 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Large Margin Image Set Representation and Classification
Apr 22, 2014
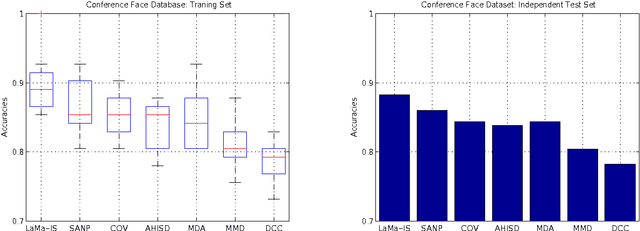
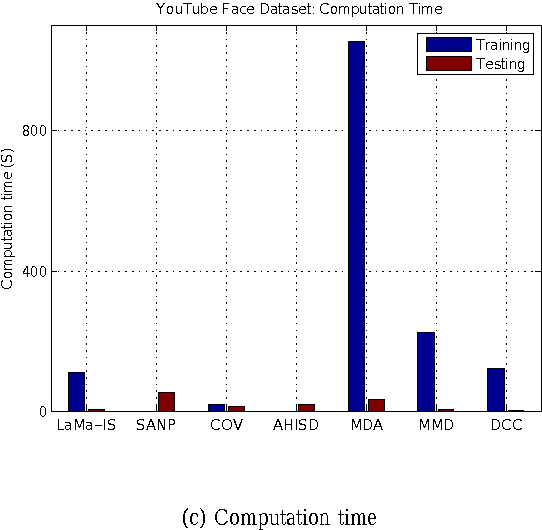
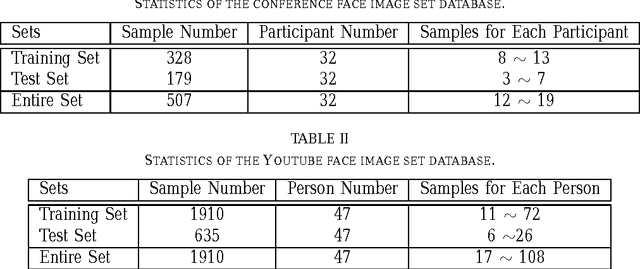
In this paper, we propose a novel image set representation and classification method by maximizing the margin of image sets. The margin of an image set is defined as the difference of the distance to its nearest image set from different classes and the distance to its nearest image set of the same class. By modeling the image sets by using both their image samples and their affine hull models, and maximizing the margins of the images sets, the image set representation parameter learning problem is formulated as an minimization problem, which is further optimized by an expectation -maximization (EM) strategy with accelerated proximal gradient (APG) optimization in an iterative algorithm. To classify a given test image set, we assign it to the class which could provide the largest margin. Experiments on two applications of video-sequence-based face recognition demonstrate that the proposed method significantly outperforms state-of-the-art image set classification methods in terms of both effectiveness and efficiency.
Interpretable Deep Learning for Pattern Recognition in Brain Differences Between Men and Women
Jun 20, 2020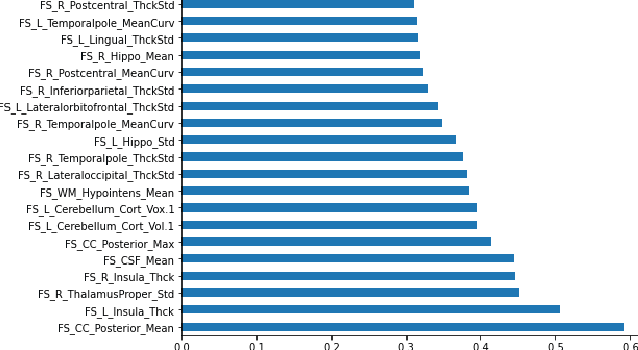

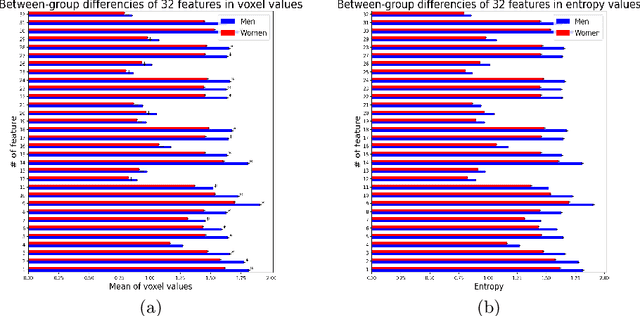
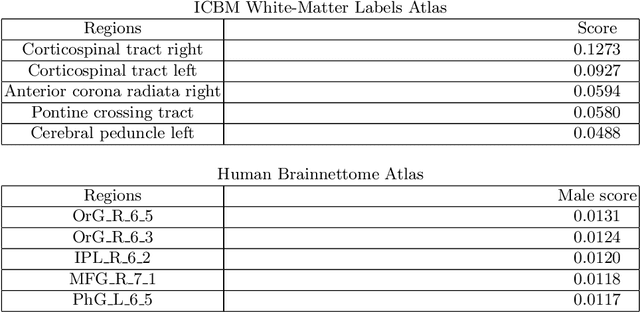
Deep learning shows high potential for many medical image analysis tasks. Neural networks work with full-size data without extensive preprocessing and feature generation and, thus, information loss. Recent work has shown that morphological difference between specific brain regions can be found on MRI with deep learning techniques. We consider the pattern recognition task based on a large open-access dataset of healthy subjects - an exploration of brain differences between men and women. However, interpretation of the lately proposed models is based on a region of interest and can not be extended to pixel or voxel-wise image interpretation, which is considered to be more informative. In this paper, we confirm the previous findings in sex differences from diffusion-tensor imaging on T1 weighted brain MRI scans. We compare the results of three voxel-based 3D CNN interpretation methods: Meaningful Perturbations, GradCam and Guided Backpropagation and provide the open-source code.
Sparse and Structured Visual Attention
Feb 13, 2020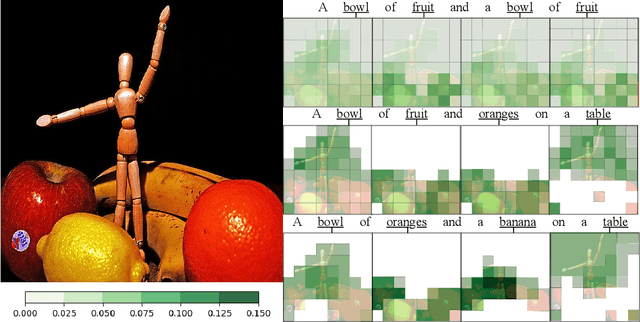

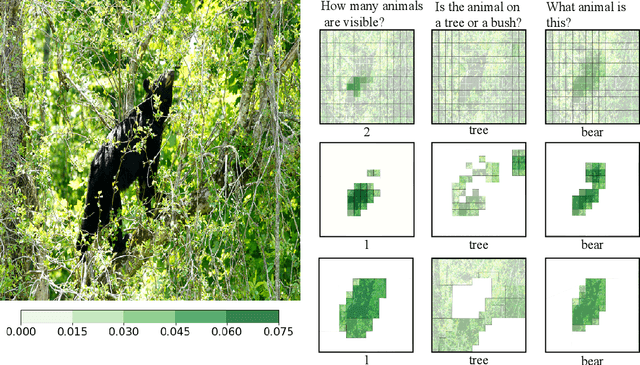

Visual attention mechanisms are widely used in multimodal tasks, such as image captioning and visual question answering (VQA). One drawback of softmax-based attention mechanisms is that they assign probability mass to all image regions, regardless of their adjacency structure and of their relevance to the text. In this paper, to better link the image structure with the text, we replace the traditional softmax attention mechanism with two alternative sparsity-promoting transformations: sparsemax, which is able to select the relevant regions only (assigning zero weight to the rest), and a newly proposed Total-Variation Sparse Attention (TVmax), which further encourages the joint selection of adjacent spatial locations. Experiments in image captioning and VQA, using both LSTM and Transformer architectures, show gains in terms of human-rated caption quality, attention relevance, and VQA accuracy, with improved interpretability.
Automated dataset generation for image recognition using the example of taxonomy
Jan 22, 2018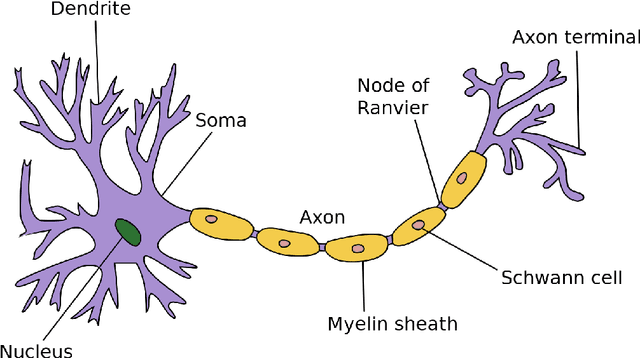
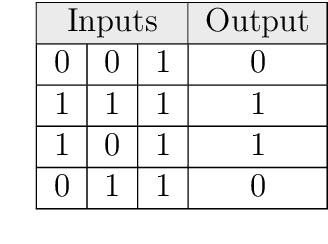
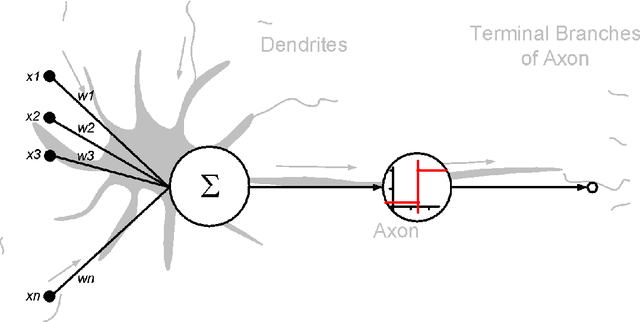
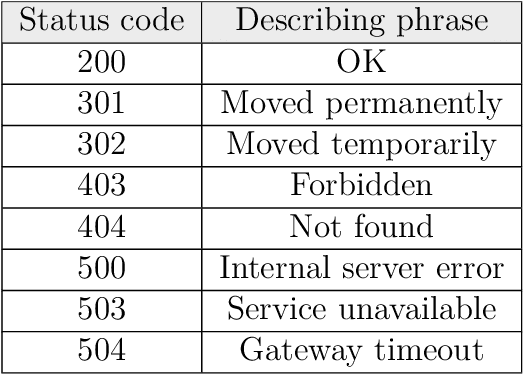
This master thesis addresses the subject of automatically generating a dataset for image recognition, which takes a lot of time when being done manually. As the thesis was written with motivation from the context of the biodiversity workgroup at the City University of Applied Sciences Bremen, the classification of taxonomic entries was chosen as an exemplary use case. In order to automate the dataset creation, a prototype was conceptualized and implemented after working out knowledge basics and analyzing requirements for it. It makes use of an pre-trained abstract artificial intelligence which is able to sort out images that do not contain the desired content. Subsequent to the implementation and the automated dataset creation resulting from it, an evaluation was performed. Other, manually collected datasets were compared to the one the prototype produced in means of specifications and accuracy. The results were more than satisfactory and showed that automatically generating a dataset for image recognition is not only possible, but also might be a decent alternative to spending time and money in doing this task manually. At the very end of this work, an idea of how to use the principle of employing abstract artificial intelligences for step-by-step classification of deeper taxonomic layers in a productive system is presented and discussed.
L^2UWE: A Framework for the Efficient Enhancement of Low-Light Underwater Images Using Local Contrast and Multi-Scale Fusion
May 28, 2020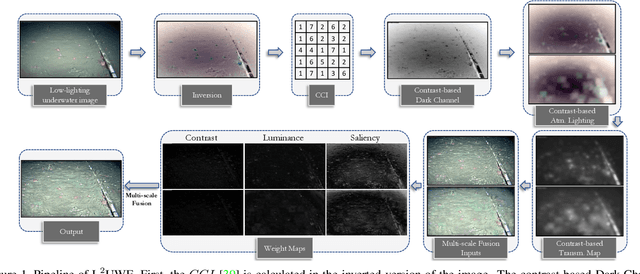
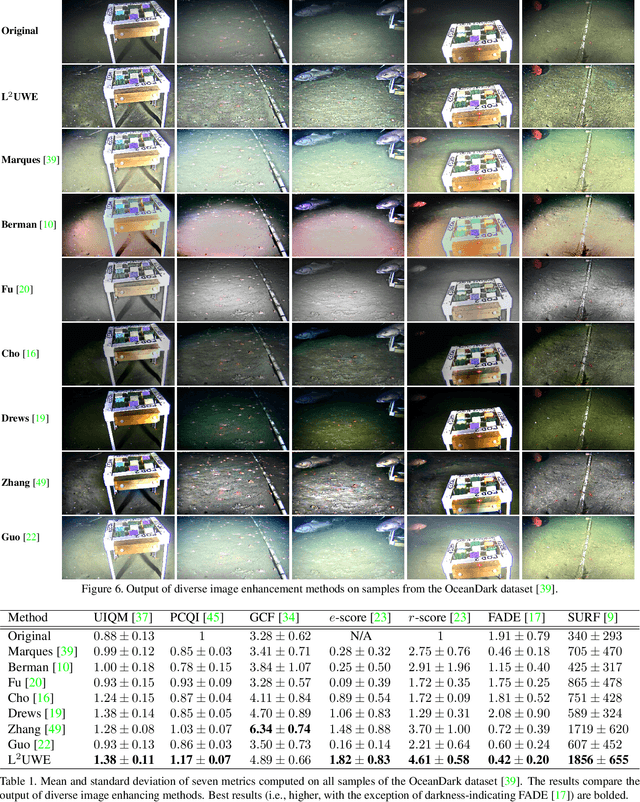
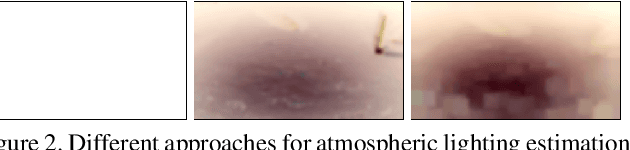

Images captured underwater often suffer from suboptimal illumination settings that can hide important visual features, reducing their quality. We present a novel single-image low-light underwater image enhancer, L^2UWE, that builds on our observation that an efficient model of atmospheric lighting can be derived from local contrast information. We create two distinct models and generate two enhanced images from them: one that highlights finer details, the other focused on darkness removal. A multi-scale fusion process is employed to combine these images while emphasizing regions of higher luminance, saliency and local contrast. We demonstrate the performance of L^2UWE by using seven metrics to test it against seven state-of-the-art enhancement methods specific to underwater and low-light scenes.
L-CNN: A Lattice cross-fusion strategy for multistream convolutional neural networks
Aug 01, 2020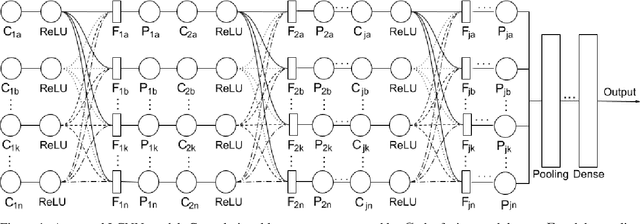
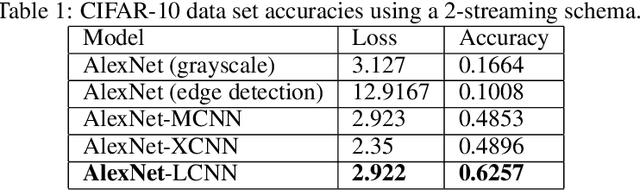
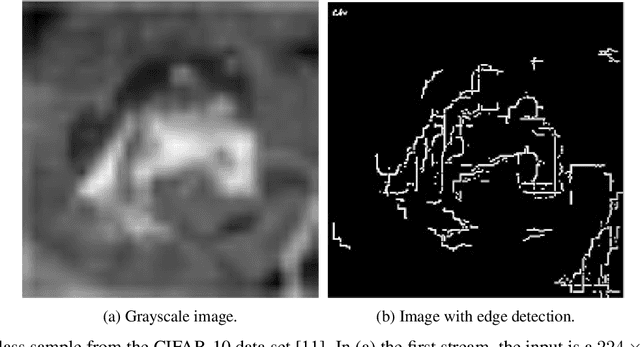
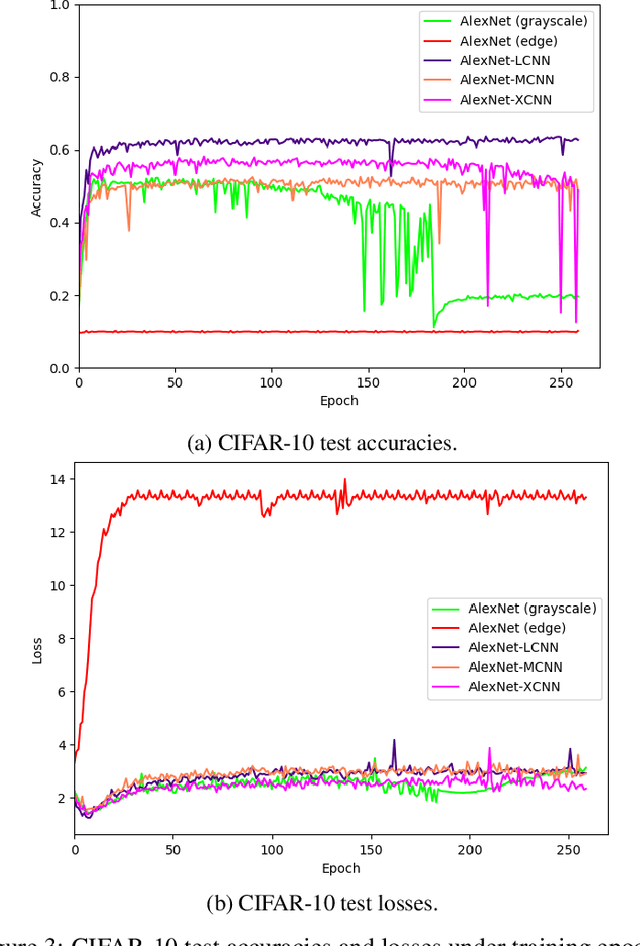
This paper proposes a fusion strategy for multistream convolutional networks, the Lattice Cross Fusion. This approach crosses signals from convolution layers performing mathematical operation-based fusions right before pooling layers. Results on a purposely worsened CIFAR-10, a popular image classification data set, with a modified AlexNet-LCNN version show that this novel method outperforms by 46% the baseline single stream network, with faster convergence, stability, and robustness.
* 5 pages, 3 figures
Nodule2vec: a 3D Deep Learning System for Pulmonary Nodule Retrieval Using Semantic Representation
Jul 11, 2020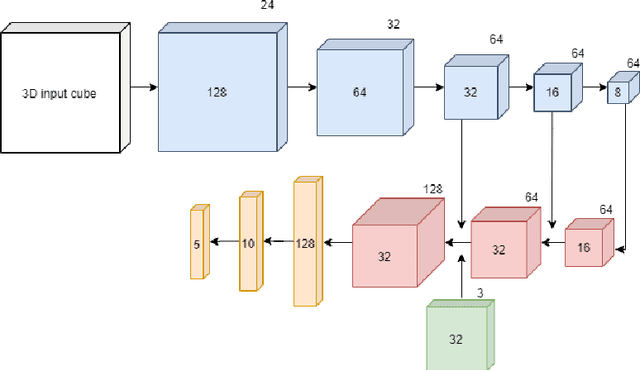
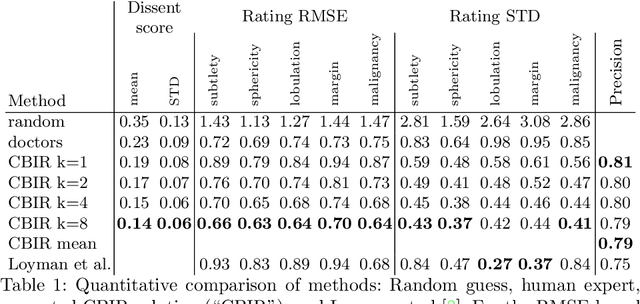
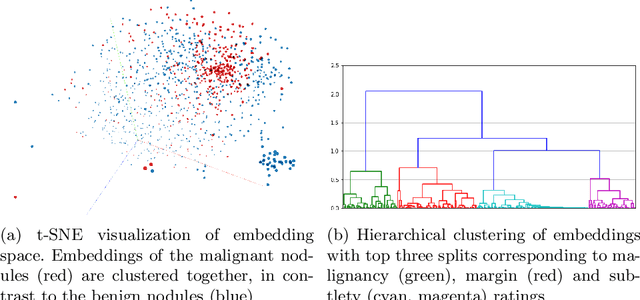
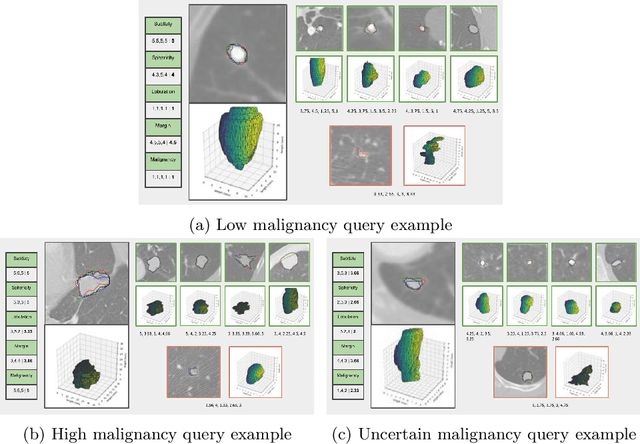
Content-based retrieval supports a radiologist decision making process by presenting the doctor the most similar cases from the database containing both historical diagnosis and further disease development history. We present a deep learning system that transforms a 3D image of a pulmonary nodule from a CT scan into a low-dimensional embedding vector. We demonstrate that such a vector representation preserves semantic information about the nodule and offers a viable approach for content-based image retrieval (CBIR). We discuss the theoretical limitations of the available datasets and overcome them by applying transfer learning of the state-of-the-art lung nodule detection model. We evaluate the system using the LIDC-IDRI dataset of thoracic CT scans. We devise a similarity score and show that it can be utilized to measure similarity 1) between annotations of the same nodule by different radiologists and 2) between the query nodule and the top four CBIR results. A comparison between doctors and algorithm scores suggests that the benefit provided by the system to the radiologist end-user is comparable to obtaining a second radiologist's opinion.
Meaningful uncertainties from deep neural network surrogates of large-scale numerical simulations
Oct 26, 2020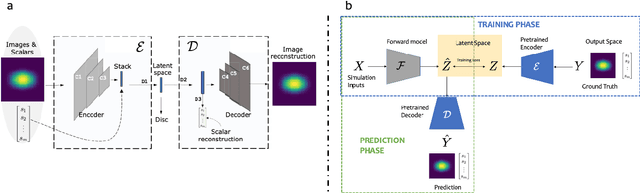
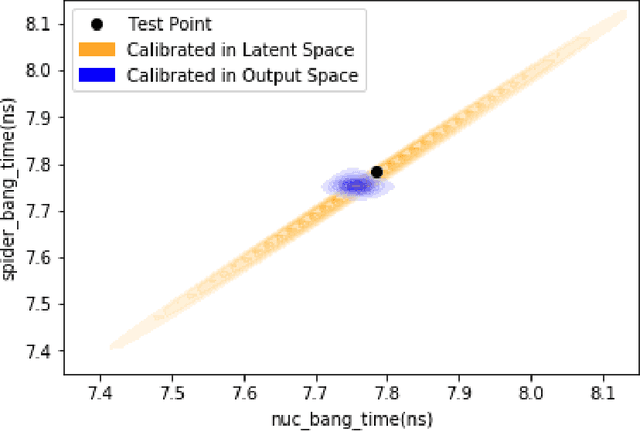
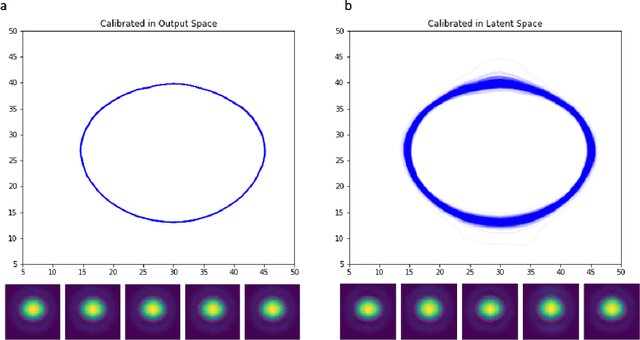
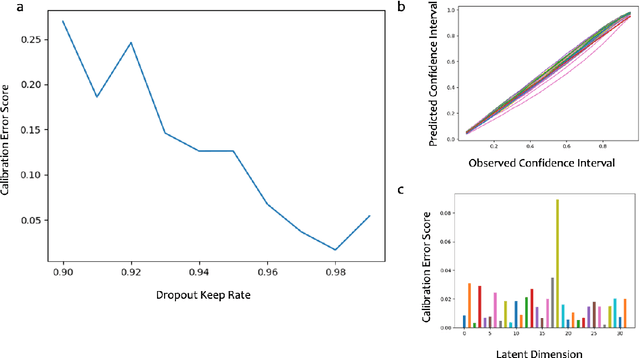
Large-scale numerical simulations are used across many scientific disciplines to facilitate experimental development and provide insights into underlying physical processes, but they come with a significant computational cost. Deep neural networks (DNNs) can serve as highly-accurate surrogate models, with the capacity to handle diverse datatypes, offering tremendous speed-ups for prediction and many other downstream tasks. An important use-case for these surrogates is the comparison between simulations and experiments; prediction uncertainty estimates are crucial for making such comparisons meaningful, yet standard DNNs do not provide them. In this work we define the fundamental requirements for a DNN to be useful for scientific applications, and demonstrate a general variational inference approach to equip predictions of scalar and image data from a DNN surrogate model trained on inertial confinement fusion simulations with calibrated Bayesian uncertainties. Critically, these uncertainties are interpretable, meaningful and preserve physics-correlations in the predicted quantities.
Self-Calibration of Cameras with Euclidean Image Plane in Case of Two Views and Known Relative Rotation Angle
Jul 30, 2018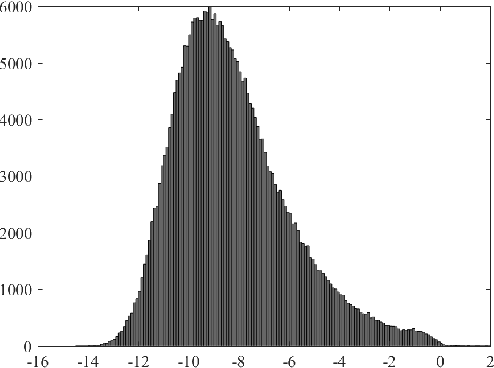
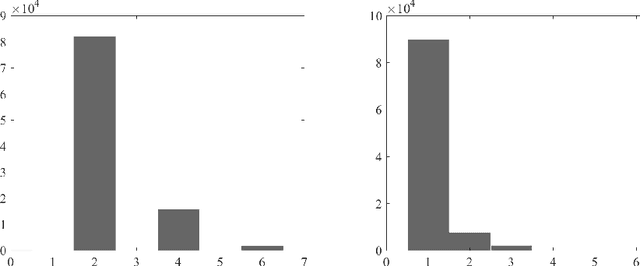
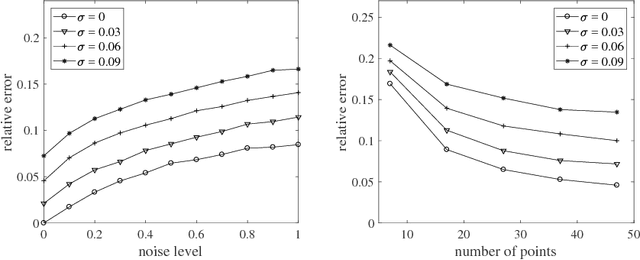
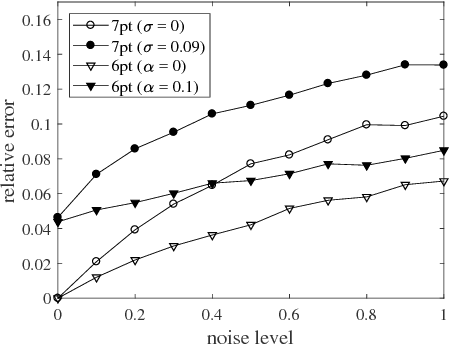
The internal calibration of a pinhole camera is given by five parameters that are combined into an upper-triangular $3\times 3$ calibration matrix. If the skew parameter is zero and the aspect ratio is equal to one, then the camera is said to have Euclidean image plane. In this paper, we propose a non-iterative self-calibration algorithm for a camera with Euclidean image plane in case the remaining three internal parameters --- the focal length and the principal point coordinates --- are fixed but unknown. The algorithm requires a set of $N \geq 7$ point correspondences in two views and also the measured relative rotation angle between the views. We show that the problem generically has six solutions (including complex ones). The algorithm has been implemented and tested both on synthetic data and on publicly available real dataset. The experiments demonstrate that the method is correct, numerically stable and robust.
* 13 pages, 7 eps-figures
Improving Training on Noisy Stuctured Labels
Mar 08, 2020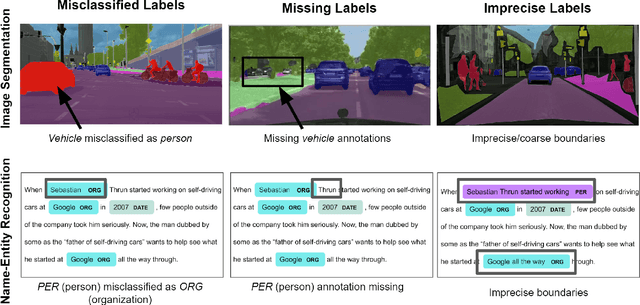
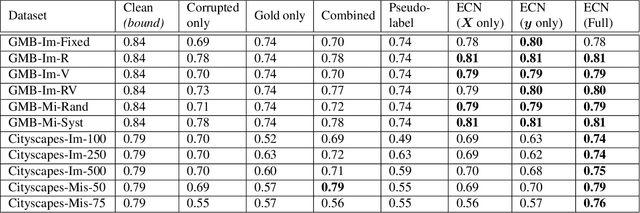
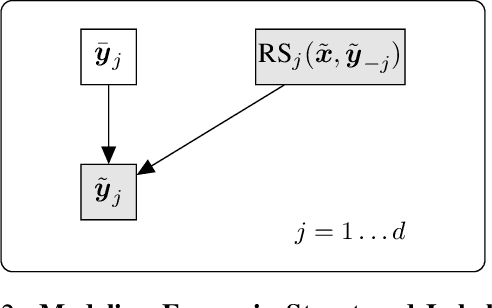
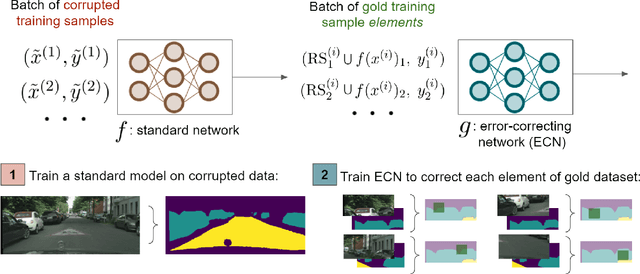
Fine-grained annotations---e.g. dense image labels, image segmentation and text tagging---are useful in many ML applications but they are labor-intensive to generate. Moreover there are often systematic, structured errors in these fine-grained annotations. For example, a car might be entirely unannotated in the image, or the boundary between a car and street might only be coarsely annotated. Standard ML training on data with such structured errors produces models with biases and poor performance. In this work, we propose a novel framework of Error-Correcting Networks (ECN) to address the challenge of learning in the presence structured error in fine-grained annotations. Given a large noisy dataset with commonly occurring structured errors, and a much smaller dataset with more accurate annotations, ECN is able to substantially improve the prediction of fine-grained annotations compared to standard approaches for training on noisy data. It does so by learning to leverage the structures in the annotations and in the noisy labels. Systematic experiments on image segmentation and text tagging demonstrate the strong performance of ECN in improving training on noisy structured labels.