 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deformable Groupwise Image Registration using Low-Rank and Sparse Decomposition
Jan 10, 2020


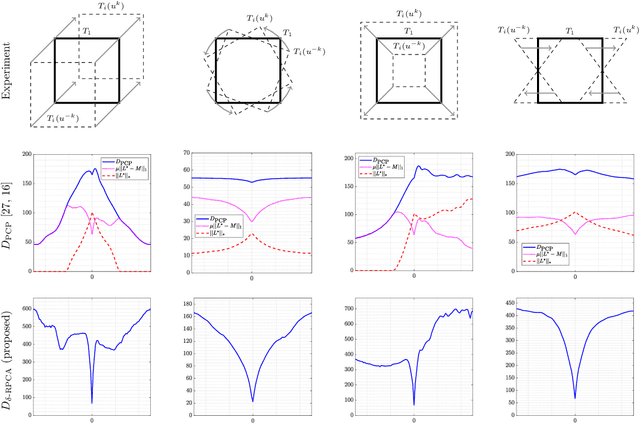
Low-rank and sparse decompositions and robust PCA (RPCA) are highly successful techniques in image processing and have recently found use in groupwise image registration. In this paper, we investigate the drawbacks of the most common RPCA-dissimi\-larity metric in image registration and derive an improved version. In particular, this new metric models low-rank requirements through explicit constraints instead of penalties and thus avoids the pitfalls of the established metric. Equipped with total variation regularization, we present a theoretically justified multilevel scheme based on first-order primal-dual optimization to solve the resulting non-parametric registration problem. As confirmed by numerical experiments, our metric especially lends itself to data involving recurring changes in object appearance and potential sparse perturbations. We numerically compare its peformance to a number of related approaches.
Emotion recognition in talking-face videos using persistent entropy and neural networks
Oct 26, 2021
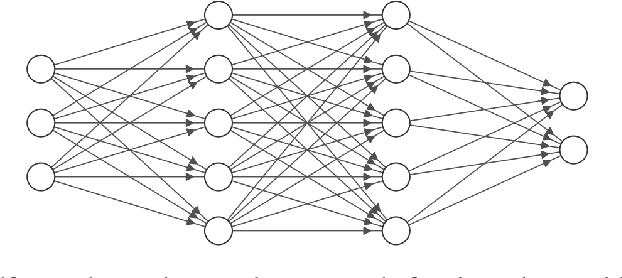
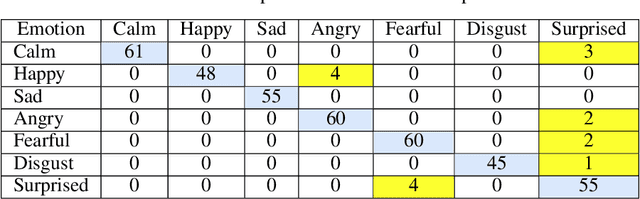
The automatic recognition of a person's emotional state has become a very active research field that involves scientists specialized in different areas such as artificial intelligence, computer vision or psychology, among others. Our main objective in this work is to develop a novel approach, using persistent entropy and neural networks as main tools, to recognise and classify emotions from talking-face videos. Specifically, we combine audio-signal and image-sequence information to compute a topology signature(a 9-dimensional vector) for each video. We prove that small changes in the video produce small changes in the signature. These topological signatures are used to feed a neural network to distinguish between the following emotions: neutral, calm, happy, sad, angry, fearful, disgust, and surprised. The results reached are promising and competitive, beating the performance reached in other state-of-the-art works found in the literature.
Combining chest X-rays and EHR data using machine learning to diagnose acute respiratory failure
Aug 27, 2021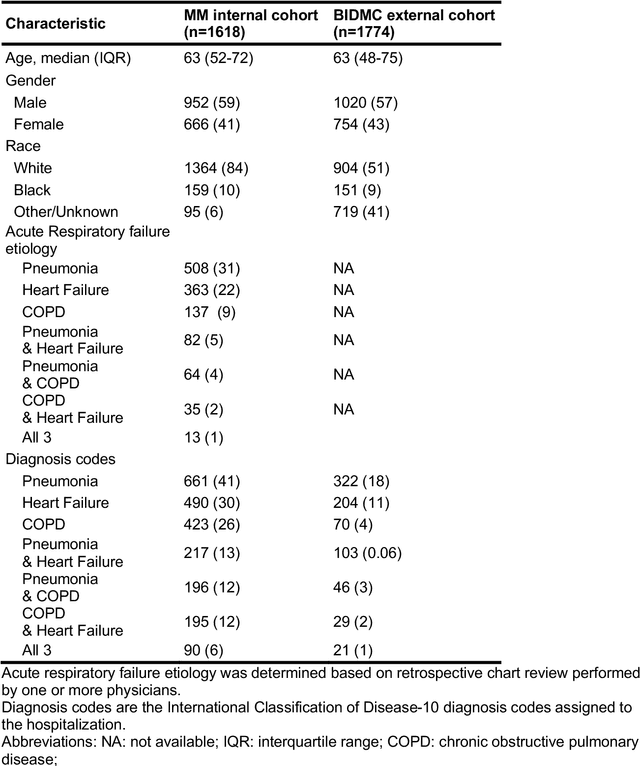
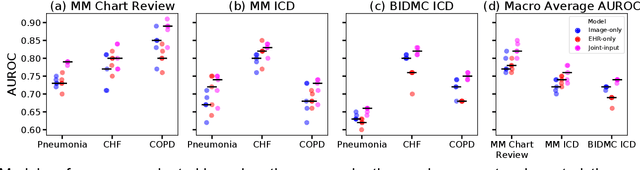
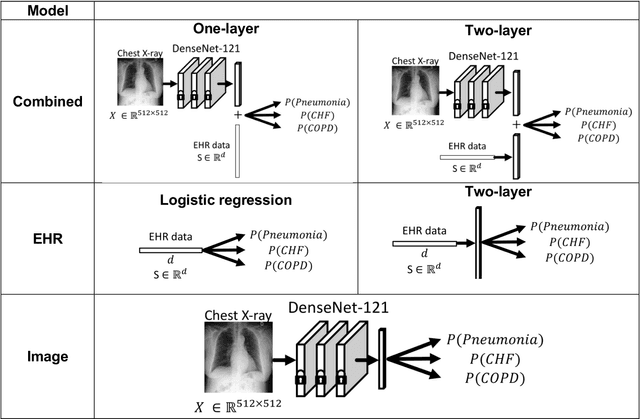
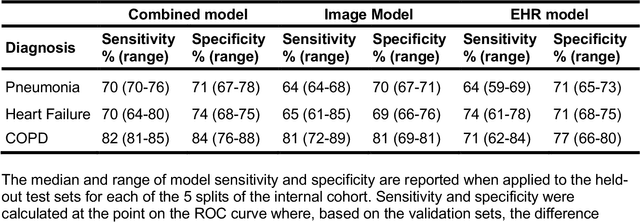
When patients develop acute respiratory failure, accurately identifying the underlying etiology is essential for determining the best treatment, but it can be challenging to differentiate between common diagnoses in clinical practice. Machine learning models could improve medical diagnosis by augmenting clinical decision making and play a role in the diagnostic evaluation of patients with acute respiratory failure. While machine learning models have been developed to identify common findings on chest radiographs (e.g. pneumonia), augmenting these approaches by also analyzing clinically relevant data from the electronic health record (EHR) could aid in the diagnosis of acute respiratory failure. Machine learning models were trained to predict the cause of acute respiratory failure (pneumonia, heart failure, and/or COPD) using chest radiographs and EHR data from patients within an internal cohort using diagnoses based on physician chart review. Models were also tested on patients in an external cohort using discharge diagnosis codes. A model combining chest radiographs and EHR data outperformed models based on each modality alone for pneumonia and COPD. For pneumonia, the combined model AUROC was 0.79 (0.78-0.79), image model AUROC was 0.73 (0.72-0.75), and EHR model AUROC was 0.73 (0.70-0.76); for COPD, combined: 0.89 (0.83-0.91), image: 0.85 (0.77-0.89), and EHR: 0.80 (0.76-0.84); for heart failure, combined: 0.80 (0.77-0.84), image: 0.77 (0.71-0.81), and EHR: 0.80 (0.75-0.82). In the external cohort, performance was consistent for heart failure and COPD, but declined slightly for pneumonia. Overall, machine learning models combing chest radiographs and EHR data can accurately differentiate between common causes of acute respiratory failure. Further work is needed to determine whether these models could aid clinicians in the diagnosis of acute respiratory failure in clinical settings.
On visual self-supervision and its effect on model robustness
Dec 08, 2021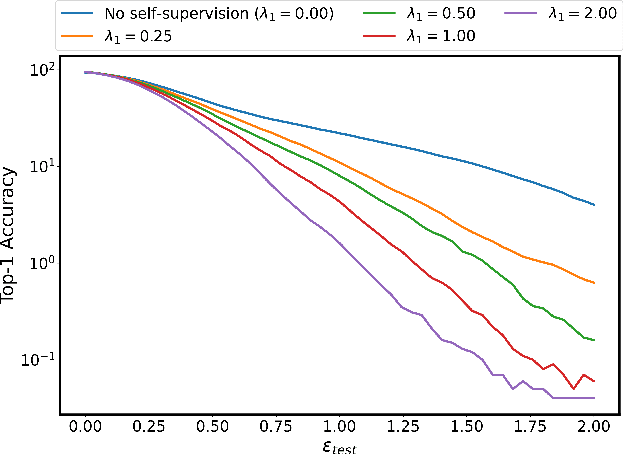

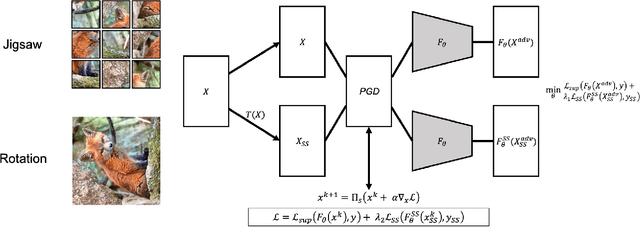

Recent self-supervision methods have found success in learning feature representations that could rival ones from full supervision, and have been shown to be beneficial to the model in several ways: for example improving models robustness and out-of-distribution detection. In our paper, we conduct an empirical study to understand more precisely in what way can self-supervised learning - as a pre-training technique or part of adversarial training - affects model robustness to $l_2$ and $l_{\infty}$ adversarial perturbations and natural image corruptions. Self-supervision can indeed improve model robustness, however it turns out the devil is in the details. If one simply adds self-supervision loss in tandem with adversarial training, then one sees improvement in accuracy of the model when evaluated with adversarial perturbations smaller or comparable to the value of $\epsilon_{train}$ that the robust model is trained with. However, if one observes the accuracy for $\epsilon_{test} \ge \epsilon_{train}$, the model accuracy drops. In fact, the larger the weight of the supervision loss, the larger the drop in performance, i.e. harming the robustness of the model. We identify primary ways in which self-supervision can be added to adversarial training, and observe that using a self-supervised loss to optimize both network parameters and find adversarial examples leads to the strongest improvement in model robustness, as this can be viewed as a form of ensemble adversarial training. Although self-supervised pre-training yields benefits in improving adversarial training as compared to random weight initialization, we observe no benefit in model robustness or accuracy if self-supervision is incorporated into adversarial training.
Multiclass non-Adversarial Image Synthesis, with Application to Classification from Very Small Sample
Dec 01, 2020
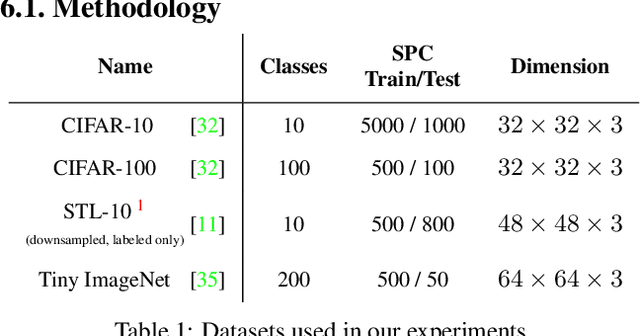
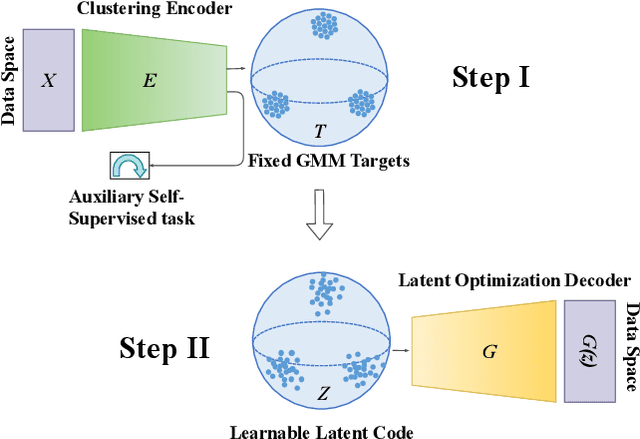
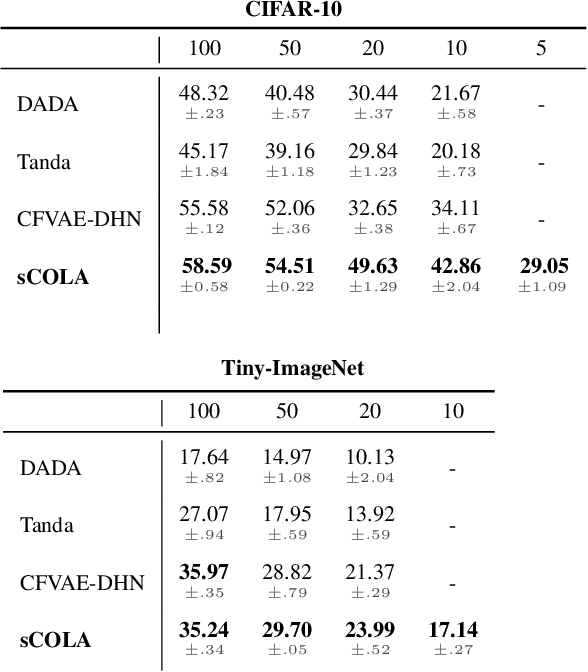
The generation of synthetic images is currently being dominated by Generative Adversarial Networks (GANs). Despite their outstanding success in generating realistic looking images, they still suffer from major drawbacks, including an unstable and highly sensitive training procedure, mode-collapse and mode-mixture, and dependency on large training sets. In this work we present a novel non-adversarial generative method - Clustered Optimization of LAtent space (COLA), which overcomes some of the limitations of GANs, and outperforms GANs when training data is scarce. In the full data regime, our method is capable of generating diverse multi-class images with no supervision, surpassing previous non-adversarial methods in terms of image quality and diversity. In the small-data regime, where only a small sample of labeled images is available for training with no access to additional unlabeled data, our results surpass state-of-the-art GAN models trained on the same amount of data. Finally, when utilizing our model to augment small datasets, we surpass the state-of-the-art performance in small-sample classification tasks on challenging datasets, including CIFAR-10, CIFAR-100, STL-10 and Tiny-ImageNet. A theoretical analysis supporting the essence of the method is presented.
Towers of Babel: Combining Images, Language, and 3D Geometry for Learning Multimodal Vision
Aug 12, 2021



The abundance and richness of Internet photos of landmarks and cities has led to significant progress in 3D vision over the past two decades, including automated 3D reconstructions of the world's landmarks from tourist photos. However, a major source of information available for these 3D-augmented collections---namely language, e.g., from image captions---has been virtually untapped. In this work, we present WikiScenes, a new, large-scale dataset of landmark photo collections that contains descriptive text in the form of captions and hierarchical category names. WikiScenes forms a new testbed for multimodal reasoning involving images, text, and 3D geometry. We demonstrate the utility of WikiScenes for learning semantic concepts over images and 3D models. Our weakly-supervised framework connects images, 3D structure, and semantics---utilizing the strong constraints provided by 3D geometry---to associate semantic concepts to image pixels and 3D points.
Cross-modal Attention for MRI and Ultrasound Volume Registration
Jul 12, 2021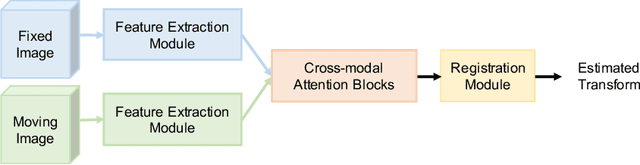
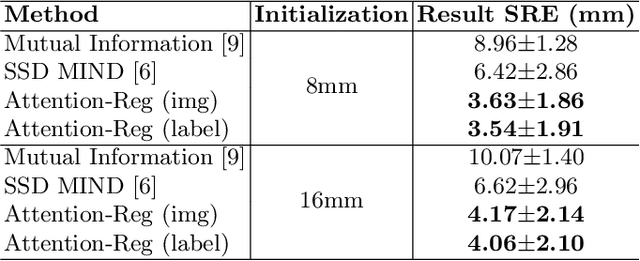
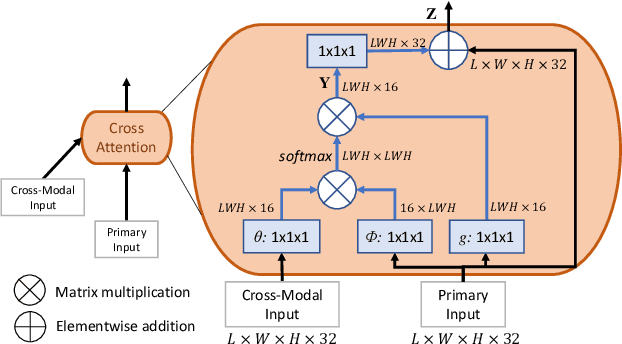
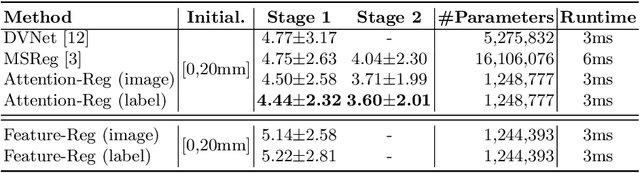
Prostate cancer biopsy benefits from accurate fusion of transrectal ultrasound (TRUS) and magnetic resonance (MR) images. In the past few years, convolutional neural networks (CNNs) have been proved powerful in extracting image features crucial for image registration. However, challenging applications and recent advances in computer vision suggest that CNNs are quite limited in its ability to understand spatial correspondence between features, a task in which the self-attention mechanism excels. This paper aims to develop a self-attention mechanism specifically for cross-modal image registration. Our proposed cross-modal attention block effectively maps each of the features in one volume to all features in the corresponding volume. Our experimental results demonstrate that a CNN network designed with the cross-modal attention block embedded outperforms an advanced CNN network 10 times of its size. We also incorporated visualization techniques to improve the interpretability of our network. The source code of our work is available at https://github.com/DIAL-RPI/Attention-Reg .
Which Design Decisions in AI-enabled Mobile Applications Contribute to Greener AI?
Sep 28, 2021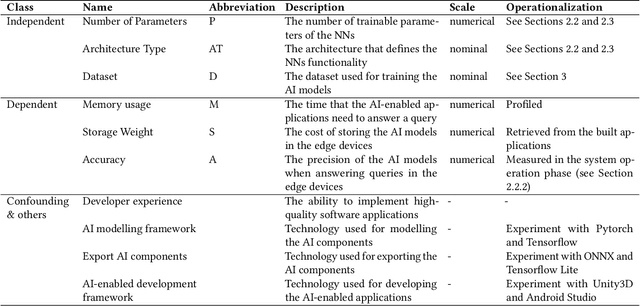
Background: The construction, evolution and usage of complex artificial intelligence (AI) models demand expensive computational resources. While currently available high-performance computing environments support well this complexity, the deployment of AI models in mobile devices, which is an increasing trend, is challenging. Mobile applications consist of environments with low computational resources and hence imply limitations in the design decisions during the AI-enabled software engineering lifecycle that balance the trade-off between the accuracy and the complexity of the mobile applications. Objective: Our objective is to systematically assess the trade-off between accuracy and complexity when deploying complex AI models (e.g. neural networks) to mobile devices, which have an implicit resource limitation. We aim to cover (i) the impact of the design decisions on the achievement of high-accuracy and low resource-consumption implementations; and (ii) the validation of profiling tools for systematically promoting greener AI. Method: This confirmatory registered report consists of a plan to conduct an empirical study to quantify the implications of the design decisions on AI-enabled applications performance and to report experiences of the end-to-end AI-enabled software engineering lifecycle. Concretely, we will implement both image-based and language-based neural networks in mobile applications to solve multiple image classification and text classification problems on different benchmark datasets. Overall, we plan to model the accuracy and complexity of AI-enabled applications in operation with respect to their design decisions and will provide tools for allowing practitioners to gain consciousness of the quantitative relationship between the design decisions and the green characteristics of study.
Offense Detection in Dravidian Languages using Code-Mixing Index based Focal Loss
Nov 12, 2021

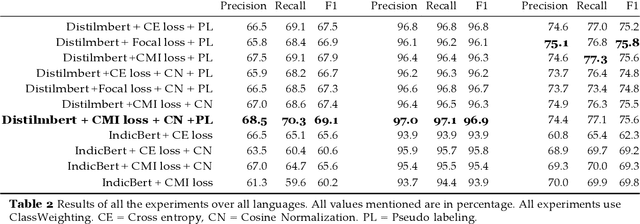
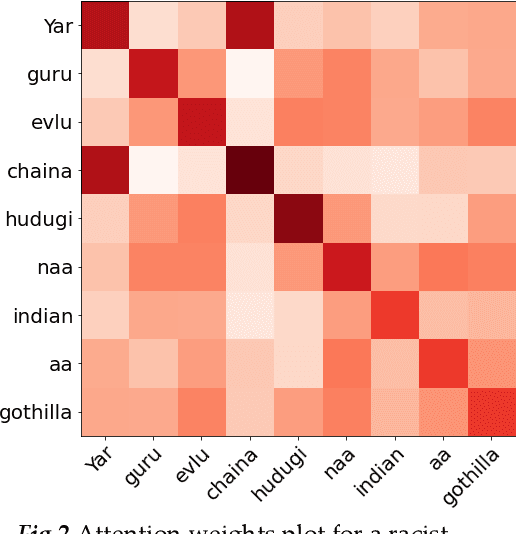
Over the past decade, we have seen exponential growth in online content fueled by social media platforms. Data generation of this scale comes with the caveat of insurmountable offensive content in it. The complexity of identifying offensive content is exacerbated by the usage of multiple modalities (image, language, etc.), code mixed language and more. Moreover, even if we carefully sample and annotate offensive content, there will always exist significant class imbalance in offensive vs non offensive content. In this paper, we introduce a novel Code-Mixing Index (CMI) based focal loss which circumvents two challenges (1) code mixing in languages (2) class imbalance problem for Dravidian language offense detection. We also replace the conventional dot product-based classifier with the cosine-based classifier which results in a boost in performance. Further, we use multilingual models that help transfer characteristics learnt across languages to work effectively with low resourced languages. It is also important to note that our model handles instances of mixed script (say usage of Latin and Dravidian - Tamil script) as well. Our model can handle offensive language detection in a low-resource, class imbalanced, multilingual and code mixed setting.
A context based deep learning approach for unbalanced medical image segmentation
Jan 08, 2020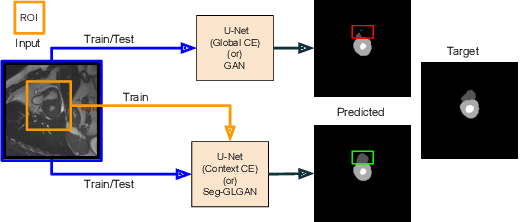
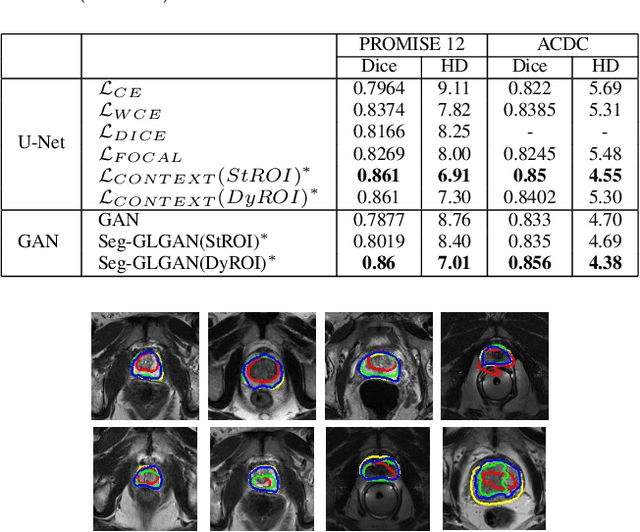
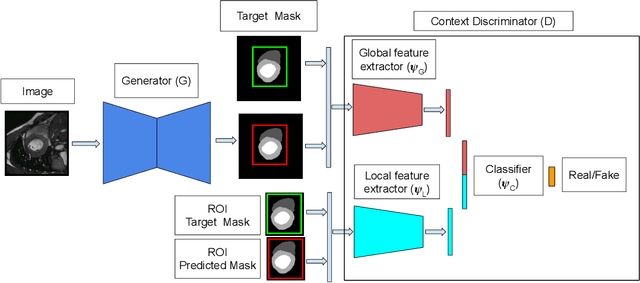

Automated medical image segmentation is an important step in many medical procedures. Recently, deep learning networks have been widely used for various medical image segmentation tasks, with U-Net and generative adversarial nets (GANs) being some of the commonly used ones. Foreground-background class imbalance is a common occurrence in medical images, and U-Net has difficulty in handling class imbalance because of its cross entropy (CE) objective function. Similarly, GAN also suffers from class imbalance because the discriminator looks at the entire image to classify it as real or fake. Since the discriminator is essentially a deep learning classifier, it is incapable of correctly identifying minor changes in small structures. To address these issues, we propose a novel context based CE loss function for U-Net, and a novel architecture Seg-GLGAN. The context based CE is a linear combination of CE obtained over the entire image and its region of interest (ROI). In Seg-GLGAN, we introduce a novel context discriminator to which the entire image and its ROI are fed as input, thus enforcing local context. We conduct extensive experiments using two challenging unbalanced datasets: PROMISE12 and ACDC. We observe that segmentation results obtained from our methods give better segmentation metrics as compared to various baseline methods.