 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Going Full-TILT Boogie on Document Understanding with Text-Image-Layout Transformer
Mar 02, 2021
We address the challenging problem of Natural Language Comprehension beyond plain-text documents by introducing the TILT neural network architecture which simultaneously learns layout information, visual features, and textual semantics. Contrary to previous approaches, we rely on a decoder capable of unifying a variety of problems involving natural language. The layout is represented as an attention bias and complemented with contextualized visual information, while the core of our model is a pretrained encoder-decoder Transformer. Our novel approach achieves state-of-the-art results in extracting information from documents and answering questions which demand layout understanding (DocVQA, CORD, WikiOps, SROIE). At the same time, we simplify the process by employing an end-to-end model.
BigEarthNet: A Large-Scale Benchmark Archive For Remote Sensing Image Understanding
Feb 16, 2019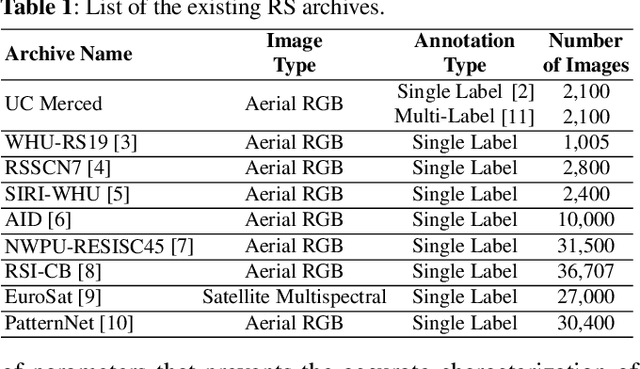

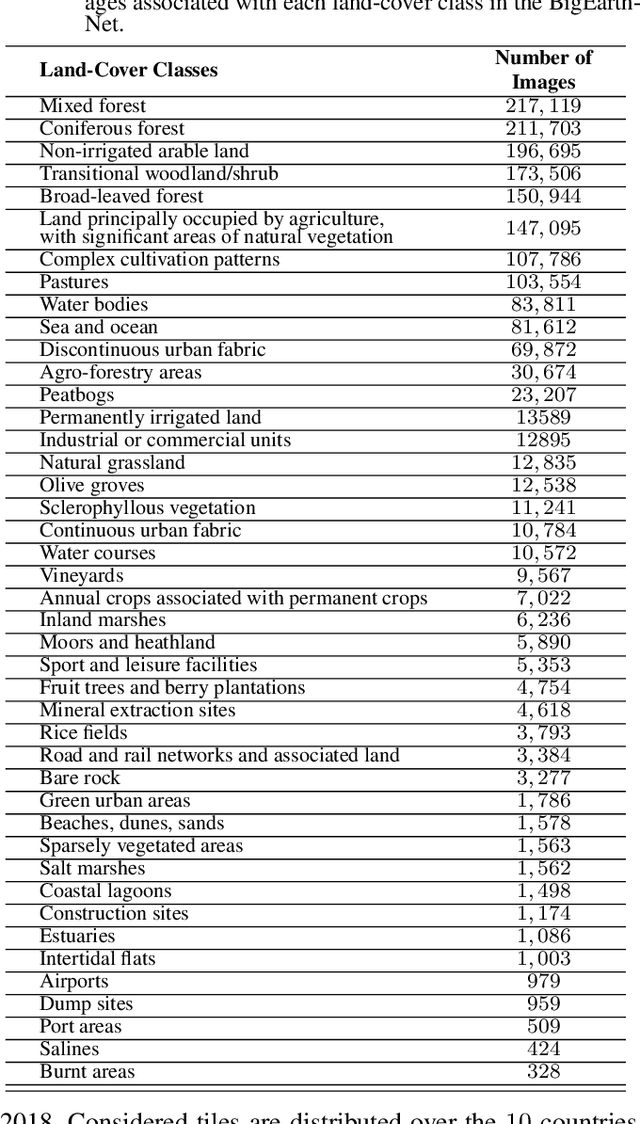
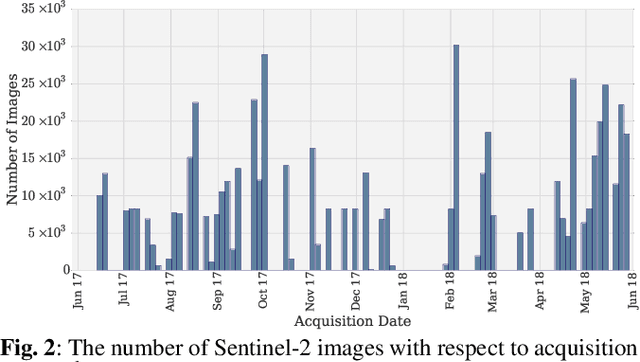
This paper presents a new large-scale multi-label Sentinel-2 benchmark archive, named BigEarthNet. Our archive consists of 590,326 Sentinel-2 image patches, each of which has 10, 20 and 60 meter image bands associated to the pixel sizes of 120x120, 60x60 and 20x20, respectively. Unlike most of the existing archives, each image patch is annotated by multiple land-cover classes (i.e., multi-labels) that are provided from the CORINE Land Cover database of the year 2018 (CLC 2018). The BigEarthNet is 20 times larger than the existing archives in remote sensing (RS) and thus is much more convenient to be used as a training source in the context of deep learning. This paper first addresses the limitations of the existing archives and then describes properties of our archive. Experimental results obtained in the framework of RS image scene classification problems show that a shallow Convolutional Neural Network (CNN) architecture trained on the BigEarthNet provides very high accuracy compared to a state-of-the-art CNN model pre-trained on the ImageNet (which is a very popular large-scale benchmark archive in computer vision). The BigEarthNet opens up promising directions to advance operational RS applications and research in massive Sentinel-2 image archives.
Region homogeneity in the Logarithmic Image Processing framework: application to region growing algorithms
Apr 17, 2019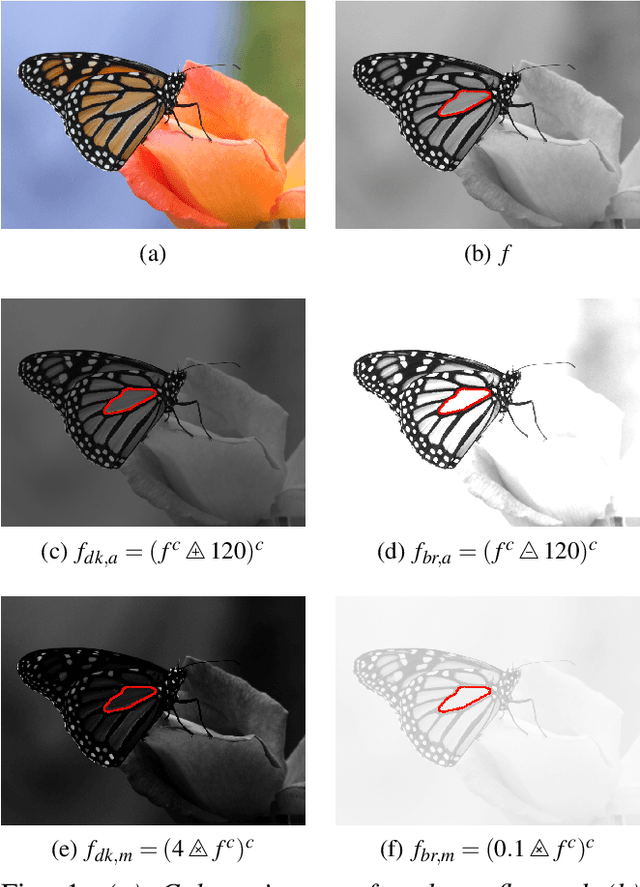
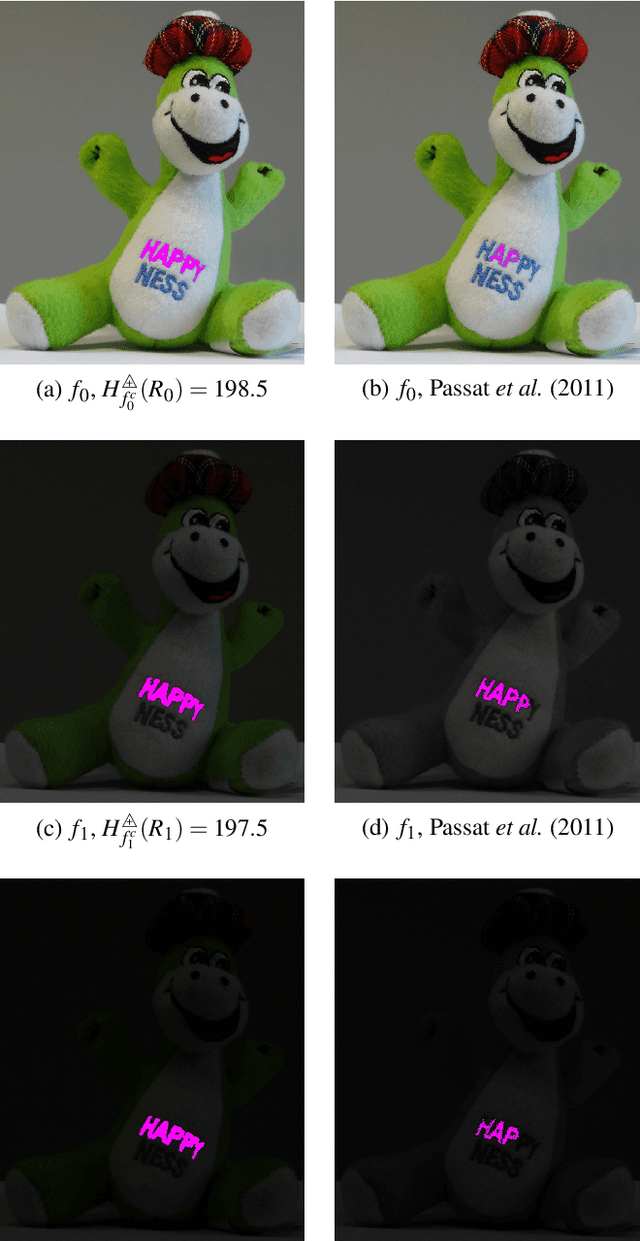
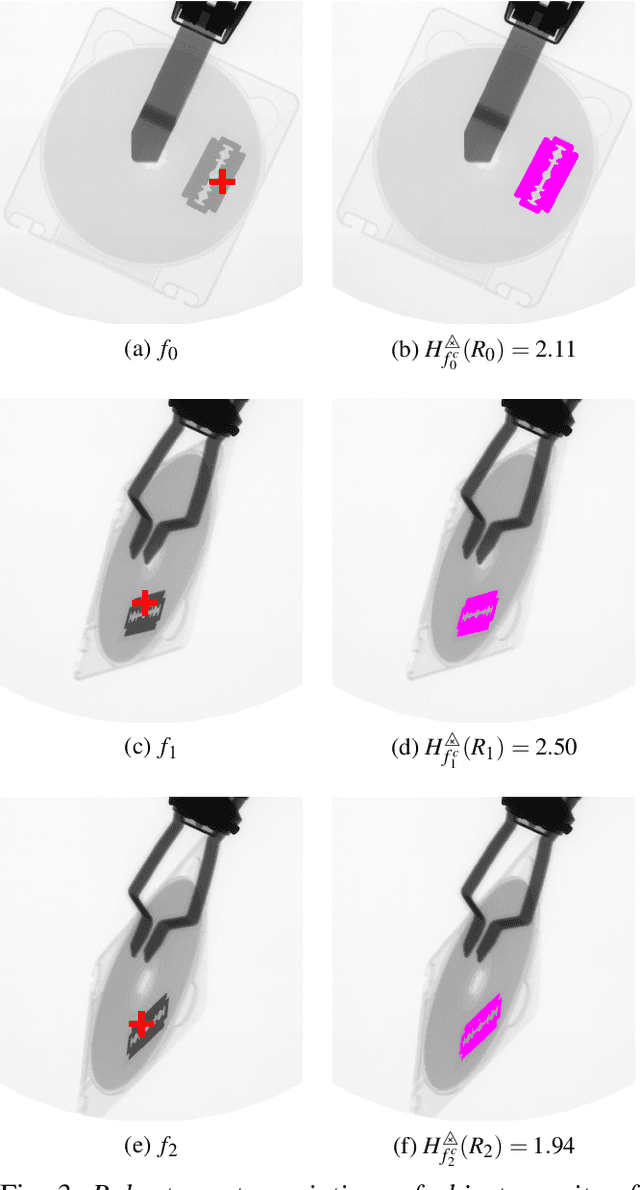
In order to create an image segmentation method robust to lighting changes, two novel homogeneity criteria of an image region were studied. Both were defined using the Logarithmic Image Processing (LIP) framework whose laws model lighting changes. The first criterion estimates the LIP-additive homogeneity and is based on the LIP-additive law. It is theoretically insensitive to lighting changes caused by variations of the camera exposure-time or source intensity. The second, the LIP-multiplicative homogeneity criterion, is based on the LIP-multiplicative law and is insensitive to changes due to variations of the object thickness or opacity. Each criterion is then applied in Revol and Jourlin's (1997) region growing method which is based on the homogeneity of an image region. The region growing method becomes therefore robust to the lighting changes specific to each criterion. Experiments on simulated and on real images presenting lighting variations prove the robustness of the criteria to those variations. Compared to a state-of the art method based on the image component-tree, ours is more robust. These results open the way to numerous applications where the lighting is uncontrolled or partially controlled.
* The original publication is available at www.ias-iss.org
3D Face Mask Presentation Attack Detection Based on Intrinsic Image Analysis
Mar 27, 2019
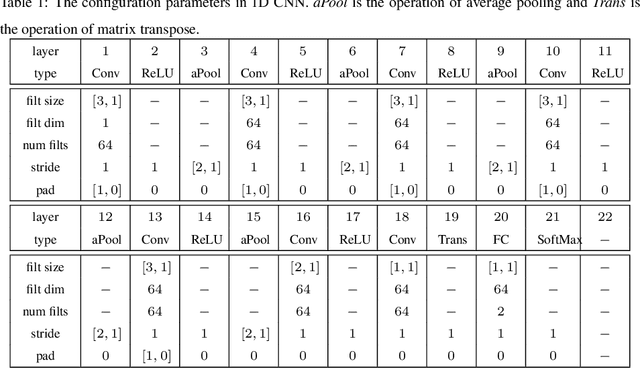
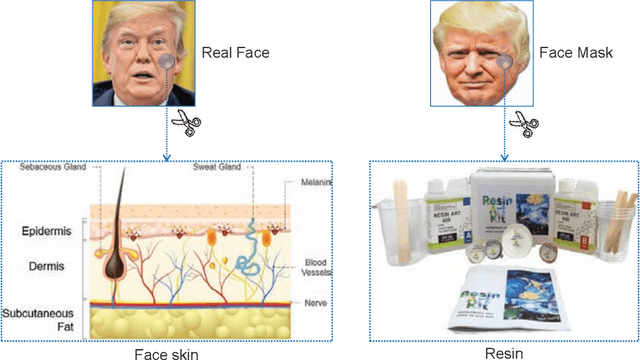
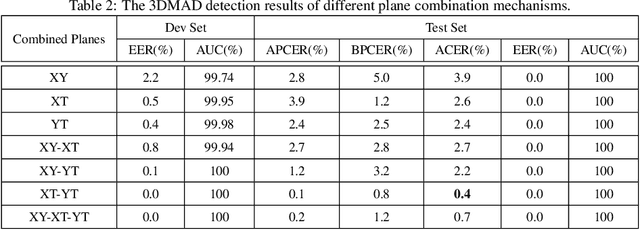
Face presentation attacks have become a major threat to face recognition systems and many countermeasures have been proposed in the past decade. However, most of them are devoted to 2D face presentation attacks, rather than 3D face masks. Unlike the real face, the 3D face mask is usually made of resin materials and has a smooth surface, resulting in reflectance differences. So, we propose a novel detection method for 3D face mask presentation attack by modeling reflectance differences based on intrinsic image analysis. In the proposed method, the face image is first processed with intrinsic image decomposition to compute its reflectance image. Then, the intensity distribution histograms are extracted from three orthogonal planes to represent the intensity differences of reflectance images between the real face and 3D face mask. After that, the 1D convolutional network is further used to capture the information for describing different materials or surfaces react differently to changes in illumination. Extensive experiments on the 3DMAD database demonstrate the effectiveness of our proposed method in distinguishing a face mask from the real one and show that the detection performance outperforms other state-of-the-art methods.
Benchmarking convolutional neural networks for diagnosing Lyme disease from images
Jun 28, 2021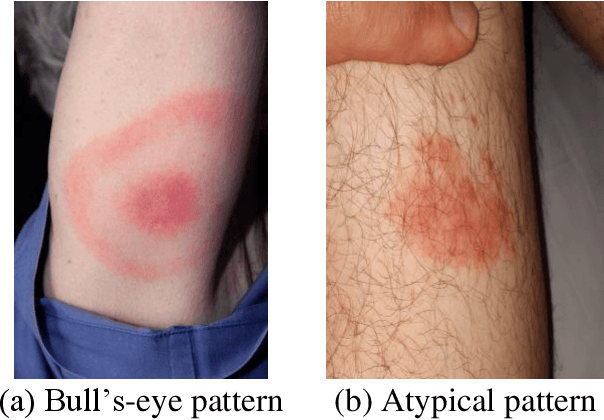
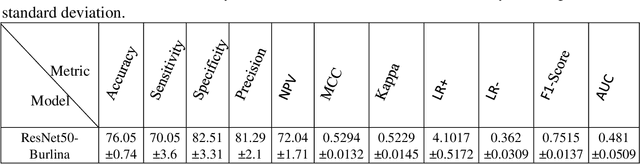
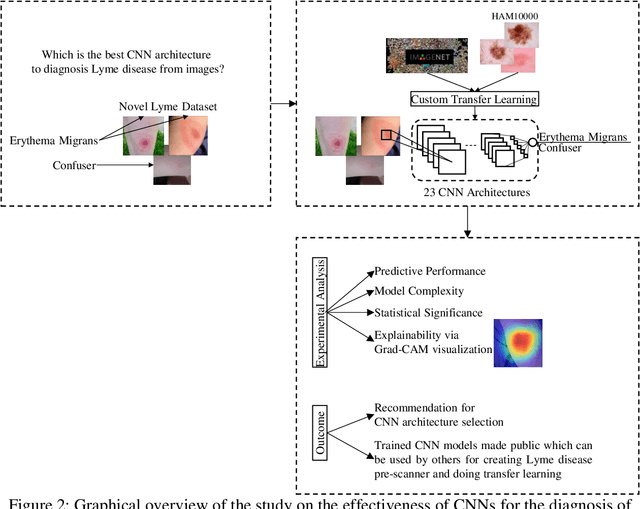
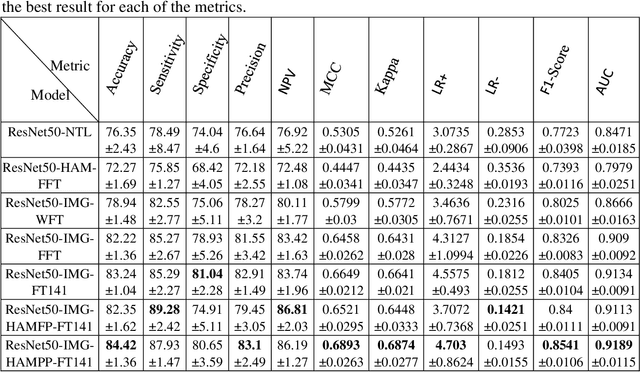
Lyme disease is one of the most common infectious vector-borne diseases in the world. In the early stage, the disease manifests itself in most cases with erythema migrans (EM) skin lesions. Better diagnosis of these early forms would allow improving the prognosis by preventing the transition to a severe late form thanks to appropriate antibiotic therapy. Recent studies show that convolutional neural networks (CNNs) perform very well to identify skin lesions from the image but, there is not much work for Lyme disease prediction from EM lesion images. The main objective of this study is to extensively analyze the effectiveness of CNNs for diagnosing Lyme disease from images and to find out the best CNN architecture for the purpose. There is no publicly available EM image dataset for Lyme disease prediction mainly because of privacy concerns. In this study, we utilized an EM dataset consisting of images collected from Clermont-Ferrand University Hospital Center (CF-CHU) of France and the internet. CF-CHU collected the images from several hospitals in France. This dataset was labeled by expert dermatologists and infectiologists from CF-CHU. First, we benchmarked this dataset for twenty-three well-known CNN architectures in terms of predictive performance metrics, computational complexity metrics, and statistical significance tests. Second, to improve the performance of the CNNs, we used transfer learning from ImageNet pre-trained models as well as pre-trained the CNNs with the skin lesion dataset "Human Against Machine with 10000 training images (HAM1000)". In that process, we searched for the best performing number of layers to unfreeze during transfer learning fine-tuning for each of the CNNs. Third, for model explainability, we utilized Gradient-weighted Class Activation Mapping to visualize the regions of input that are significant to the CNNs for making predictions. Fourth, we provided guidelines for model selection based on predictive performance and computational complexity. Our study confirmed the effectiveness and potential of even some lightweight CNNs to be used for Lyme disease pre-scanner mobile applications. We also made all the trained models publicly available at https://dappem.limos.fr/download.html, which can be used by others for transfer learning and building pre-scanners for Lyme disease.
LFI-CAM: Learning Feature Importance for Better Visual Explanation
May 03, 2021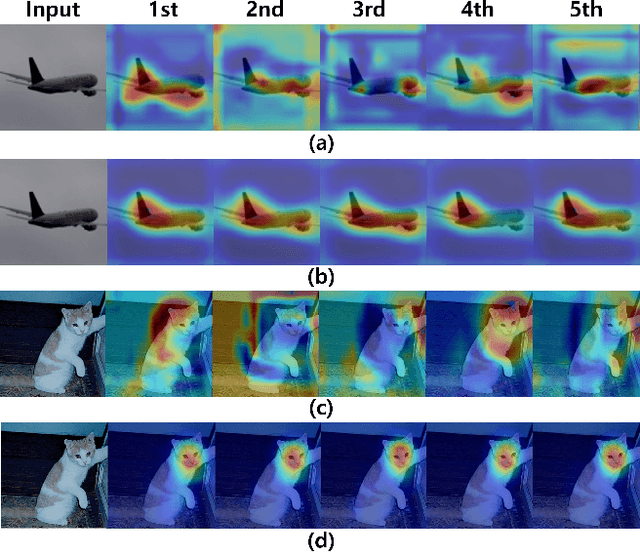
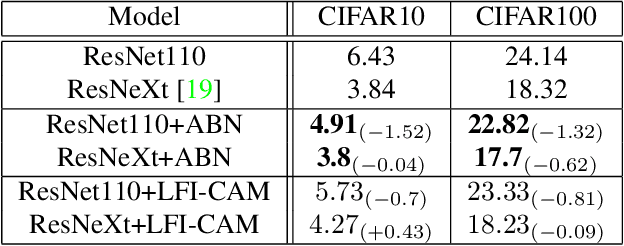
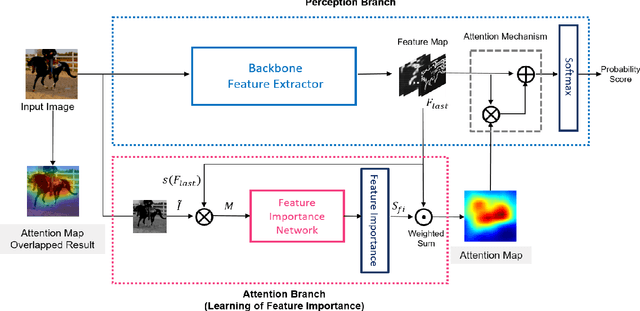
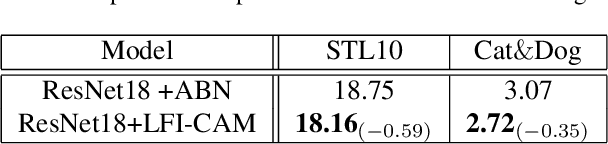
Class Activation Mapping (CAM) is a powerful technique used to understand the decision making of Convolutional Neural Network (CNN) in computer vision. Recently, there have been attempts not only to generate better visual explanations, but also to improve classification performance using visual explanations. However, the previous works still have their own drawbacks. In this paper, we propose a novel architecture, LFI-CAM, which is trainable for image classification and visual explanation in an end-to-end manner. LFI-CAM generates an attention map for visual explanation during forward propagation, at the same time, leverages the attention map to improve the classification performance through the attention mechanism. Our Feature Importance Network (FIN) focuses on learning the feature importance instead of directly learning the attention map to obtain a more reliable and consistent attention map. We confirmed that LFI-CAM model is optimized not only by learning the feature importance but also by enhancing the backbone feature representation to focus more on important features of the input image. Experimental results show that LFI-CAM outperforms the baseline models's accuracy on the classification tasks as well as significantly improves on the previous works in terms of attention map quality and stability over different hyper-parameters.
Self-Supervised Feature Learning of 1D Convolutional Neural Networks with Contrastive Loss for Eating Detection Using an In-Ear Microphone
Aug 03, 2021
The importance of automated and objective monitoring of dietary behavior is becoming increasingly accepted. The advancements in sensor technology along with recent achievements in machine-learning--based signal-processing algorithms have enabled the development of dietary monitoring solutions that yield highly accurate results. A common bottleneck for developing and training machine learning algorithms is obtaining labeled data for training supervised algorithms, and in particular ground truth annotations. Manual ground truth annotation is laborious, cumbersome, can sometimes introduce errors, and is sometimes impossible in free-living data collection. As a result, there is a need to decrease the labeled data required for training. Additionally, unlabeled data, gathered in-the-wild from existing wearables (such as Bluetooth earbuds) can be used to train and fine-tune eating-detection models. In this work, we focus on training a feature extractor for audio signals captured by an in-ear microphone for the task of eating detection in a self-supervised way. We base our approach on the SimCLR method for image classification, proposed by Chen et al. from the domain of computer vision. Results are promising as our self-supervised method achieves similar results to supervised training alternatives, and its overall effectiveness is comparable to current state-of-the-art methods. Code is available at https://github.com/mug-auth/ssl-chewing .
Interpolating Points on a Non-Uniform Grid using a Mixture of Gaussians
Dec 24, 2020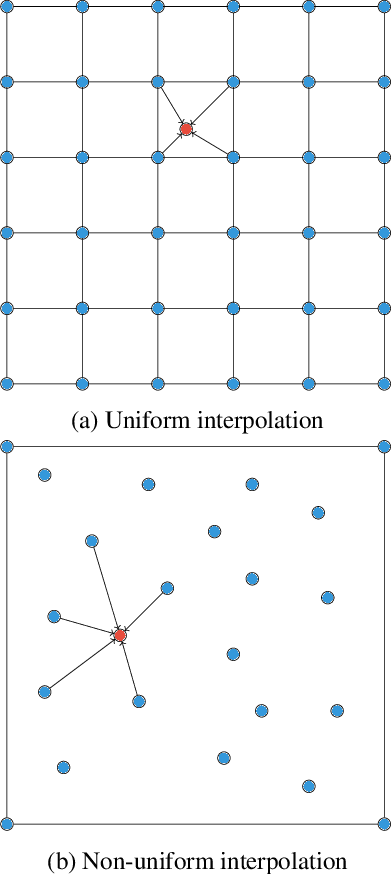
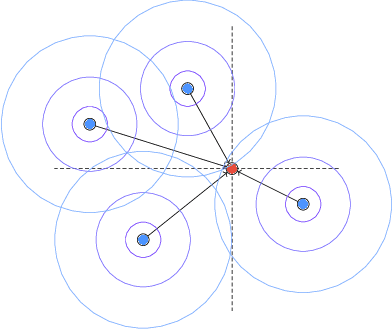
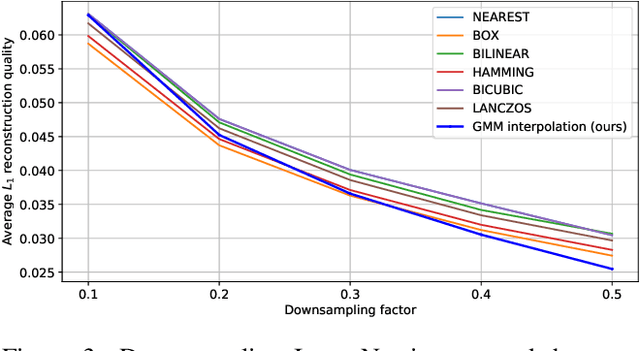
In this work, we propose an approach to perform non-uniform image interpolation based on a Gaussian Mixture Model. Traditional image interpolation methods, like nearest neighbor, bilinear, Hamming, Lanczos, etc. assume that the coordinates you want to interpolate from, are positioned on a uniform grid. However, it is not always the case in practice and we develop an interpolation method that is able to generate an image from arbitrarily positioned pixel values. We do this by representing each known pixel as a 2D normal distribution and considering each output image pixel as a sample from the mixture of all the known ones. Apart from the ability to reconstruct an image from arbitrarily positioned set of pixels, this also allows us to differentiate through the interpolation procedure, which might be helpful for downstream applications. Our optimized CUDA kernel and the source code to reproduce the benchmarks is located at https://github.com/universome/non-uniform-interpolation.
Advantages and Bottlenecks of Quantum Machine Learning for Remote Sensing
Jan 28, 2021
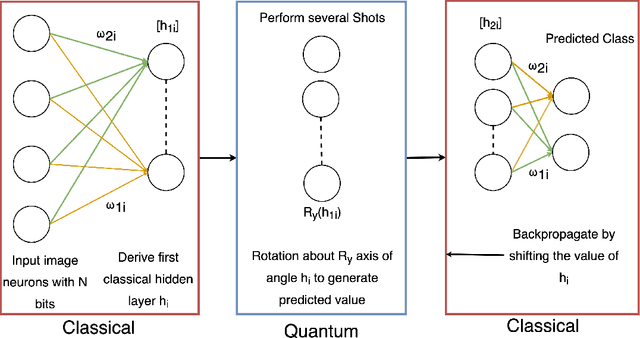

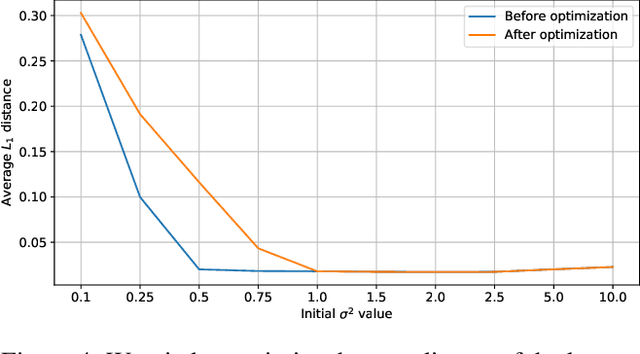
This concept paper aims to provide a brief outline of quantum computers, explore existing methods of quantum image classification techniques, so focusing on remote sensing applications, and discuss the bottlenecks of performing these algorithms on currently available open source platforms. Initial results demonstrate feasibility. Next steps include expanding the size of the quantum hidden layer and increasing the variety of output image options.
A Machine learning approach for rapid disaster response based on multi-modal data. The case of housing & shelter needs
Aug 09, 2021



Along with climate change, more frequent extreme events, such as flooding and tropical cyclones, threaten the livelihoods and wellbeing of poor and vulnerable populations. One of the most immediate needs of people affected by a disaster is finding shelter. While the proliferation of data on disasters is already helping to save lives, identifying damages in buildings, assessing shelter needs, and finding appropriate places to establish emergency shelters or settlements require a wide range of data to be combined rapidly. To address this gap and make a headway in comprehensive assessments, this paper proposes a machine learning workflow that aims to fuse and rapidly analyse multimodal data. This workflow is built around open and online data to ensure scalability and broad accessibility. Based on a database of 19 characteristics for more than 200 disasters worldwide, a fusion approach at the decision level was used. This technique allows the collected multimodal data to share a common semantic space that facilitates the prediction of individual variables. Each fused numerical vector was fed into an unsupervised clustering algorithm called Self-Organizing-Maps (SOM). The trained SOM serves as a predictor for future cases, allowing predicting consequences such as total deaths, total people affected, and total damage, and provides specific recommendations for assessments in the shelter and housing sector. To achieve such prediction, a satellite image from before the disaster and the geographic and demographic conditions are shown to the trained model, which achieved a prediction accuracy of 62 %