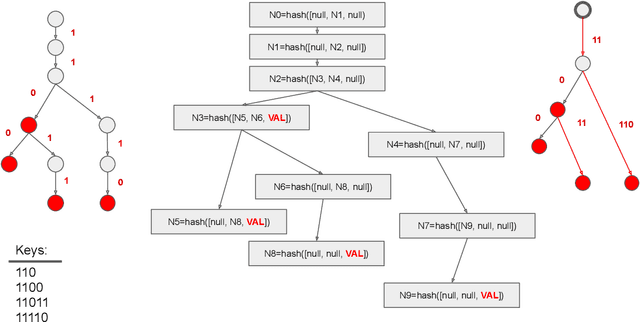
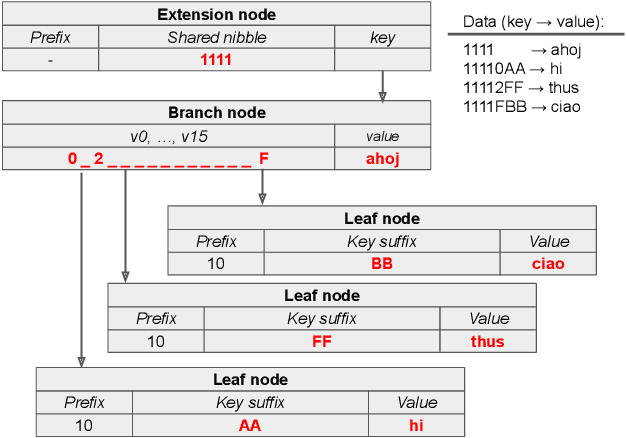
Ethereum platform operates with rich spectrum of data structures and hashing and coding functions. The main source describing them is the Yellow paper, complemented by a lot of informal blogs. These sources are somehow limited. In particular, the Yellow paper does not ideally balance brevity and detail, in some parts it is very detail, while too shallow elsewhere. The blogs on the other hand are often too vague and in certain cases contain incorrect information. As a solution, we provide this document, which summarises data structures used in Ethereum. The goal is to provide sufficient detail while keeping brevity. Sufficiently detailed formal view is enriched with examples to extend on clarity.
On the overlooked issue of defining explanation objectives for local-surrogate explainers
Jun 10, 2021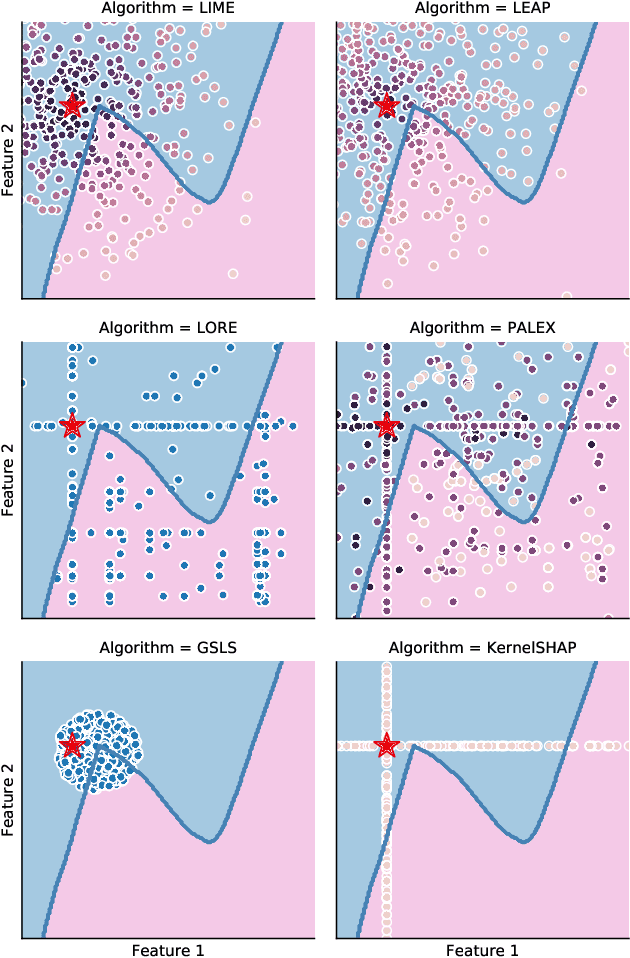

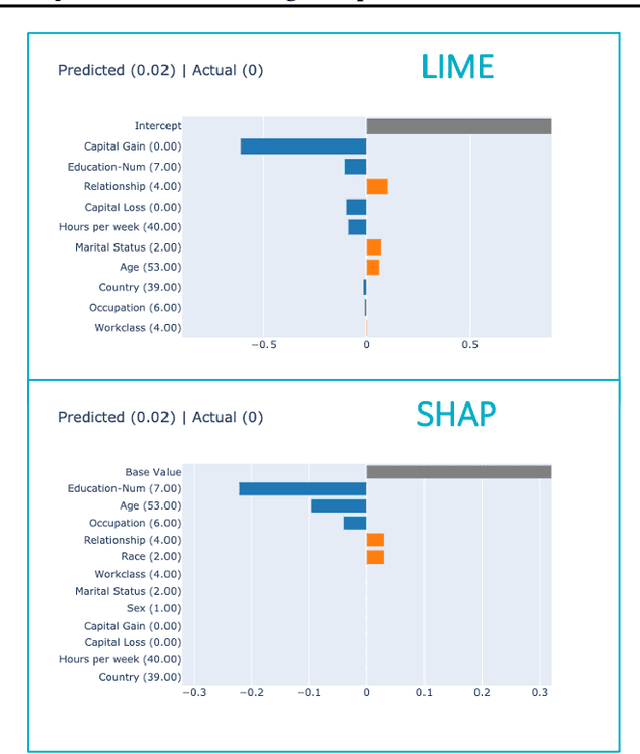
Local surrogate approaches for explaining machine learning model predictions have appealing properties, such as being model-agnostic and flexible in their modelling. Several methods exist that fit this description and share this goal. However, despite their shared overall procedure, they set out different objectives, extract different information from the black-box, and consequently produce diverse explanations, that are -- in general -- incomparable. In this work we review the similarities and differences amongst multiple methods, with a particular focus on what information they extract from the model, as this has large impact on the output: the explanation. We discuss the implications of the lack of agreement, and clarity, amongst the methods' objectives on the research and practice of explainability.
A Bayesian Approach to (Online) Transfer Learning: Theory and Algorithms
Sep 30, 2021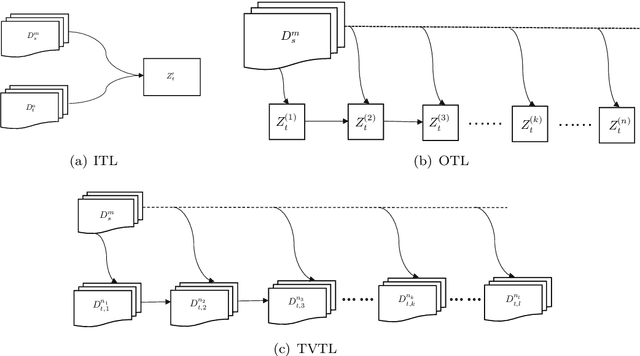

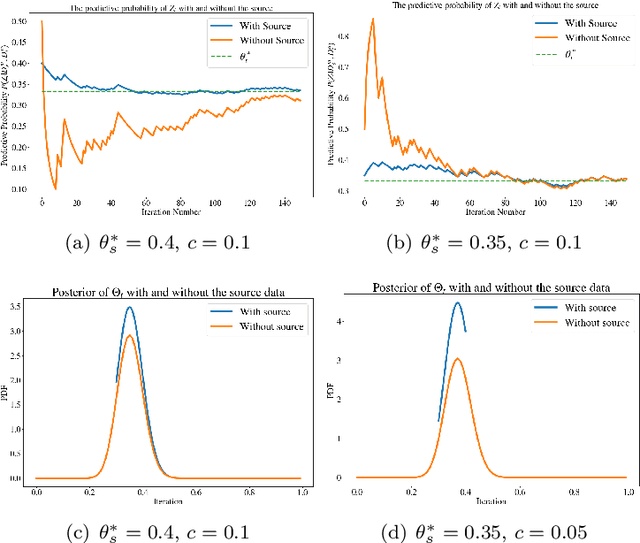
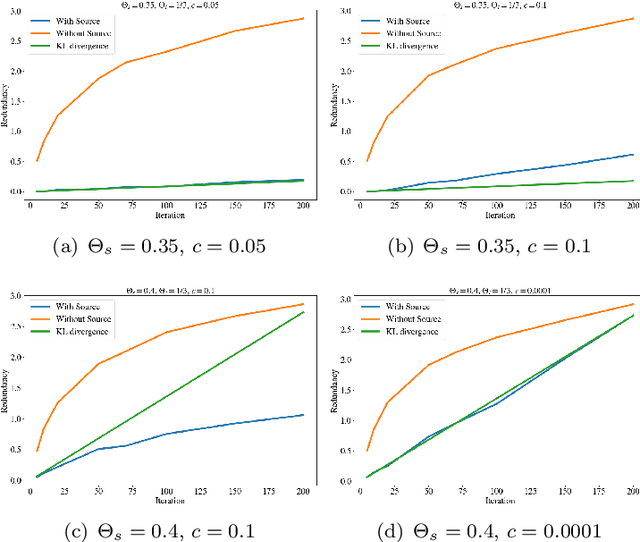
Transfer learning is a machine learning paradigm where knowledge from one problem is utilized to solve a new but related problem. While conceivable that knowledge from one task could be useful for solving a related task, if not executed properly, transfer learning algorithms can impair the learning performance instead of improving it -- commonly known as negative transfer. In this paper, we study transfer learning from a Bayesian perspective, where a parametric statistical model is used. Specifically, we study three variants of transfer learning problems, instantaneous, online, and time-variant transfer learning. For each problem, we define an appropriate objective function, and provide either exact expressions or upper bounds on the learning performance using information-theoretic quantities, which allow simple and explicit characterizations when the sample size becomes large. Furthermore, examples show that the derived bounds are accurate even for small sample sizes. The obtained bounds give valuable insights into the effect of prior knowledge for transfer learning, at least with respect to our Bayesian formulation of the transfer learning problem. In particular, we formally characterize the conditions under which negative transfer occurs. Lastly, we devise two (online) transfer learning algorithms that are amenable to practical implementations, one of which does not require the parametric assumption. We demonstrate the effectiveness of our algorithms with real data sets, focusing primarily on when the source and target data have strong similarities.
Thinking Fast and Slow in AI: the Role of Metacognition
Oct 05, 2021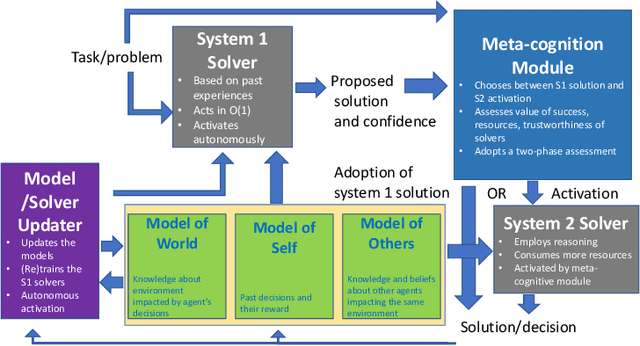
AI systems have seen dramatic advancement in recent years, bringing many applications that pervade our everyday life. However, we are still mostly seeing instances of narrow AI: many of these recent developments are typically focused on a very limited set of competencies and goals, e.g., image interpretation, natural language processing, classification, prediction, and many others. Moreover, while these successes can be accredited to improved algorithms and techniques, they are also tightly linked to the availability of huge datasets and computational power. State-of-the-art AI still lacks many capabilities that would naturally be included in a notion of (human) intelligence. We argue that a better study of the mechanisms that allow humans to have these capabilities can help us understand how to imbue AI systems with these competencies. We focus especially on D. Kahneman's theory of thinking fast and slow, and we propose a multi-agent AI architecture where incoming problems are solved by either system 1 (or "fast") agents, that react by exploiting only past experience, or by system 2 (or "slow") agents, that are deliberately activated when there is the need to reason and search for optimal solutions beyond what is expected from the system 1 agent. Both kinds of agents are supported by a model of the world, containing domain knowledge about the environment, and a model of "self", containing information about past actions of the system and solvers' skills.