 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
DynaVSR: Dynamic Adaptive Blind Video Super-Resolution
Nov 09, 2020

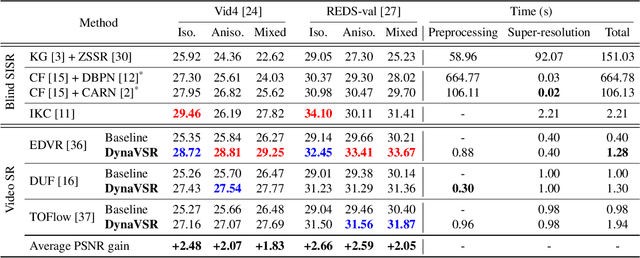
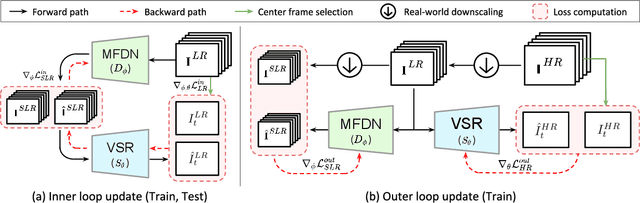
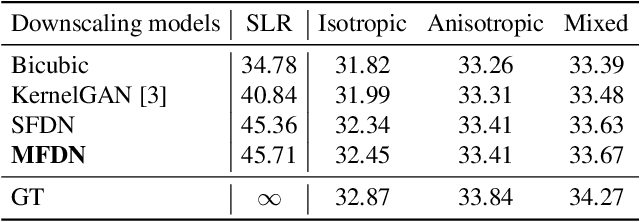
Most conventional supervised super-resolution (SR) algorithms assume that low-resolution (LR) data is obtained by downscaling high-resolution (HR) data with a fixed known kernel, but such an assumption often does not hold in real scenarios. Some recent blind SR algorithms have been proposed to estimate different downscaling kernels for each input LR image. However, they suffer from heavy computational overhead, making them infeasible for direct application to videos. In this work, we present DynaVSR, a novel meta-learning-based framework for real-world video SR that enables efficient downscaling model estimation and adaptation to the current input. Specifically, we train a multi-frame downscaling module with various types of synthetic blur kernels, which is seamlessly combined with a video SR network for input-aware adaptation. Experimental results show that DynaVSR consistently improves the performance of the state-of-the-art video SR models by a large margin, with an order of magnitude faster inference time compared to the existing blind SR approaches.
Towards Visually Explaining Similarity Models
Aug 13, 2020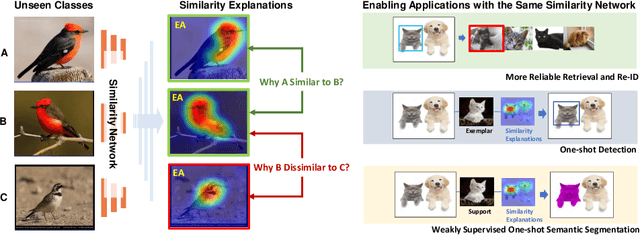
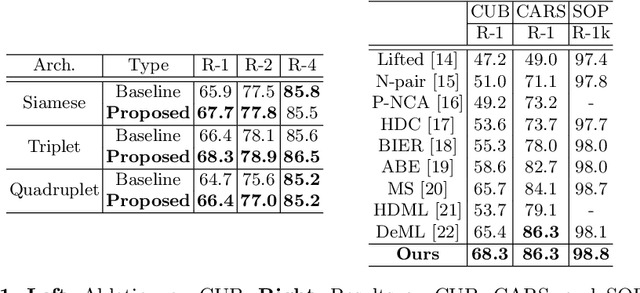


We consider the problem of visually explaining similarity models, i.e., explaining why a model predicts two images to be similar in addition to producing a scalar score. While much recent work in visual model interpretability has focused on gradient-based attention, these methods rely on a classification module to generate visual explanations. Consequently, they cannot readily explain other kinds of models that do not use or need classification-like loss functions (e.g., similarity models trained with a metric learning loss). In this work, we bridge this crucial gap, presenting the first method to generate gradient-based visual explanations for image similarity predictors. By relying solely on the learned feature embedding, we show that our approach can be applied to any kind of CNN-based similarity architecture, an important step towards generic visual explainability. We show that our resulting visual explanations serve more than just interpretability; they can be infused into the model learning process itself with new trainable constraints based on our similarity explanations. We show that the resulting similarity models perform, and can be visually explained, better than the corresponding baseline models trained without our explanation constraints. We demonstrate our approach using extensive experiments on three different kinds of tasks: generic image retrieval, person re-identification, and low-shot semantic segmentation.
Inverse problems with second-order Total Generalized Variation constraints
May 19, 2020

Total Generalized Variation (TGV) has recently been introduced as penalty functional for modelling images with edges as well as smooth variations. It can be interpreted as a "sparse" penalization of optimal balancing from the first up to the $k$-th distributional derivative and leads to desirable results when applied to image denoising, i.e., $L^2$-fitting with TGV penalty. The present paper studies TGV of second order in the context of solving ill-posed linear inverse problems. Existence and stability for solutions of Tikhonov-functional minimization with respect to the data is shown and applied to the problem of recovering an image from blurred and noisy data.
* Published in 2011 as a conference proceeding. Uploaded in 2020 on arXiv to ensure availability: the original proceedings are no longer online
Towards Domain-Agnostic Contrastive Learning
Nov 09, 2020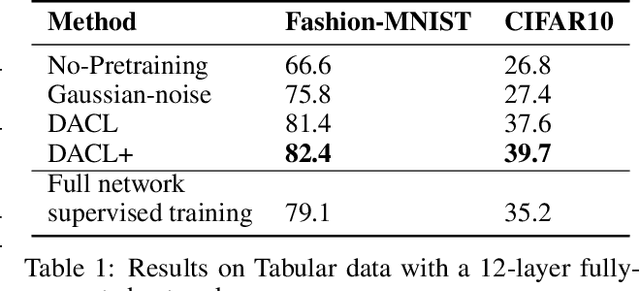
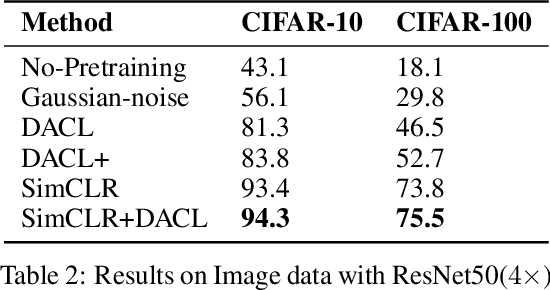
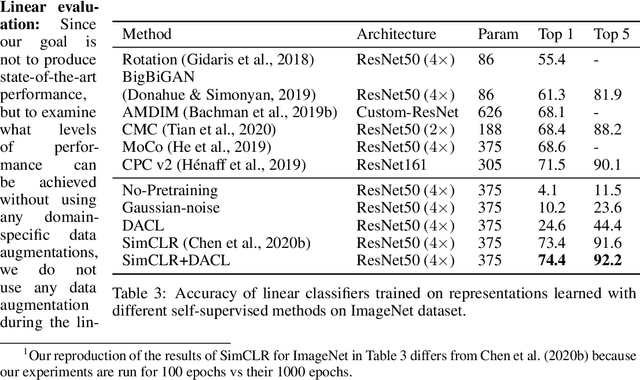

Despite recent success, most contrastive self-supervised learning methods are domain-specific, relying heavily on data augmentation techniques that require knowledge about a particular domain, such as image cropping and rotation. To overcome such limitation, we propose a novel domain-agnostic approach to contrastive learning, named DACL, that is applicable to domains where invariances, and thus, data augmentation techniques, are not readily available. Key to our approach is the use of Mixup noise to create similar and dissimilar examples by mixing data samples differently either at the input or hidden-state levels. To demonstrate the effectiveness of DACL, we conduct experiments across various domains such as tabular data, images, and graphs. Our results show that DACL not only outperforms other domain-agnostic noising methods, such as Gaussian-noise, but also combines well with domain-specific methods, such as SimCLR, to improve self-supervised visual representation learning. Finally, we theoretically analyze our method and show advantages over the Gaussian-noise based contrastive learning approach.
Iterative Knowledge Exchange Between Deep Learning and Space-Time Spectral Clustering for Unsupervised Segmentation in Videos
Dec 13, 2020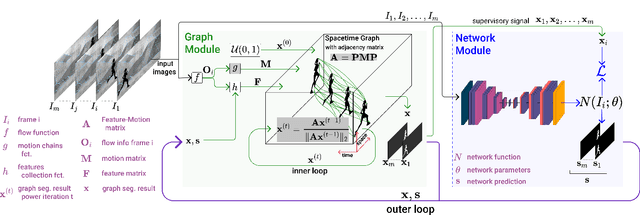
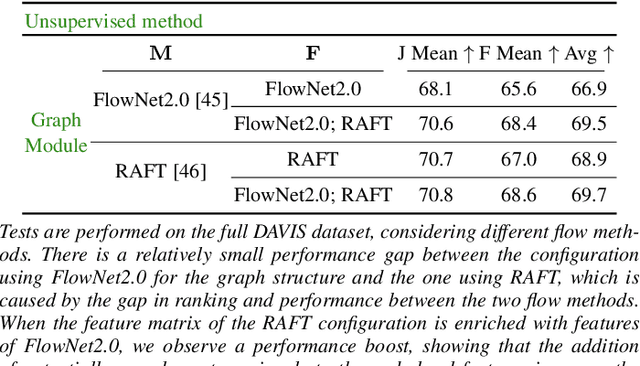
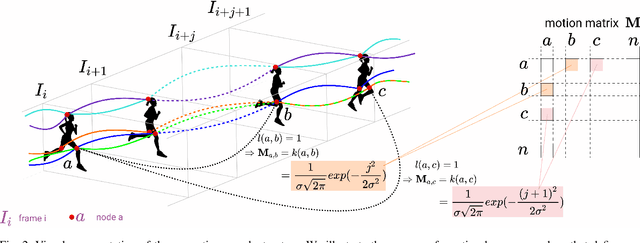
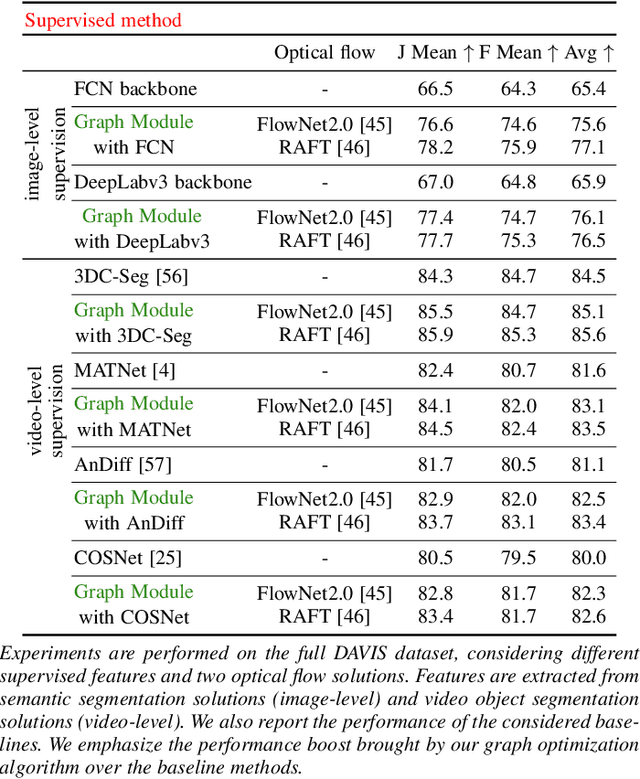
We propose a dual system for unsupervised object segmentation in video, which brings together two modules with complementary properties: a space-time graph that discovers objects in videos and a deep network that learns powerful object features. The system uses an iterative knowledge exchange policy. A novel spectral space-time clustering process on the graph produces unsupervised segmentation masks passed to the network as pseudo-labels. The net learns to segment in single frames what the graph discovers in video and passes back to the graph strong image-level features that improve its node-level features in the next iteration. Knowledge is exchanged for several cycles until convergence. The graph has one node per each video pixel, but the object discovery is fast. It uses a novel power iteration algorithm computing the main space-time cluster as the principal eigenvector of a special Feature-Motion matrix without actually computing the matrix. The thorough experimental analysis validates our theoretical claims and proves the effectiveness of the cyclical knowledge exchange. We also perform experiments on the supervised scenario, incorporating features pretrained with human supervision. We achieve state-of-the-art level on unsupervised and supervised scenarios on four challenging datasets: DAVIS, SegTrack, YouTube-Objects, and DAVSOD.
Multi-channel Weighted Nuclear Norm Minimization for Real Color Image Denoising
May 28, 2017
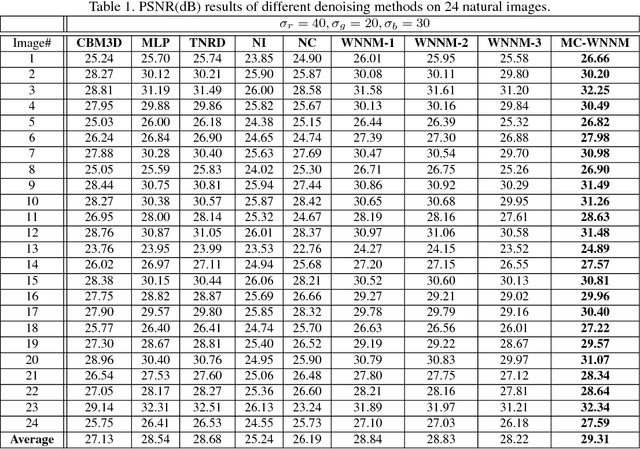

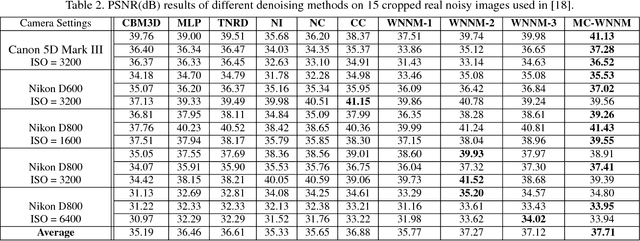
Most of the existing denoising algorithms are developed for grayscale images, while it is not a trivial work to extend them for color image denoising because the noise statistics in R, G, B channels can be very different for real noisy images. In this paper, we propose a multi-channel (MC) optimization model for real color image denoising under the weighted nuclear norm minimization (WNNM) framework. We concatenate the RGB patches to make use of the channel redundancy, and introduce a weight matrix to balance the data fidelity of the three channels in consideration of their different noise statistics. The proposed MC-WNNM model does not have an analytical solution. We reformulate it into a linear equality-constrained problem and solve it with the alternating direction method of multipliers. Each alternative updating step has closed-form solution and the convergence can be guaranteed. Extensive experiments on both synthetic and real noisy image datasets demonstrate the superiority of the proposed MC-WNNM over state-of-the-art denoising methods.
Single image super-resolution using self-optimizing mask via fractional-order gradient interpolation and reconstruction
Mar 18, 2017

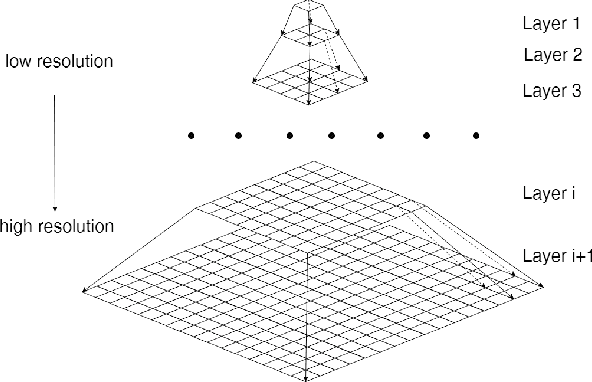
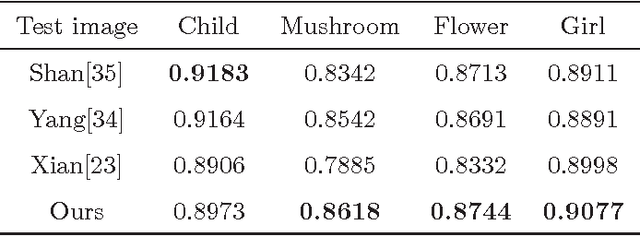
Image super-resolution using self-optimizing mask via fractional-order gradient interpolation and reconstruction aims to recover detailed information from low-resolution images and reconstruct them into high-resolution images. Due to the limited amount of data and information retrieved from low-resolution images, it is difficult to restore clear, artifact-free images, while still preserving enough structure of the image such as the texture. This paper presents a new single image super-resolution method which is based on adaptive fractional-order gradient interpolation and reconstruction. The interpolated image gradient via optimal fractional-order gradient is first constructed according to the image similarity and afterwards the minimum energy function is employed to reconstruct the final high-resolution image. Fractional-order gradient based interpolation methods provide an additional degree of freedom which helps optimize the implementation quality due to the fact that an extra free parameter $\alpha$-order is being used. The proposed method is able to produce a rich texture detail while still being able to maintain structural similarity even under large zoom conditions. Experimental results show that the proposed method performs better than current single image super-resolution techniques.
AutoInt: Automatic Integration for Fast Neural Volume Rendering
Dec 03, 2020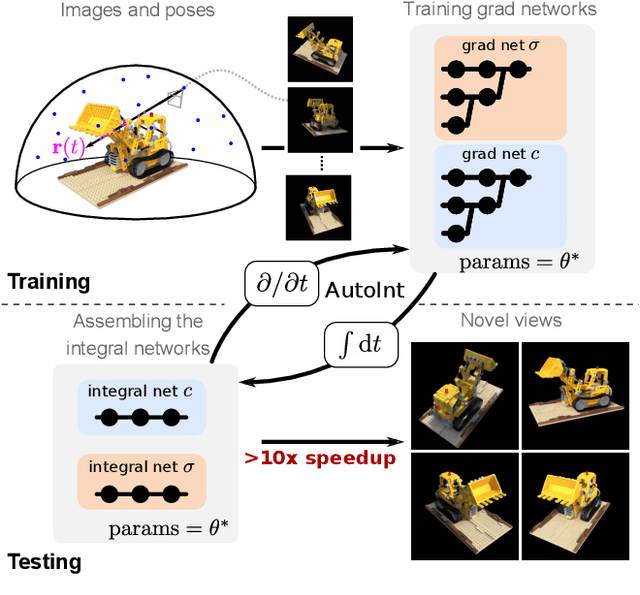
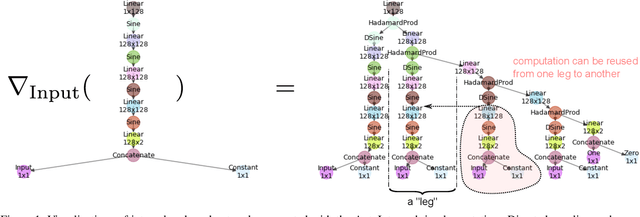
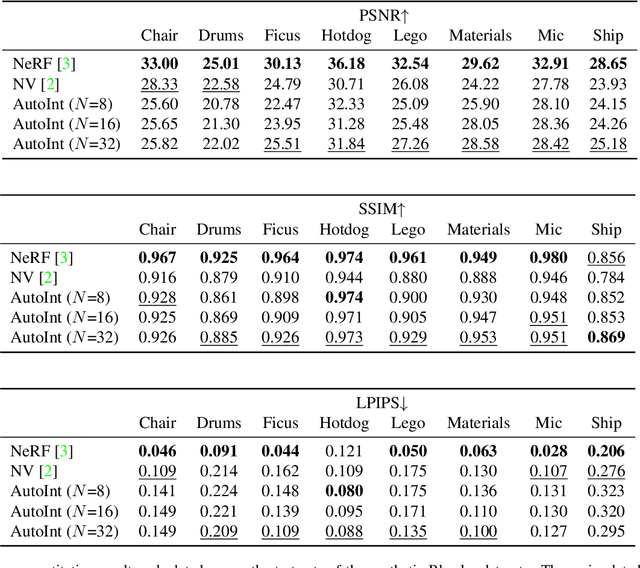
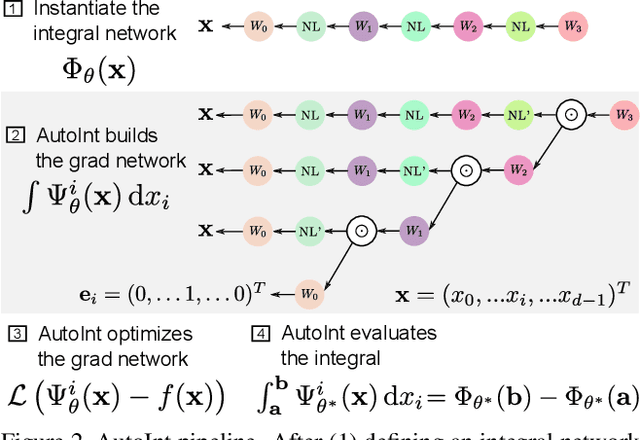
Numerical integration is a foundational technique in scientific computing and is at the core of many computer vision applications. Among these applications, implicit neural volume rendering has recently been proposed as a new paradigm for view synthesis, achieving photorealistic image quality. However, a fundamental obstacle to making these methods practical is the extreme computational and memory requirements caused by the required volume integrations along the rendered rays during training and inference. Millions of rays, each requiring hundreds of forward passes through a neural network are needed to approximate those integrations with Monte Carlo sampling. Here, we propose automatic integration, a new framework for learning efficient, closed-form solutions to integrals using implicit neural representation networks. For training, we instantiate the computational graph corresponding to the derivative of the implicit neural representation. The graph is fitted to the signal to integrate. After optimization, we reassemble the graph to obtain a network that represents the antiderivative. By the fundamental theorem of calculus, this enables the calculation of any definite integral in two evaluations of the network. Using this approach, we demonstrate a greater than 10x improvement in computation requirements, enabling fast neural volume rendering.
Size-to-depth: A New Perspective for Single Image Depth Estimation
Jan 13, 2018
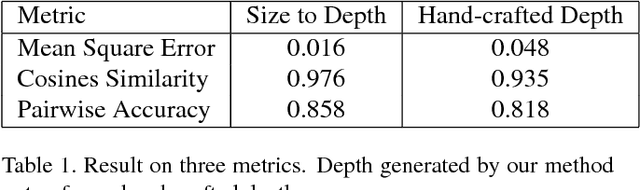


In this paper we consider the problem of single monocular image depth estimation. It is a challenging problem due to its ill-posedness nature and has found wide application in industry. Previous efforts belongs roughly to two families: learning-based method and interactive method. Learning-based method, in which deep convolutional neural network (CNN) is widely used, can achieve good result. But they suffer low generalization ability and typically perform poorly for unfamiliar scenes. Besides, data-hungry nature for such method makes data aquisition expensive and time-consuming. Interactive method requires human annotation of depth which, however, is errorneous and of large variance. To overcome these problems, we propose a new perspective for single monocular image depth estimation problem: size to depth. Our method require sparse label for real-world size of object rather than raw depth. A Coarse depth map is then inferred following geometric relationships according to size labels. Then we refine the depth map by doing energy function optimization on conditional random field(CRF). We experimentally demonstrate that our method outperforms traditional depth-labeling methods and can produce satisfactory depth maps.
Curious Case of Language Generation Evaluation Metrics: A Cautionary Tale
Oct 26, 2020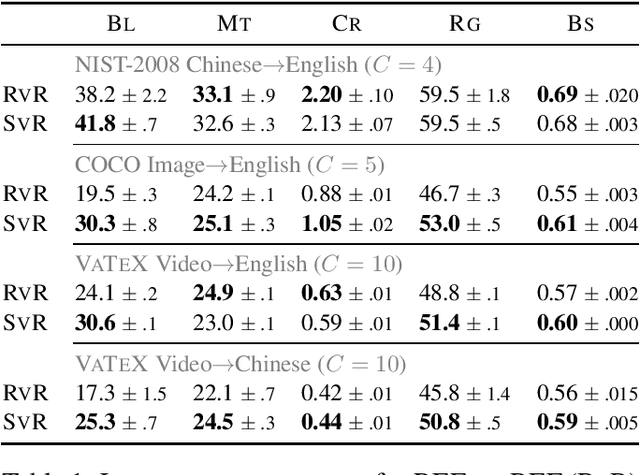
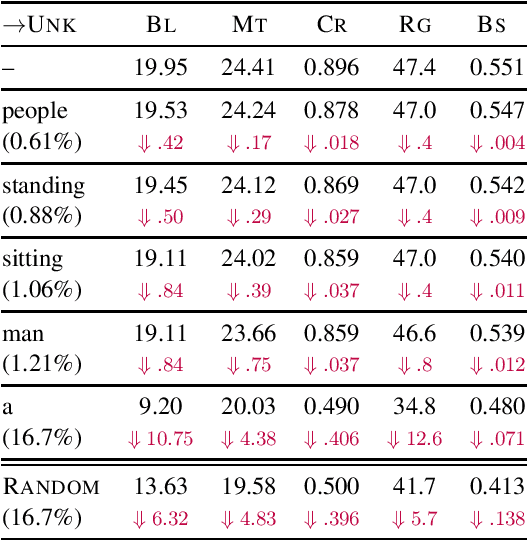
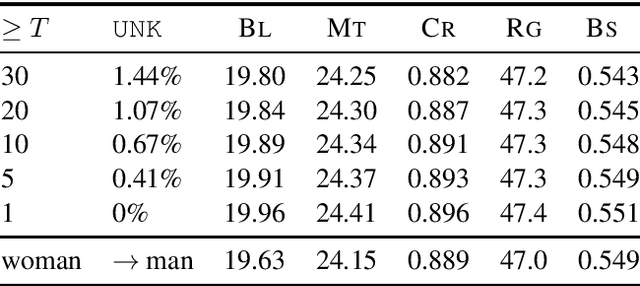
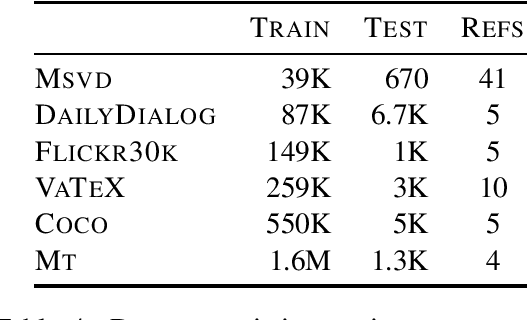
Automatic evaluation of language generation systems is a well-studied problem in Natural Language Processing. While novel metrics are proposed every year, a few popular metrics remain as the de facto metrics to evaluate tasks such as image captioning and machine translation, despite their known limitations. This is partly due to ease of use, and partly because researchers expect to see them and know how to interpret them. In this paper, we urge the community for more careful consideration of how they automatically evaluate their models by demonstrating important failure cases on multiple datasets, language pairs and tasks. Our experiments show that metrics (i) usually prefer system outputs to human-authored texts, (ii) can be insensitive to correct translations of rare words, (iii) can yield surprisingly high scores when given a single sentence as system output for the entire test set.