 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Time-Ordered Recent Event (TORE) Volumes for Event Cameras
Mar 10, 2021
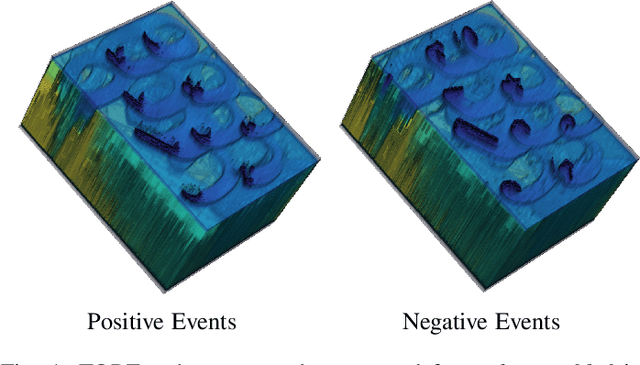

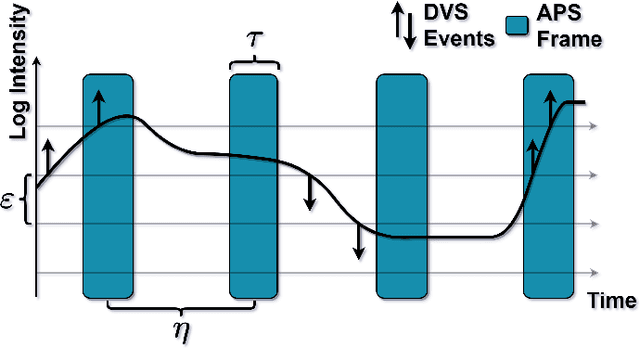
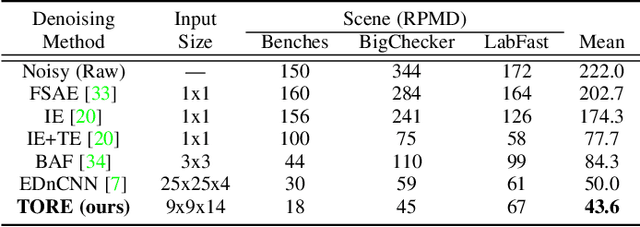
Event cameras are an exciting, new sensor modality enabling high-speed imaging with extremely low-latency and wide dynamic range. Unfortunately, most machine learning architectures are not designed to directly handle sparse data, like that generated from event cameras. Many state-of-the-art algorithms for event cameras rely on interpolated event representations - obscuring crucial timing information, increasing the data volume, and limiting overall network performance. This paper details an event representation called Time-Ordered Recent Event (TORE) volumes. TORE volumes are designed to compactly store raw spike timing information with minimal information loss. This bio-inspired design is memory efficient, computationally fast, avoids time-blocking (i.e. fixed and predefined frame rates), and contains "local memory" from past data. The design is evaluated on a wide range of challenging tasks (e.g. event denoising, image reconstruction, classification, and human pose estimation) and is shown to dramatically improve state-of-the-art performance. TORE volumes are an easy-to-implement replacement for any algorithm currently utilizing event representations.
Residual Learning for Effective joint Demosaicing-Denoising
Sep 14, 2020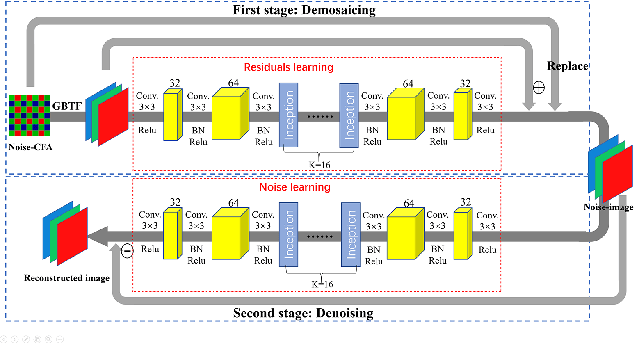
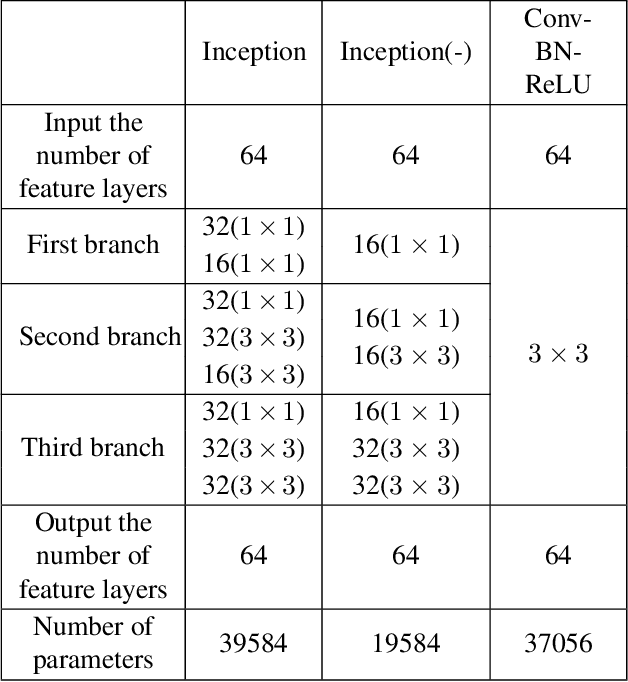
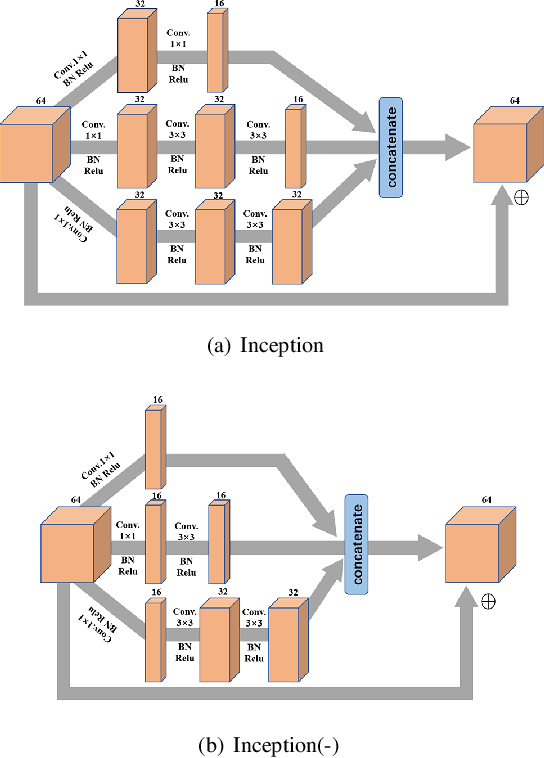
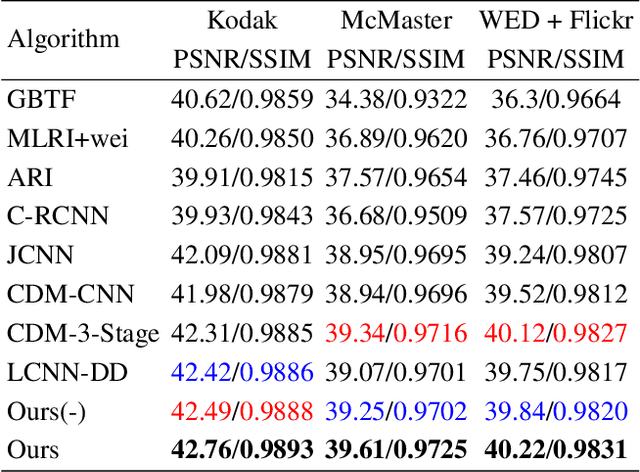
Image demosaicing and denoising are key steps for color image production pipeline. The classical processing sequence consists in applying denoising first, and then demosaicing. However, this sequence leads to oversmoothing and unpleasant checkerboard effect. Moreover, it is very difficult to change this order, because once the image is demosaiced, the statistical properties of the noise will be changed dramatically. This is extremely challenging for the traditional denoising models that strongly rely on statistical assumptions. In this paper, we attempt to tackle this prickly problem. Indeed, here we invert the traditional CFA processing pipeline by first applying demosaicing and then using an adapted denoising. In order to obtain high-quality demosaicing of noiseless images, we combine the advantages of traditional algorithms with deep learning. This is achieved by training convolutional neural networks (CNNs) to learn the residuals of traditional algorithms. To improve the performance in image demosaicing we propose a modified Inception architecture. Given the trained demosaicing as a basic component, we apply it to noisy images and use another CNN to learn the residual noise (including artifacts) of the demosaiced images, which allows to reconstruct full color images. Experimental results show clearly that this method outperforms several state-of-the-art methods both quantitatively as well as in terms of visual quality.
Finding Person Relations in Image Data of the Internet Archive
Jun 21, 2018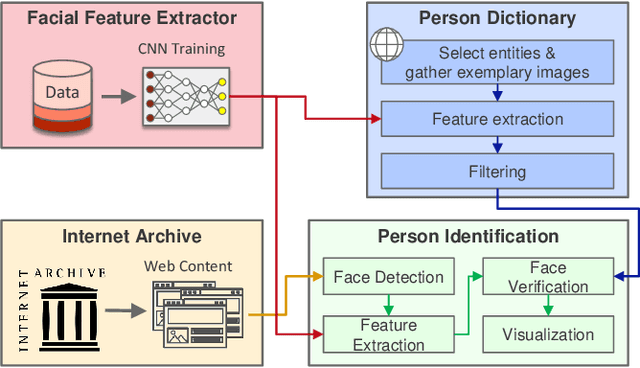

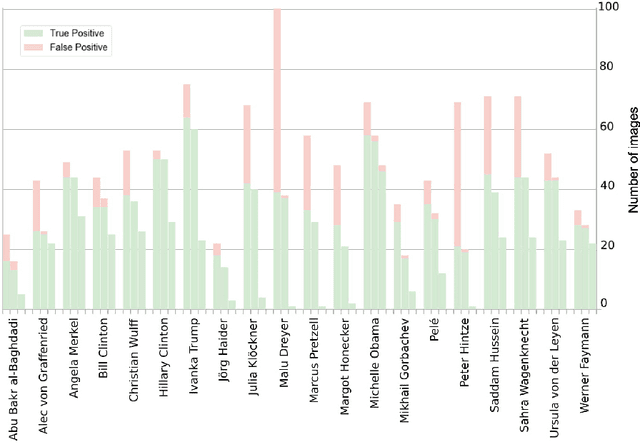
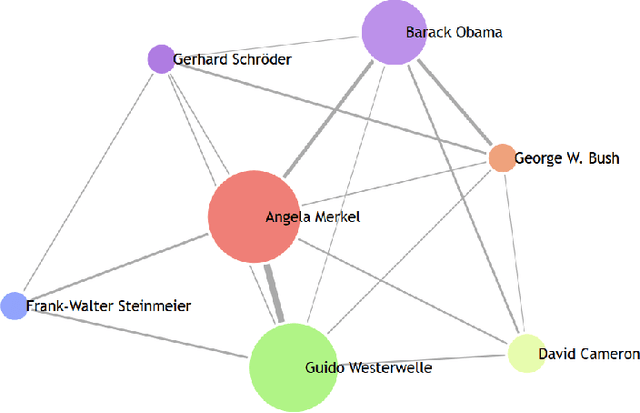
The multimedia content in the World Wide Web is rapidly growing and contains valuable information for many applications in different domains. For this reason, the Internet Archive initiative has been gathering billions of time-versioned web pages since the mid-nineties. However, the huge amount of data is rarely labeled with appropriate metadata and automatic approaches are required to enable semantic search. Normally, the textual content of the Internet Archive is used to extract entities and their possible relations across domains such as politics and entertainment, whereas image and video content is usually neglected. In this paper, we introduce a system for person recognition in image content of web news stored in the Internet Archive. Thus, the system complements entity recognition in text and allows researchers and analysts to track media coverage and relations of persons more precisely. Based on a deep learning face recognition approach, we suggest a system that automatically detects persons of interest and gathers sample material, which is subsequently used to identify them in the image data of the Internet Archive. We evaluate the performance of the face recognition system on an appropriate standard benchmark dataset and demonstrate the feasibility of the approach with two use cases.
Variational models for signal processing with Graph Neural Networks
Mar 30, 2021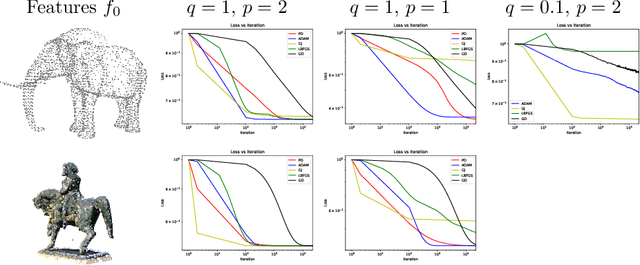
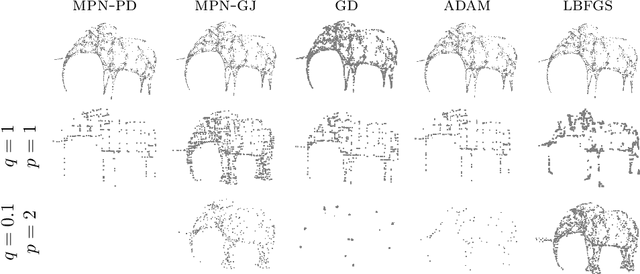

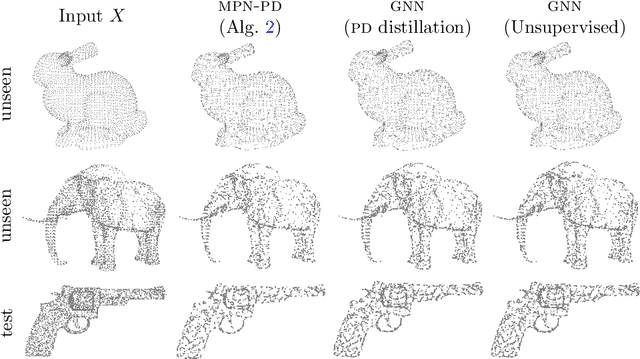
This paper is devoted to signal processing on point-clouds by means of neural networks. Nowadays, state-of-the-art in image processing and computer vision is mostly based on training deep convolutional neural networks on large datasets. While it is also the case for the processing of point-clouds with Graph Neural Networks (GNN), the focus has been largely given to high-level tasks such as classification and segmentation using supervised learning on labeled datasets such as ShapeNet. Yet, such datasets are scarce and time-consuming to build depending on the target application. In this work, we investigate the use of variational models for such GNN to process signals on graphs for unsupervised learning.Our contributions are two-fold. We first show that some existing variational-based algorithms for signals on graphs can be formulated as Message Passing Networks (MPN), a particular instance of GNN, making them computationally efficient in practice when compared to standard gradient-based machine learning algorithms. Secondly, we investigate the unsupervised learning of feed-forward GNN, either by direct optimization of an inverse problem or by model distillation from variational-based MPN. Keywords:Graph Processing. Neural Network. Total Variation. Variational Methods. Message Passing Network. Unsupervised learning
Automatic airway segmentation from Computed Tomography using robust and efficient 3-D convolutional neural networks
Mar 30, 2021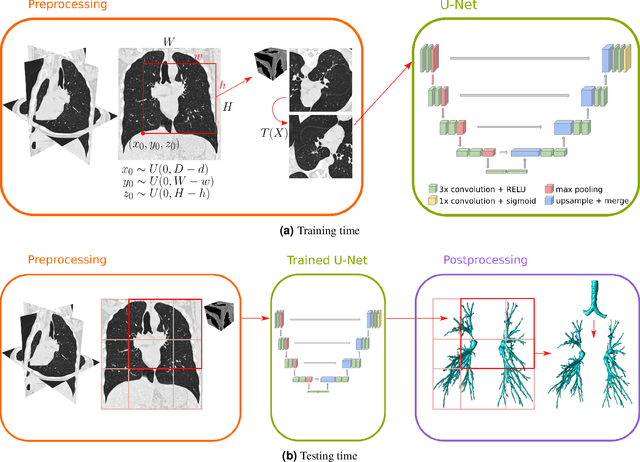
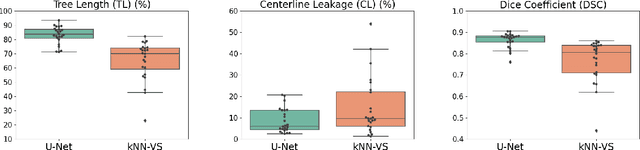
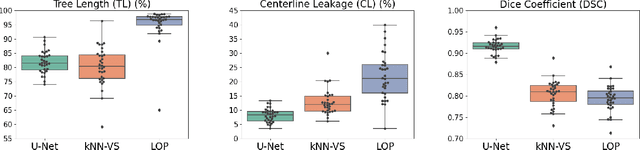
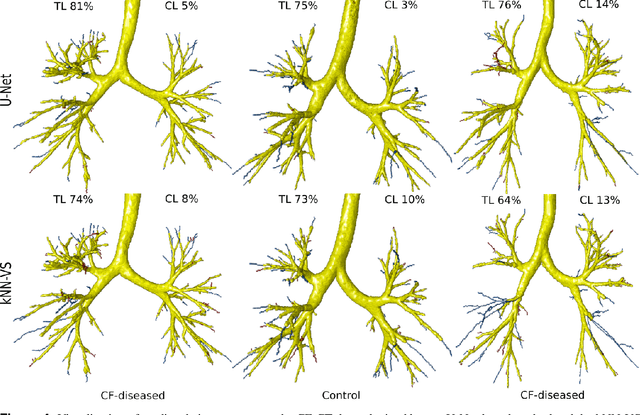
This paper presents a fully automatic and end-to-end optimised airway segmentation method for thoracic computed tomography, based on the U-Net architecture. We use a simple and low-memory 3D U-Net as backbone, which allows the method to process large 3D image patches, often comprising full lungs, in a single pass through the network. This makes the method simple, robust and efficient. We validated the proposed method on three datasets with very different characteristics and various airway abnormalities: i) a dataset of pediatric patients including subjects with cystic fibrosis, ii) a subset of the Danish Lung Cancer Screening Trial, including subjects with chronic obstructive pulmonary disease, and iii) the EXACT'09 public dataset. We compared our method with other state-of-the-art airway segmentation methods, including relevant learning-based methods in the literature evaluated on the EXACT'09 data. We show that our method can extract highly complete airway trees with few false positive errors, on scans from both healthy and diseased subjects, and also that the method generalizes well across different datasets. On the EXACT'09 test set, our method achieved the second highest sensitivity score among all methods that reported good specificity.
Deep Learning Backdoors
Jul 16, 2020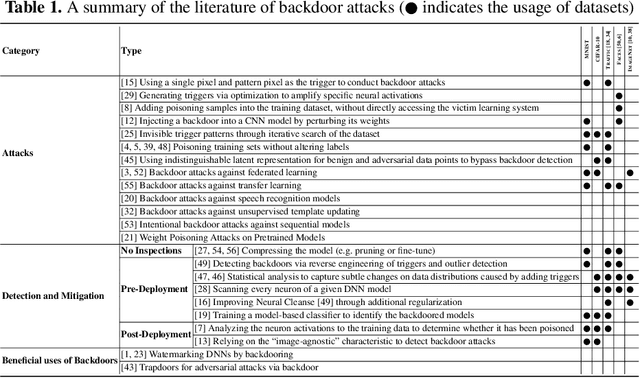
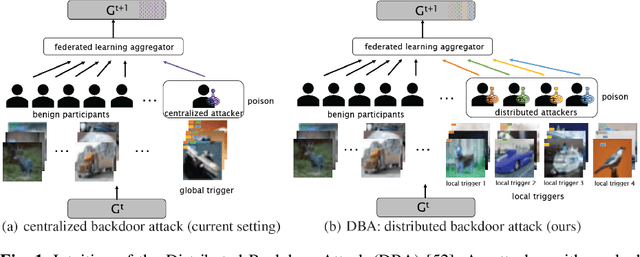
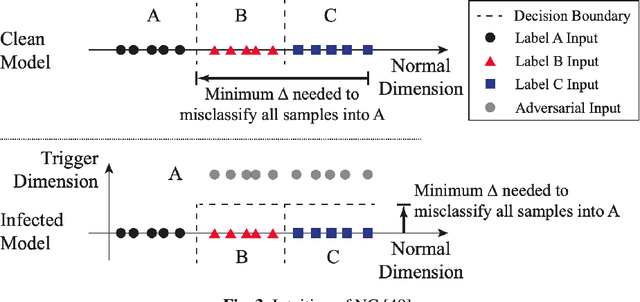
Intuitively, a backdoor attack against Deep Neural Networks (DNNs) is to inject hidden malicious behaviors into DNNs such that the backdoor model behaves legitimately for benign inputs, yet invokes a predefined malicious behavior when its input contains a malicious trigger. The trigger can take a plethora of forms, including a special object present in the image (e.g., a yellow pad), a shape filled with custom textures (e.g., logos with particular colors) or even image-wide stylizations with special filters (e.g., images altered by Nashville or Gotham filters). These filters can be applied to the original image by replacing or perturbing a set of image pixels.
Image Retrieval with Mixed Initiative and Multimodal Feedback
May 08, 2018

How would you search for a unique, fashionable shoe that a friend wore and you want to buy, but you didn't take a picture? Existing approaches propose interactive image search as a promising venue. However, they either entrust the user with taking the initiative to provide informative feedback, or give all control to the system which determines informative questions to ask. Instead, we propose a mixed-initiative framework where both the user and system can be active participants, depending on whose initiative will be more beneficial for obtaining high-quality search results. We develop a reinforcement learning approach which dynamically decides which of three interaction opportunities to give to the user: drawing a sketch, providing free-form attribute feedback, or answering attribute-based questions. By allowing these three options, our system optimizes both the informativeness and exploration capabilities allowing faster image retrieval. We outperform three baselines on three datasets and extensive experimental settings.
Learning a sparse database for patch-based medical image segmentation
Jun 25, 2019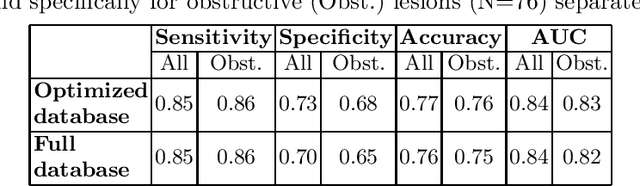
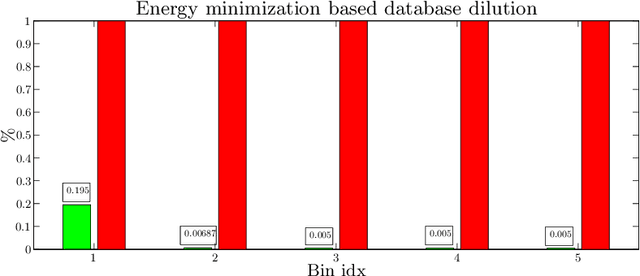

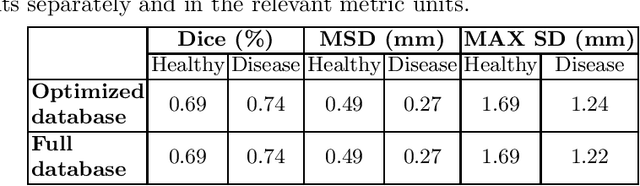
We introduce a functional for the learning of an optimal database for patch-based image segmentation with application to coronary lumen segmentation from coronary computed tomography angiography (CCTA) data. The proposed functional consists of fidelity, sparseness and robustness to small-variations terms and their associated weights. Existing work address database optimization by prototype selection aiming to optimize the database by either adding or removing prototypes according to a set of predefined rules. In contrast, we formulate the database optimization task as an energy minimization problem that can be solved using standard numerical tools. We apply the proposed database optimization functional to the task of optimizing a database for patch-base coronary lumen segmentation. Our experiments using the publicly available MICCAI 2012 coronary lumen segmentation challenge data show that optimizing the database using the proposed approach reduced database size by 96% while maintaining the same level of lumen segmentation accuracy. Moreover, we show that the optimized database yields an improved specificity of CCTA based fractional flow reserve (0.73 vs 0.7 for all lesions and 0.68 vs 0.65 for obstructive lesions) using a training set of 132 (76 obstructive) coronary lesions with invasively measured FFR as the reference.
Artificial intelligence for detection and quantification of rust and leaf miner in coffee crop
Mar 20, 2021



Pest and disease control plays a key role in agriculture since the damage caused by these agents are responsible for a huge economic loss every year. Based on this assumption, we create an algorithm capable of detecting rust (Hemileia vastatrix) and leaf miner (Leucoptera coffeella) in coffee leaves (Coffea arabica) and quantify disease severity using a mobile application as a high-level interface for the model inferences. We used different convolutional neural network architectures to create the object detector, besides the OpenCV library, k-means, and three treatments: the RGB and value to quantification, and the AFSoft software, in addition to the analysis of variance, where we compare the three methods. The results show an average precision of 81,5% in the detection and that there was no significant statistical difference between treatments to quantify the severity of coffee leaves, proposing a computationally less costly method. The application, together with the trained model, can detect the pest and disease over different image conditions and infection stages and also estimate the disease infection stage.
Optimizing the Dice Score and Jaccard Index for Medical Image Segmentation: Theory & Practice
Nov 05, 2019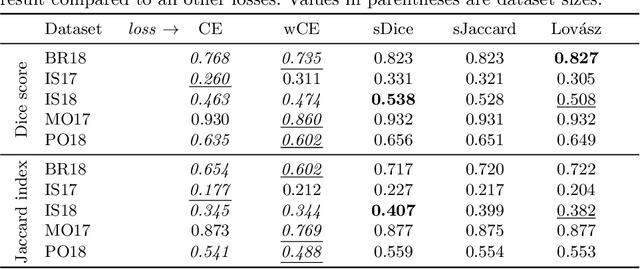
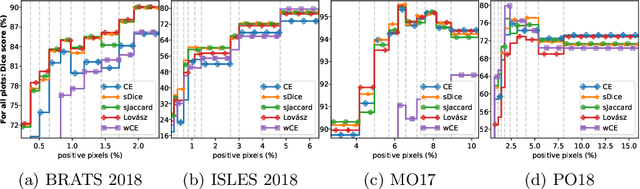
The Dice score and Jaccard index are commonly used metrics for the evaluation of segmentation tasks in medical imaging. Convolutional neural networks trained for image segmentation tasks are usually optimized for (weighted) cross-entropy. This introduces an adverse discrepancy between the learning optimization objective (the loss) and the end target metric. Recent works in computer vision have proposed soft surrogates to alleviate this discrepancy and directly optimize the desired metric, either through relaxations (soft-Dice, soft-Jaccard) or submodular optimization (Lov\'asz-softmax). The aim of this study is two-fold. First, we investigate the theoretical differences in a risk minimization framework and question the existence of a weighted cross-entropy loss with weights theoretically optimized to surrogate Dice or Jaccard. Second, we empirically investigate the behavior of the aforementioned loss functions w.r.t. evaluation with Dice score and Jaccard index on five medical segmentation tasks. Through the application of relative approximation bounds, we show that all surrogates are equivalent up to a multiplicative factor, and that no optimal weighting of cross-entropy exists to approximate Dice or Jaccard measures. We validate these findings empirically and show that, while it is important to opt for one of the target metric surrogates rather than a cross-entropy-based loss, the choice of the surrogate does not make a statistical difference on a wide range of medical segmentation tasks.
* MICCAI 2019