 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploiting Multiple EEG Data Domains with Adversarial Learning
Apr 16, 2022
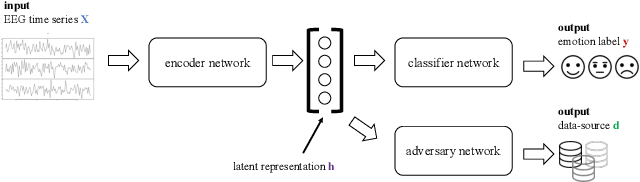
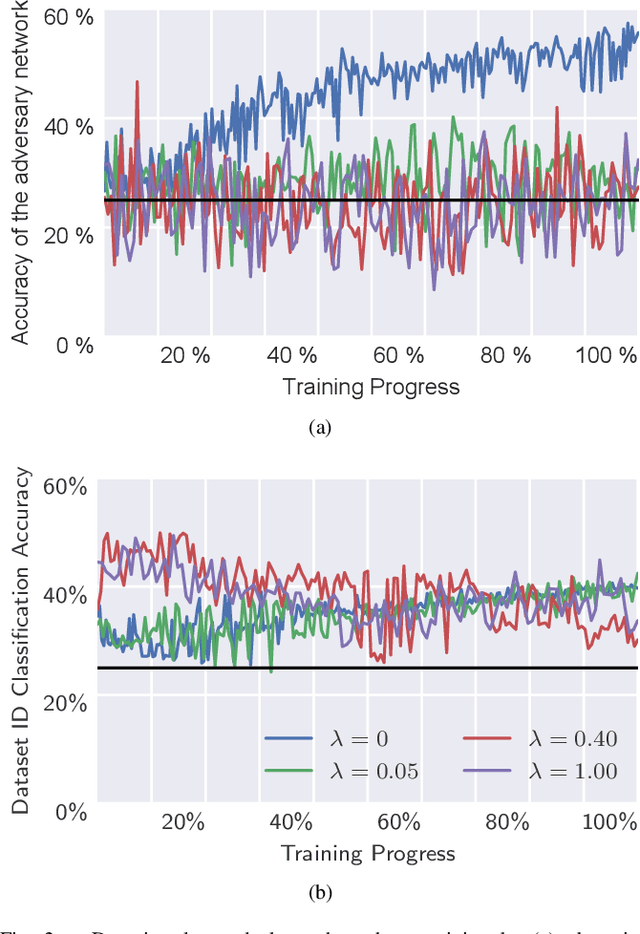
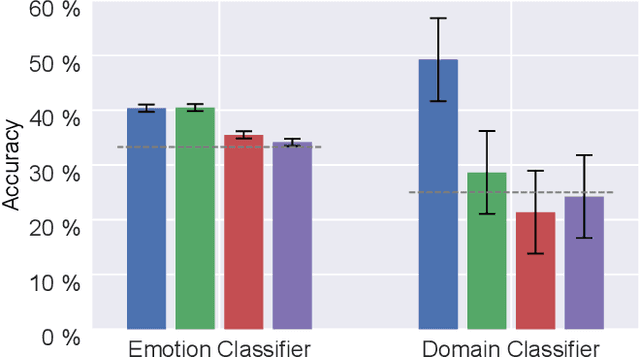
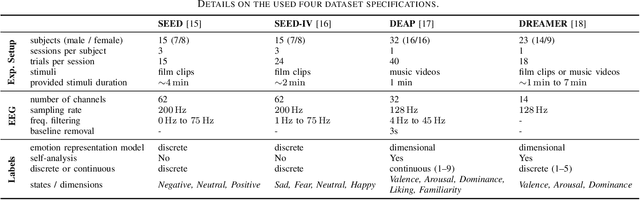
Electroencephalography (EEG) is shown to be a valuable data source for evaluating subjects' mental states. However, the interpretation of multi-modal EEG signals is challenging, as they suffer from poor signal-to-noise-ratio, are highly subject-dependent, and are bound to the equipment and experimental setup used, (i.e. domain). This leads to machine learning models often suffer from poor generalization ability, where they perform significantly worse on real-world data than on the exploited training data. Recent research heavily focuses on cross-subject and cross-session transfer learning frameworks to reduce domain calibration efforts for EEG signals. We argue that multi-source learning via learning domain-invariant representations from multiple data-sources is a viable alternative, as the available data from different EEG data-source domains (e.g., subjects, sessions, experimental setups) grow massively. We propose an adversarial inference approach to learn data-source invariant representations in this context, enabling multi-source learning for EEG-based brain-computer interfaces. We unify EEG recordings from different source domains (i.e., emotion recognition datasets SEED, SEED-IV, DEAP, DREAMER), and demonstrate the feasibility of our invariant representation learning approach in suppressing data-source-relevant information leakage by 35% while still achieving stable EEG-based emotion classification performance.
Translational Lung Imaging Analysis Through Disentangled Representations
Mar 03, 2022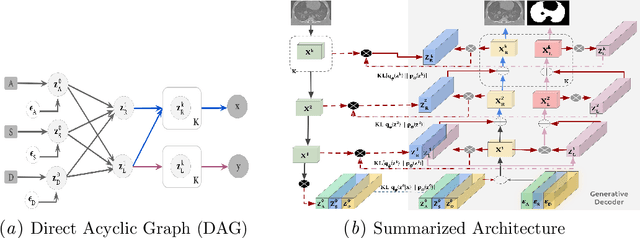
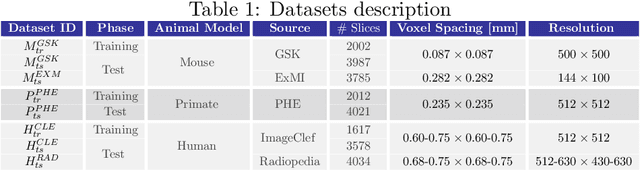
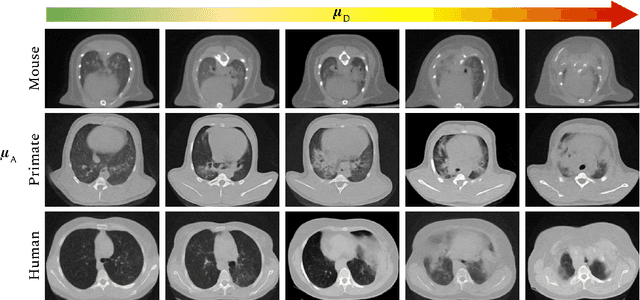

The development of new treatments often requires clinical trials with translational animal models using (pre)-clinical imaging to characterize inter-species pathological processes. Deep Learning (DL) models are commonly used to automate retrieving relevant information from the images. Nevertheless, they typically suffer from low generability and explainability as a product of their entangled design, resulting in a specific DL model per animal model. Consequently, it is not possible to take advantage of the high capacity of DL to discover statistical relationships from inter-species images. To alleviate this problem, in this work, we present a model capable of extracting disentangled information from images of different animal models and the mechanisms that generate the images. Our method is located at the intersection between deep generative models, disentanglement and causal representation learning. It is optimized from images of pathological lung infected by Tuberculosis and is able: a) from an input slice, infer its position in a volume, the animal model to which it belongs, the damage present and even more, generate a mask covering the whole lung (similar overlap measures to the nnU-Net), b) generate realistic lung images by setting the above variables and c) generate counterfactual images, namely, healthy versions of a damaged input slice.
Adaptive Cross-Attention-Driven Spatial-Spectral Graph Convolutional Network for Hyperspectral Image Classification
Apr 12, 2022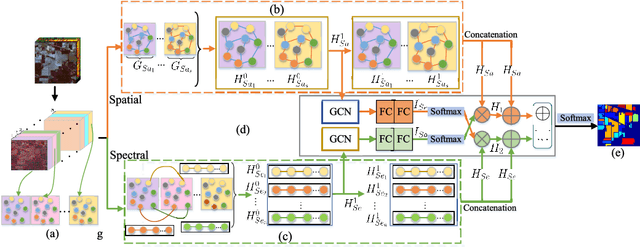
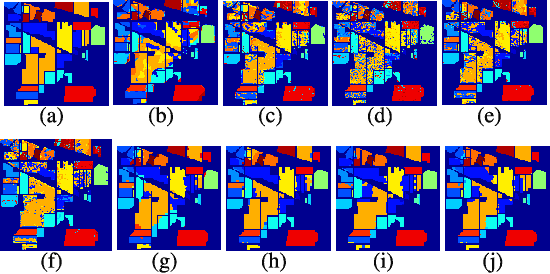
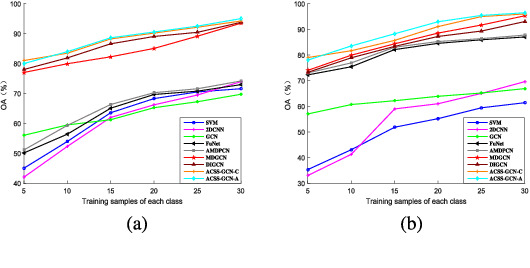
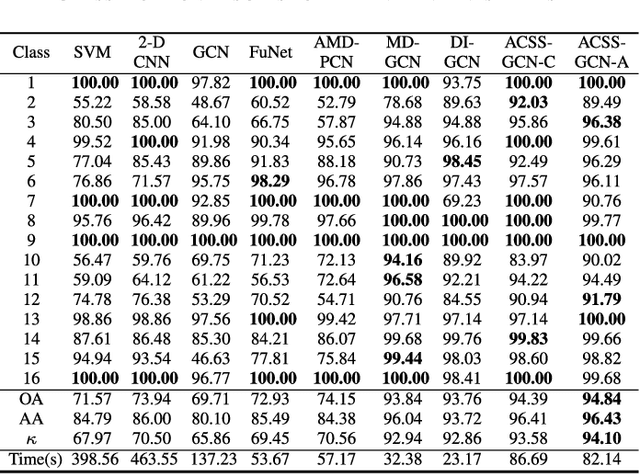
Recently, graph convolutional networks (GCNs) have been developed to explore spatial relationship between pixels, achieving better classification performance of hyperspectral images (HSIs). However, these methods fail to sufficiently leverage the relationship between spectral bands in HSI data. As such, we propose an adaptive cross-attention-driven spatial-spectral graph convolutional network (ACSS-GCN), which is composed of a spatial GCN (Sa-GCN) subnetwork, a spectral GCN (Se-GCN) subnetwork, and a graph cross-attention fusion module (GCAFM). Specifically, Sa-GCN and Se-GCN are proposed to extract the spatial and spectral features by modeling correlations between spatial pixels and between spectral bands, respectively. Then, by integrating attention mechanism into information aggregation of graph, the GCAFM, including three parts, i.e., spatial graph attention block, spectral graph attention block, and fusion block, is designed to fuse the spatial and spectral features and suppress noise interference in Sa-GCN and Se-GCN. Moreover, the idea of the adaptive graph is introduced to explore an optimal graph through back propagation during the training process. Experiments on two HSI data sets show that the proposed method achieves better performance than other classification methods.
Deep Polarimetric HDR Reconstruction
Mar 27, 2022
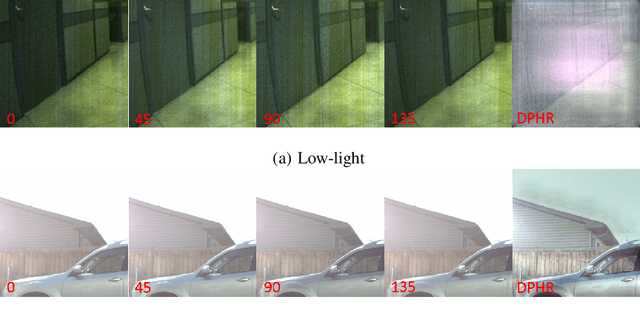
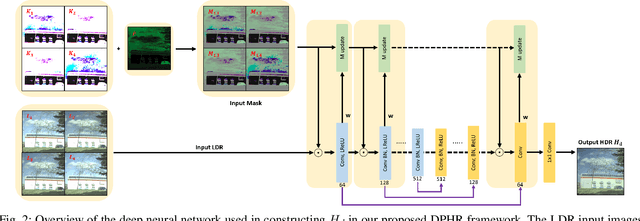
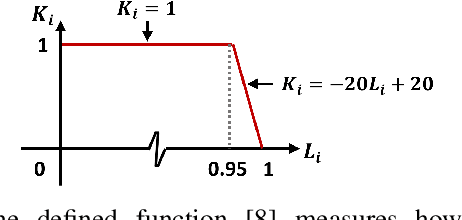
This paper proposes a novel learning based high-dynamic-range (HDR) reconstruction method using a polarization camera. We utilize a previous observation that polarization filters with different orientations can attenuate natural light differently, and we treat the multiple images acquired by the polarization camera as a set acquired under different exposure times, to introduce the development of solutions for the HDR reconstruction problem. We propose a deep HDR reconstruction framework with a feature masking mechanism that uses polarimetric cues available from the polarization camera, called Deep Polarimetric HDR Reconstruction (DPHR). The proposed DPHR obtains polarimetric information to propagate valid features through the network more effectively to regress the missing pixels. We demonstrate through both qualitative and quantitative evaluations that the proposed DPHR performs favorably than state-of-the-art HDR reconstruction algorithms.
Multi-modal unsupervised brain image registration using edge maps
Feb 09, 2022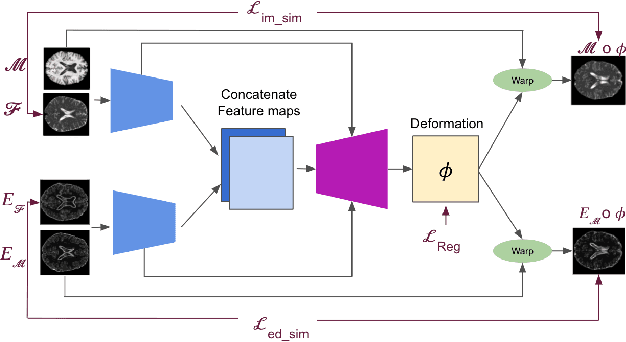
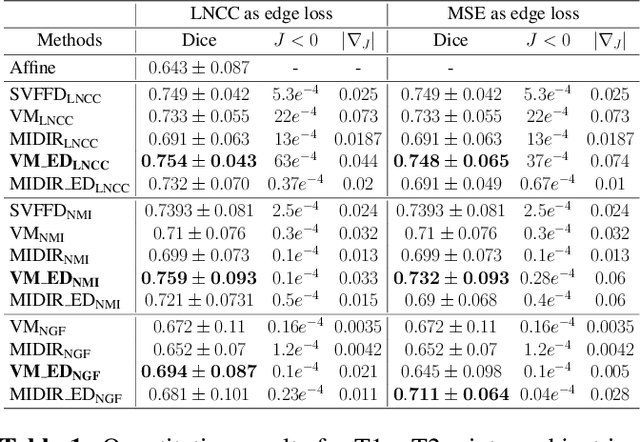


Diffeomorphic deformable multi-modal image registration is a challenging task which aims to bring images acquired by different modalities to the same coordinate space and at the same time to preserve the topology and the invertibility of the transformation. Recent research has focused on leveraging deep learning approaches for this task as these have been shown to achieve competitive registration accuracy while being computationally more efficient than traditional iterative registration methods. In this work, we propose a simple yet effective unsupervised deep learning-based {\em multi-modal} image registration approach that benefits from auxiliary information coming from the gradient magnitude of the image, i.e. the image edges, during the training. The intuition behind this is that image locations with a strong gradient are assumed to denote a transition of tissues, which are locations of high information value able to act as a geometry constraint. The task is similar to using segmentation maps to drive the training, but the edge maps are easier and faster to acquire and do not require annotations. We evaluate our approach in the context of registering multi-modal (T1w to T2w) magnetic resonance (MR) brain images of different subjects using three different loss functions that are said to assist multi-modal registration, showing that in all cases the auxiliary information leads to better results without compromising the runtime.
Convolutional Neural Network Modelling for MODIS Land Surface Temperature Super-Resolution
Apr 01, 2022
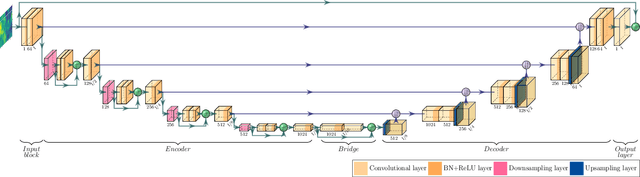
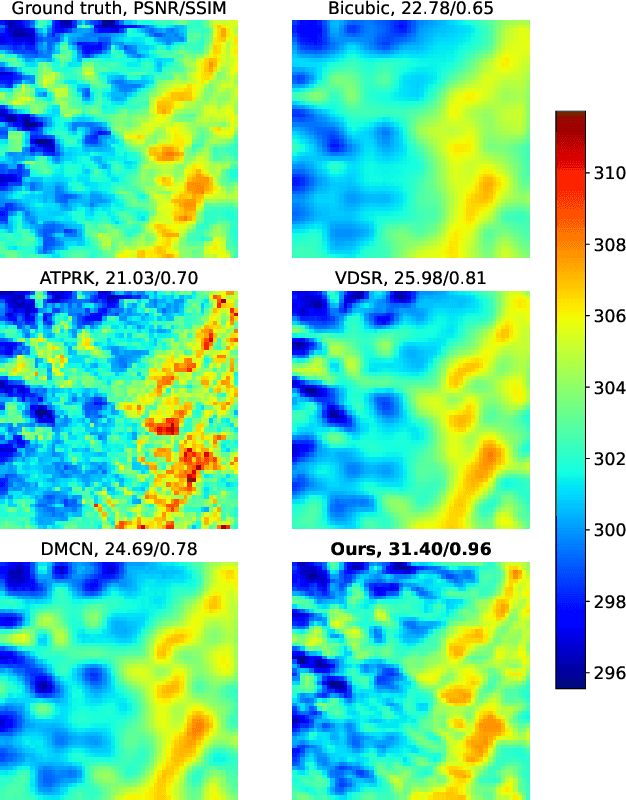
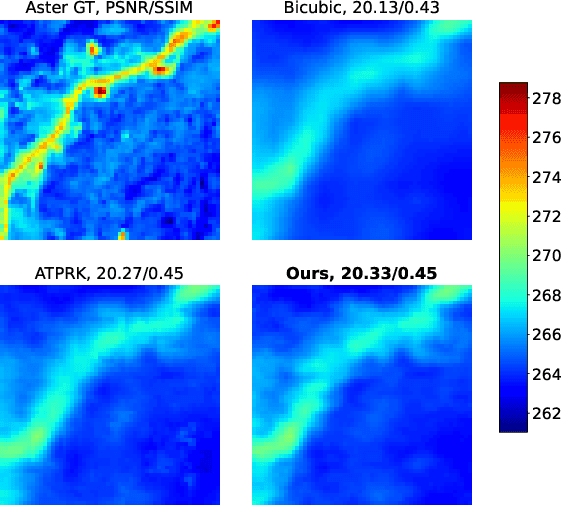
Nowadays, thermal infrared satellite remote sensors enable to extract very interesting information at large scale, in particular Land Surface Temperature (LST). However such data are limited in spatial and/or temporal resolutions which prevents from an analysis at fine scales. For example, MODIS satellite provides daily acquisitions with 1Km spatial resolutions which is not sufficient to deal with highly heterogeneous environments as agricultural parcels. Therefore, image super-resolution is a crucial task to better exploit MODIS LSTs. This issue is tackled in this paper. We introduce a deep learning-based algorithm, named Multi-residual U-Net, for super-resolution of MODIS LST single-images. Our proposed network is a modified version of U-Net architecture, which aims at super-resolving the input LST image from 1Km to 250m per pixel. The results show that our Multi-residual U-Net outperforms other state-of-the-art methods.
Automatic Text Summarization Methods: A Comprehensive Review
Mar 03, 2022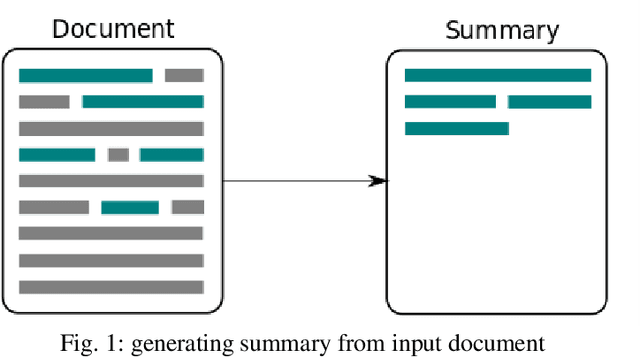
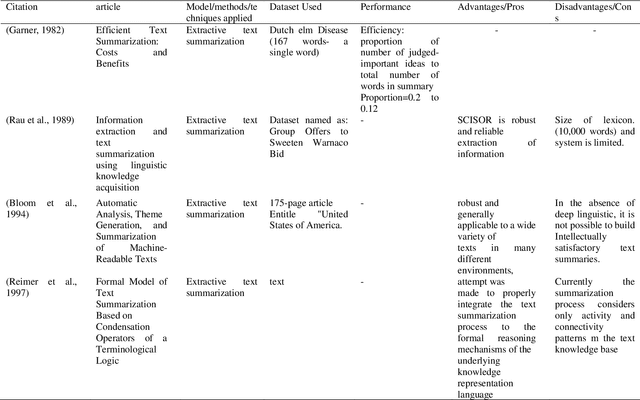
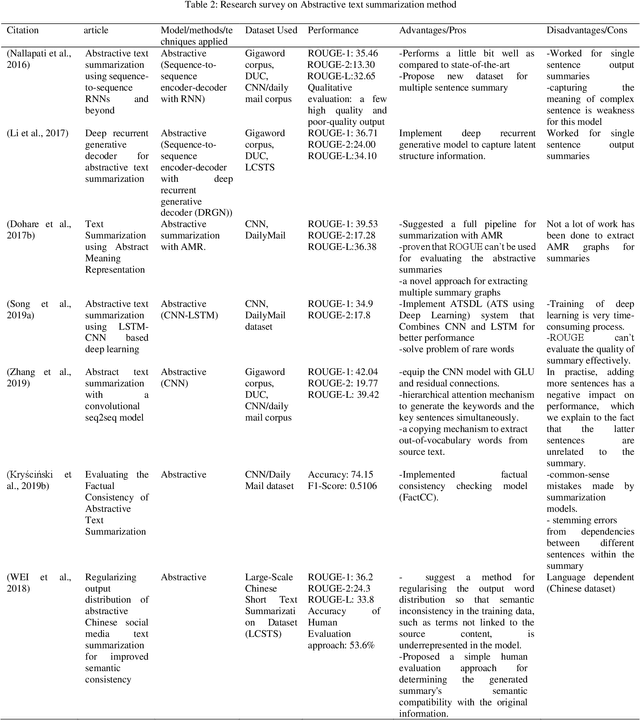
One of the most pressing issues that have arisen due to the rapid growth of the Internet is known as information overloading. Simplifying the relevant information in the form of a summary will assist many people because the material on any topic is plentiful on the Internet. Manually summarising massive amounts of text is quite challenging for humans. So, it has increased the need for more complex and powerful summarizers. Researchers have been trying to improve approaches for creating summaries since the 1950s, such that the machine-generated summary matches the human-created summary. This study provides a detailed state-of-the-art analysis of text summarization concepts such as summarization approaches, techniques used, standard datasets, evaluation metrics and future scopes for research. The most commonly accepted approaches are extractive and abstractive, studied in detail in this work. Evaluating the summary and increasing the development of reusable resources and infrastructure aids in comparing and replicating findings, adding competition to improve the outcomes. Different evaluation methods of generated summaries are also discussed in this study. Finally, at the end of this study, several challenges and research opportunities related to text summarization research are mentioned that may be useful for potential researchers working in this area.
CasGCN: Predicting future cascade growth based on information diffusion graph
Sep 10, 2020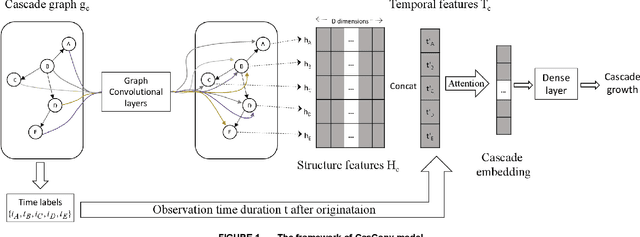
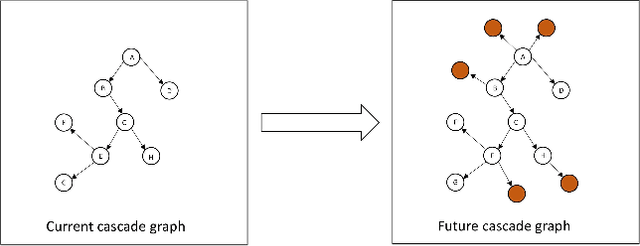
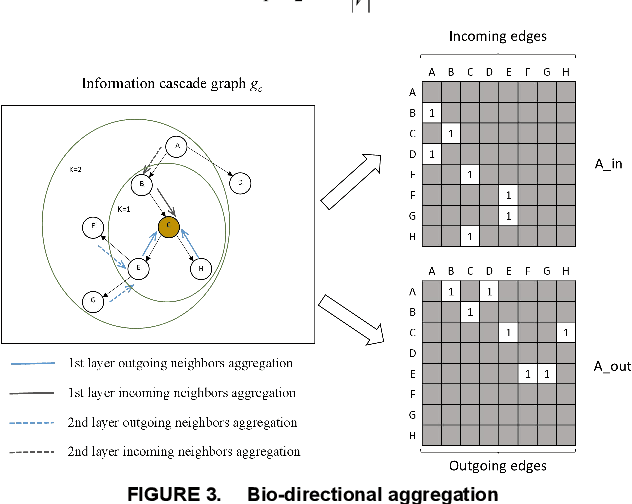
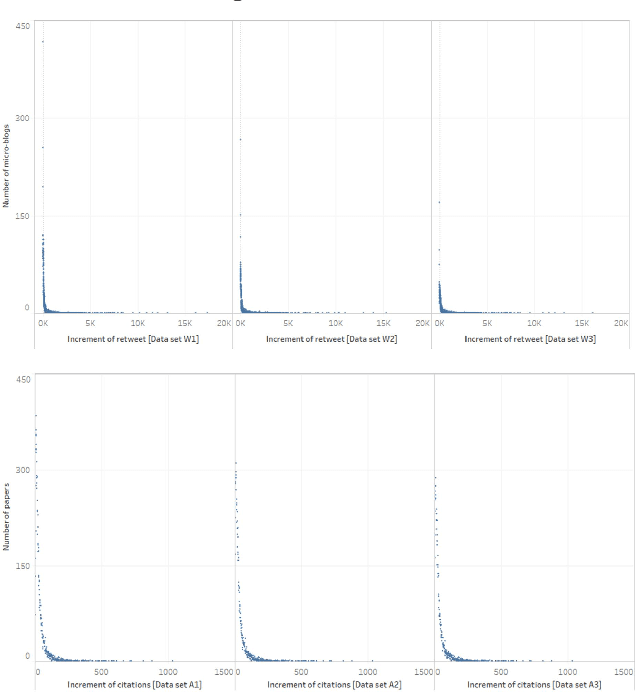
Sudden bursts of information cascades can lead to unexpected consequences such as extreme opinions, changes in fashion trends, and uncontrollable spread of rumors. It has become an important problem on how to effectively predict a cascade' size in the future, especially for large-scale cascades on social media platforms such as Twitter and Weibo. However, existing methods are insufficient in dealing with this challenging prediction problem. Conventional methods heavily rely on either hand crafted features or unrealistic assumptions. End-to-end deep learning models, such as recurrent neural networks, are not suitable to work with graphical inputs directly and cannot handle structural information that is embedded in the cascade graphs. In this paper, we propose a novel deep learning architecture for cascade growth prediction, called CasGCN, which employs the graph convolutional network to extract structural features from a graphical input, followed by the application of the attention mechanism on both the extracted features and the temporal information before conducting cascade size prediction. We conduct experiments on two real-world cascade growth prediction scenarios (i.e., retweet popularity on Sina Weibo and academic paper citations on DBLP), with the experimental results showing that CasGCN enjoys a superior performance over several baseline methods, particularly when the cascades are of large scale.
A Collection of Deep Learning-based Feature-Free Approaches for Characterizing Single-Objective Continuous Fitness Landscapes
Apr 12, 2022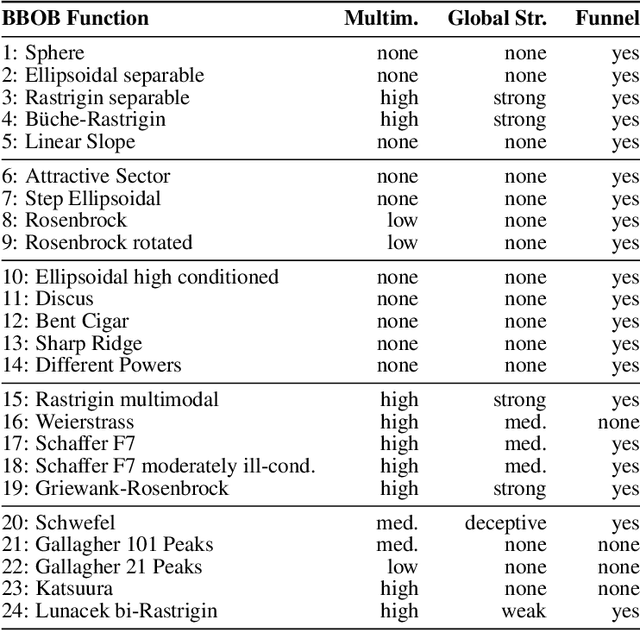
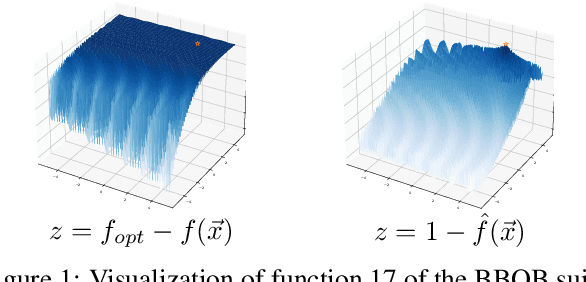
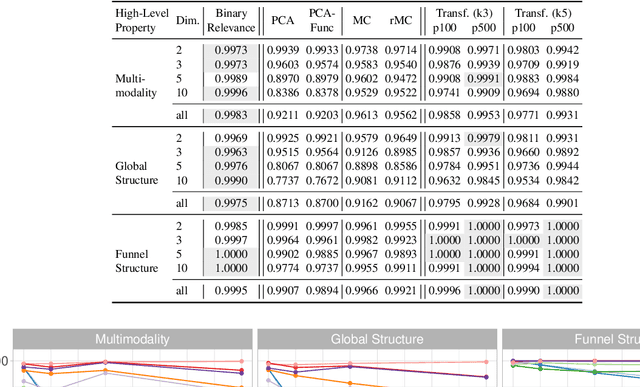
Exploratory Landscape Analysis is a powerful technique for numerically characterizing landscapes of single-objective continuous optimization problems. Landscape insights are crucial both for problem understanding as well as for assessing benchmark set diversity and composition. Despite the irrefutable usefulness of these features, they suffer from their own ailments and downsides. Hence, in this work we provide a collection of different approaches to characterize optimization landscapes. Similar to conventional landscape features, we require a small initial sample. However, instead of computing features based on that sample, we develop alternative representations of the original sample. These range from point clouds to 2D images and, therefore, are entirely feature-free. We demonstrate and validate our devised methods on the BBOB testbed and predict, with the help of Deep Learning, the high-level, expert-based landscape properties such as the degree of multimodality and the existence of funnel structures. The quality of our approaches is on par with methods relying on the traditional landscape features. Thereby, we provide an exciting new perspective on every research area which utilizes problem information such as problem understanding and algorithm design as well as automated algorithm configuration and selection.
Do Not Fire the Linguist: Grammatical Profiles Help Language Models Detect Semantic Change
Apr 12, 2022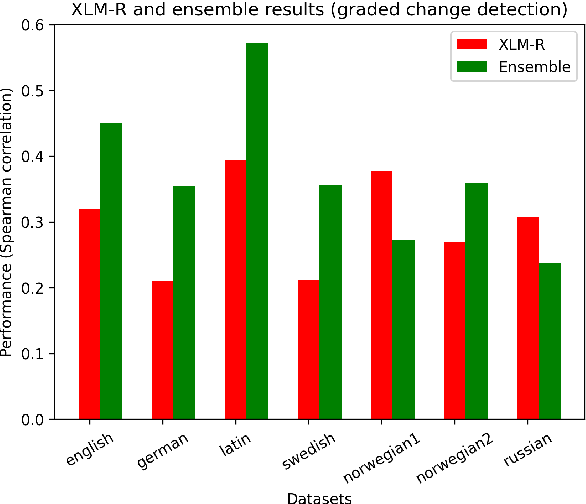

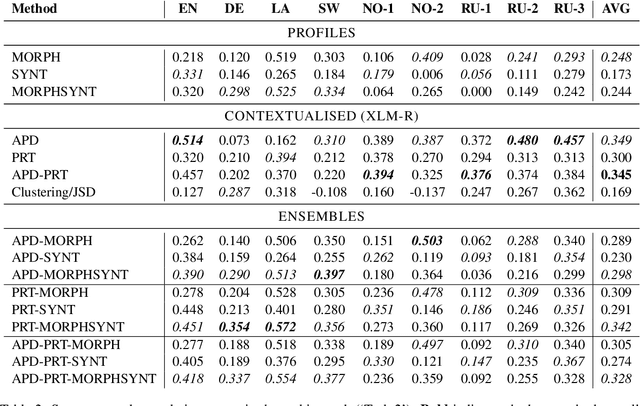
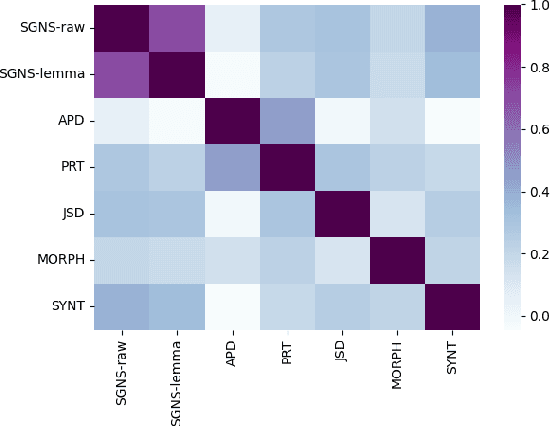
Morphological and syntactic changes in word usage (as captured, e.g., by grammatical profiles) have been shown to be good predictors of a word's meaning change. In this work, we explore whether large pre-trained contextualised language models, a common tool for lexical semantic change detection, are sensitive to such morphosyntactic changes. To this end, we first compare the performance of grammatical profiles against that of a multilingual neural language model (XLM-R) on 10 datasets, covering 7 languages, and then combine the two approaches in ensembles to assess their complementarity. Our results show that ensembling grammatical profiles with XLM-R improves semantic change detection performance for most datasets and languages. This indicates that language models do not fully cover the fine-grained morphological and syntactic signals that are explicitly represented in grammatical profiles. An interesting exception are the test sets where the time spans under analysis are much longer than the time gap between them (for example, century-long spans with a one-year gap between them). Morphosyntactic change is slow so grammatical profiles do not detect in such cases. In contrast, language models, thanks to their access to lexical information, are able to detect fast topical changes.