 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Retrieval using Multi-scale CNN Features Pooling
Apr 24, 2020
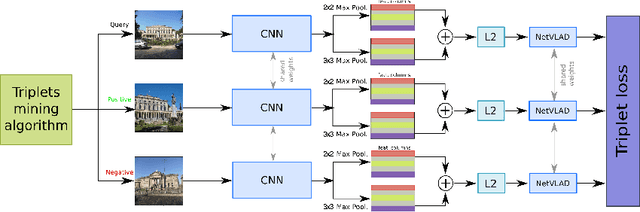
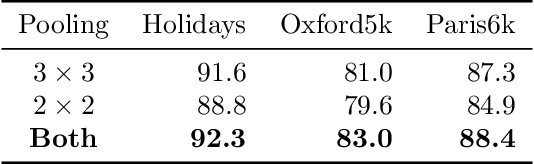
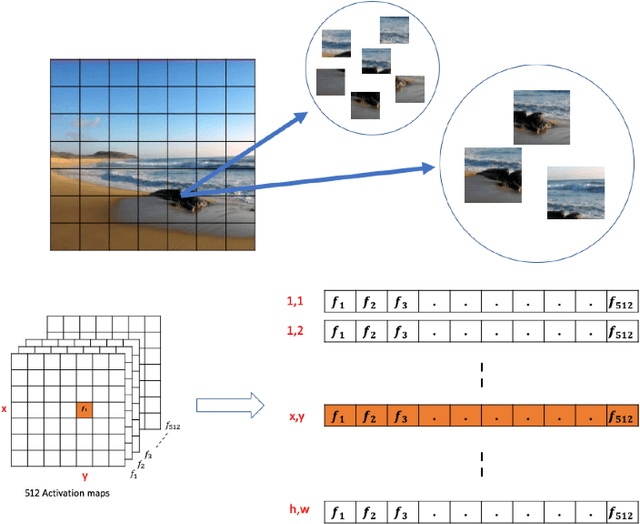
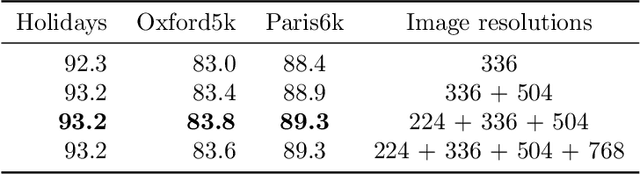
In this paper, we address the problem of image retrieval by learning images representation based on the activations of a Convolutional Neural Network. We present an end-to-end trainable network architecture that exploits a novel multi-scale local pooling based on NetVLAD and a triplet mining procedure based on samples difficulty to obtain an effective image representation. Extensive experiments show that our approach is able to reach state-of-the-art results on three standard datasets.
Approximate Decomposable Submodular Function Minimization for Cardinality-Based Components
Oct 28, 2021



Minimizing a sum of simple submodular functions of limited support is a special case of general submodular function minimization that has seen numerous applications in machine learning. We develop fast techniques for instances where components in the sum are cardinality-based, meaning they depend only on the size of the input set. This variant is one of the most widely applied in practice, encompassing, e.g., common energy functions arising in image segmentation and recent generalized hypergraph cut functions. We develop the first approximation algorithms for this problem, where the approximations can be quickly computed via reduction to a sparse graph cut problem, with graph sparsity controlled by the desired approximation factor. Our method relies on a new connection between sparse graph reduction techniques and piecewise linear approximations to concave functions. Our sparse reduction technique leads to significant improvements in theoretical runtimes, as well as substantial practical gains in problems ranging from benchmark image segmentation tasks to hypergraph clustering problems.
Discrete Simulation Optimization for Tuning Machine Learning Method Hyperparameters
Jan 16, 2022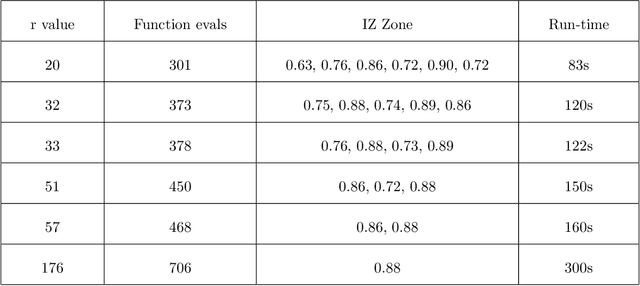
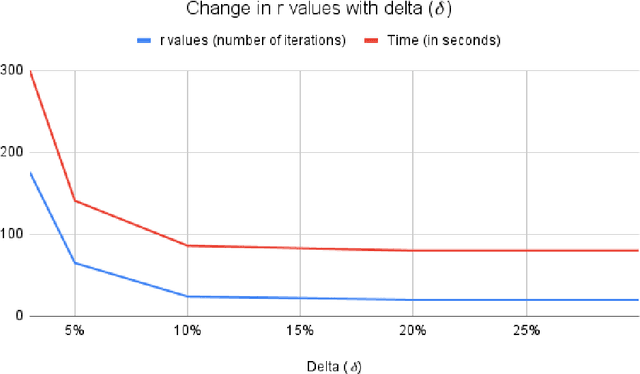
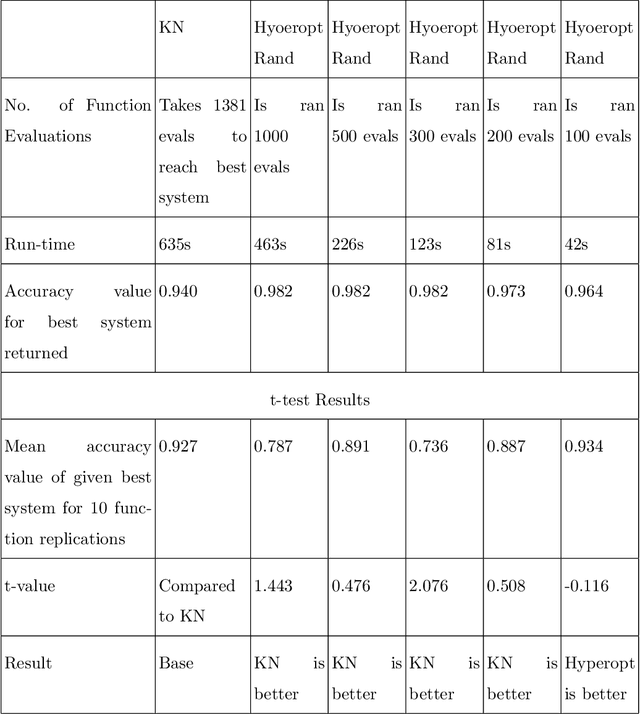
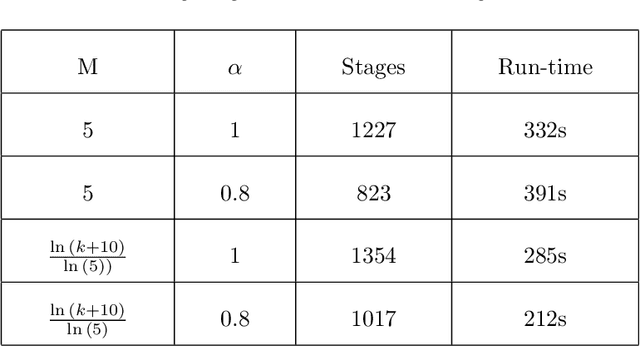
Machine learning methods are being increasingly used in most technical areas such as image recognition, product recommendation, financial analysis, medical diagnosis, and predictive maintenance. The key question that arises is: how do we control the learning process according to our requirement for the problem? Hyperparameter tuning is used to choose the optimal set of hyperparameters for controlling the learning process of a model. Selecting the appropriate hyperparameters directly impacts the performance measure a model. We have used simulation optimization using discrete search methods like ranking and selection (R&S) methods such as the KN method and stochastic ruler method and its variations for hyperparameter optimization and also developed the theoretical basis for applying common R&S methods. The KN method finds the best possible system with statistical guarantee and stochastic ruler method asymptotically converges to the optimal solution and is also computationally very efficient. We also benchmarked our results with state of art hyperparameter optimization libraries such as $hyperopt$ and $mango$ and found KN and stochastic ruler to be performing consistently better than $hyperopt~rand$ and stochastic ruler to be equally efficient in comparison with $hyperopt~tpe$ in most cases, even when our computational implementations are not yet optimized in comparison to professional packages.
Neural Image Inpainting Guided with Descriptive Text
Apr 22, 2020
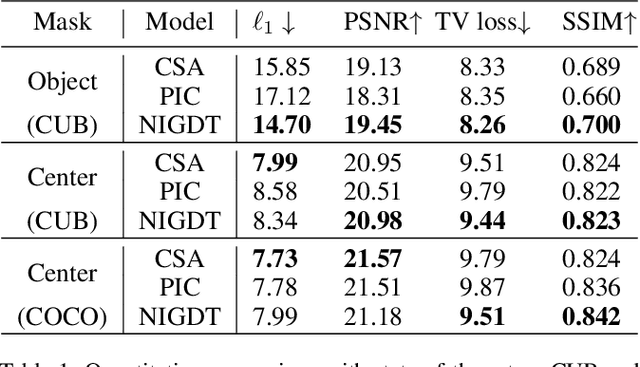
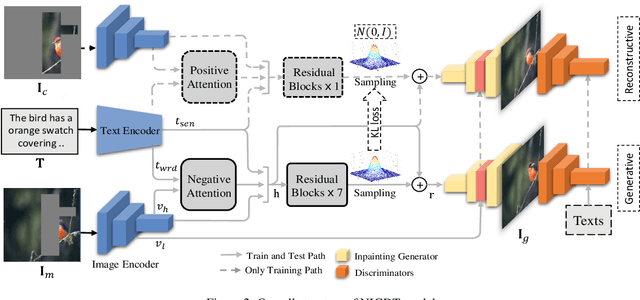
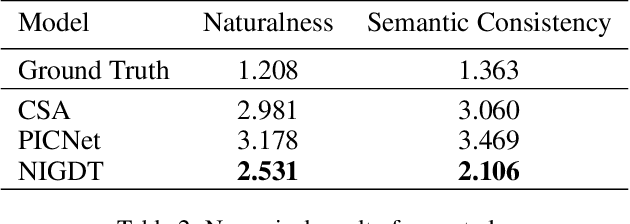
Neural image inpainting has achieved promising performance in generating semantically plausible content. Most of the recent works mainly focus on inpainting images depending on vision information, while neglecting the semantic information implied in human languages. To acquire more semantically accurate inpainting images, this paper proposes a novel inpainting model named \textit{N}eural \textit{I}mage Inpainting \textit{G}uided with \textit{D}escriptive \textit{T}ext (NIGDT). First, a dual multi-modal attention mechanism is designed to extract the explicit semantic information about corrupted regions. The mechanism is trained to combine the descriptive text and two complementary images through reciprocal attention maps. Second, an image-text matching loss is designed to enforce the model output following the descriptive text. Its goal is to maximize the semantic similarity of the generated image and the text. Finally, experiments are conducted on two open datasets with captions. Experimental results show that the proposed NIGDT model outperforms all compared models on both quantitative and qualitative comparison. The results also demonstrate that the proposed model can generate images consistent with the guidance text, which provides a flexible way for user-guided inpainting. Our systems and code will be released soon.
GmFace: A Mathematical Model for Face Image Representation Using Multi-Gaussian
Aug 03, 2020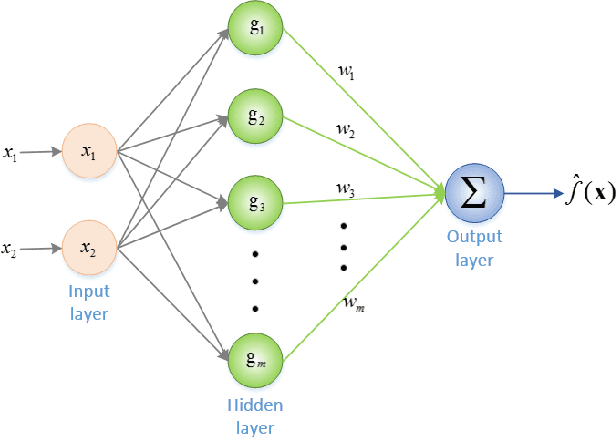
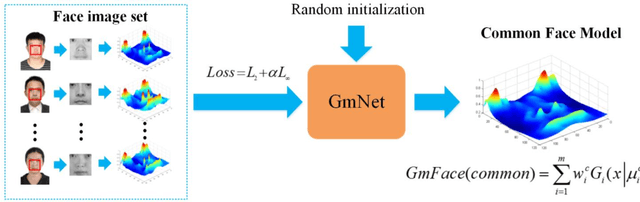
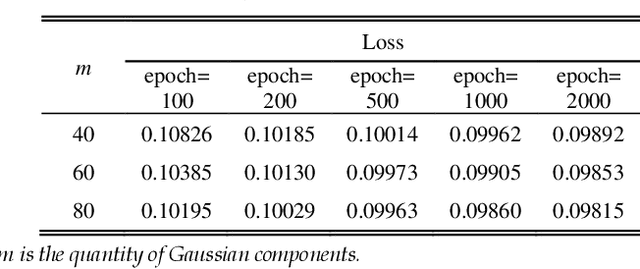
Establishing mathematical models is a ubiquitous and effective method to understand the objective world. Due to complex physiological structures and dynamic behaviors, mathematical representation of the human face is an especially challenging task. A mathematical model for face image representation called GmFace is proposed in the form of a multi-Gaussian function in this paper. The model utilizes the advantages of two-dimensional Gaussian function which provides a symmetric bell surface with a shape that can be controlled by parameters. The GmNet is then designed using Gaussian functions as neurons, with parameters that correspond to each of the parameters of GmFace in order to transform the problem of GmFace parameter solving into a network optimization problem of GmNet. The face modeling process can be described by the following steps: (1) GmNet initialization; (2) feeding GmNet with face image(s); (3) training GmNet until convergence; (4) drawing out the parameters of GmNet (as the same as GmFace); (5) recording the face model GmFace. Furthermore, using GmFace, several face image transformation operations can be realized mathematically through simple parameter computation.
Towards Measuring Bias in Image Classification
Jul 01, 2021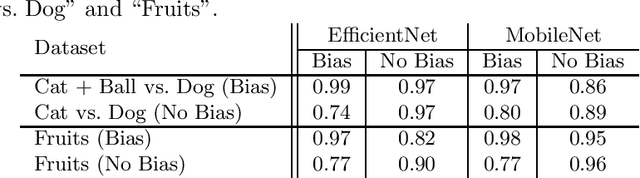
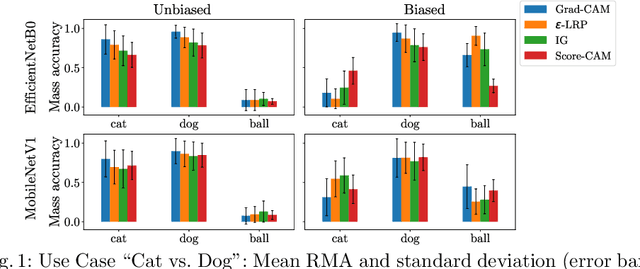
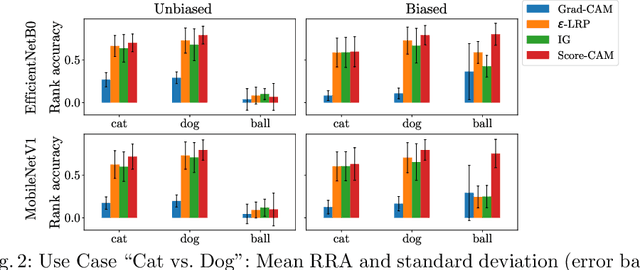

Convolutional Neural Networks (CNN) have become de fact state-of-the-art for the main computer vision tasks. However, due to the complex underlying structure their decisions are hard to understand which limits their use in some context of the industrial world. A common and hard to detect challenge in machine learning (ML) tasks is data bias. In this work, we present a systematic approach to uncover data bias by means of attribution maps. For this purpose, first an artificial dataset with a known bias is created and used to train intentionally biased CNNs. The networks' decisions are then inspected using attribution maps. Finally, meaningful metrics are used to measure the attribution maps' representativeness with respect to the known bias. The proposed study shows that some attribution map techniques highlight the presence of bias in the data better than others and metrics can support the identification of bias.
Transformers Can Do Bayesian Inference
Jan 25, 2022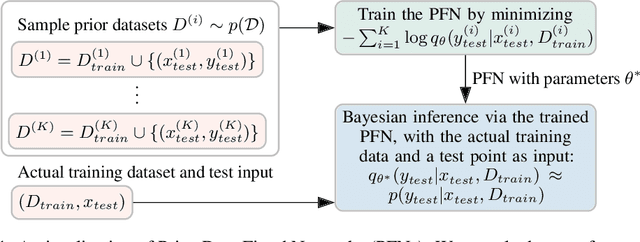
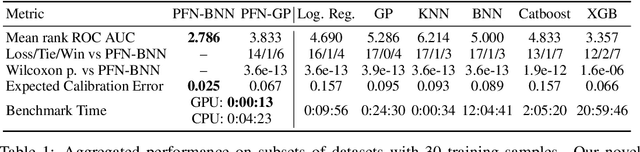
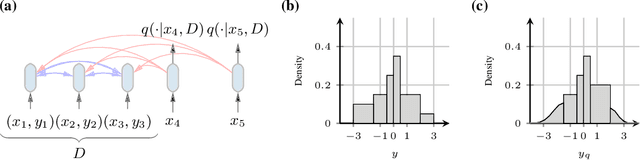

Currently, it is hard to reap the benefits of deep learning for Bayesian methods, which allow the explicit specification of prior knowledge and accurately capture model uncertainty. We present Prior-Data Fitted Networks (PFNs). PFNs leverage large-scale machine learning techniques to approximate a large set of posteriors. The only requirement for PFNs to work is the ability to sample from a prior distribution over supervised learning tasks (or functions). Our method restates the objective of posterior approximation as a supervised classification problem with a set-valued input: it repeatedly draws a task (or function) from the prior, draws a set of data points and their labels from it, masks one of the labels and learns to make probabilistic predictions for it based on the set-valued input of the rest of the data points. Presented with a set of samples from a new supervised learning task as input, PFNs make probabilistic predictions for arbitrary other data points in a single forward propagation, having learned to approximate Bayesian inference. We demonstrate that PFNs can near-perfectly mimic Gaussian processes and also enable efficient Bayesian inference for intractable problems, with over 200-fold speedups in multiple setups compared to current methods. We obtain strong results in very diverse areas such as Gaussian process regression, Bayesian neural networks, classification for small tabular data sets, and few-shot image classification, demonstrating the generality of PFNs. Code and trained PFNs are released at https://github.com/automl/TransformersCanDoBayesianInference.
Across-scale Process Similarity based Interpolation for Image Super-Resolution
Mar 20, 2020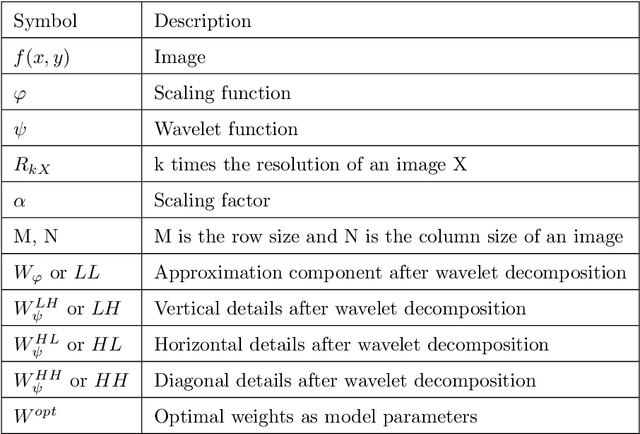
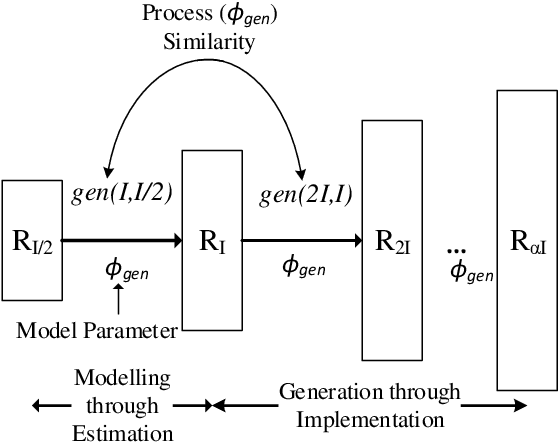
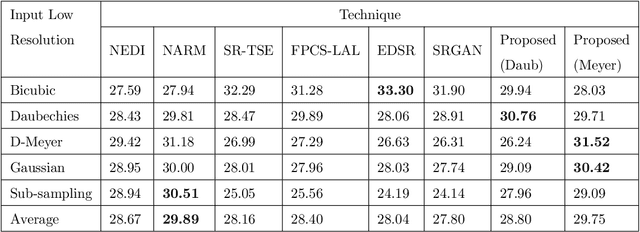

A pivotal step in image super-resolution techniques is interpolation, which aims at generating high resolution images without introducing artifacts such as blurring and ringing. In this paper, we propose a technique that performs interpolation through an infusion of high frequency signal components computed by exploiting `process similarity'. By `process similarity', we refer to the resemblance between a decomposition of the image at a resolution to the decomposition of the image at another resolution. In our approach, the decompositions generating image details and approximations are obtained through the discrete wavelet (DWT) and stationary wavelet (SWT) transforms. The complementary nature of DWT and SWT is leveraged to get the structural relation between the input image and its low resolution approximation. The structural relation is represented by optimal model parameters obtained through particle swarm optimization (PSO). Owing to process similarity, these parameters are used to generate the high resolution output image from the input image. The proposed approach is compared with six existing techniques qualitatively and in terms of PSNR, SSIM, and FSIM measures, along with computation time (CPU time). It is found that our approach is the fastest in terms of CPU time and produces comparable results.
Unsupervised Image-to-Image Translation with Self-Attention Networks
Jan 24, 2019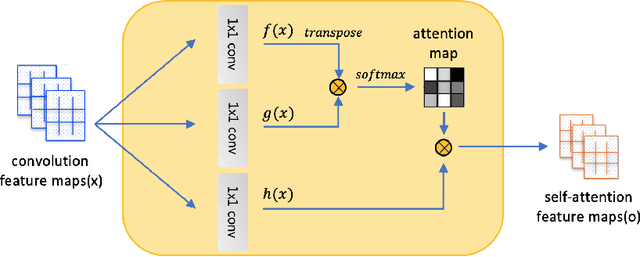
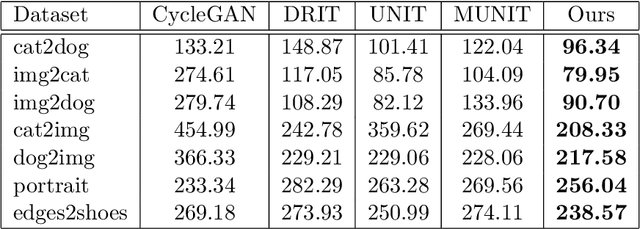
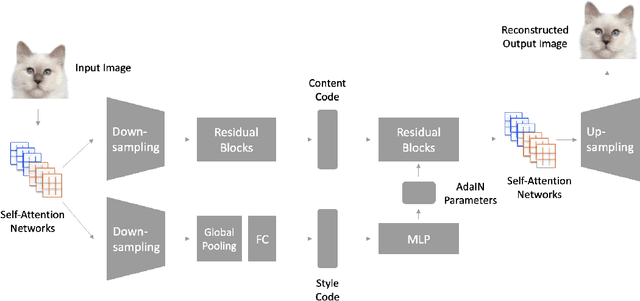

Unsupervised image translation aims to learn the transformation from a source domain to another target domain given unpaired training data. Several state-of-the-art works have yielded impressive results in the GANs-based unsupervised image-to-image translation. It fails to capture strong geometric or structural change between domains or is unsatisfactory for complex scenes, compared to texture change tasks such as style transfer. Recently, SAGAN (Han Zhang, 2018) showed that the self-attention network produces better results than the convolution-based GAN. However, the effectiveness of the self-attention network in unsupervised image-to-image translation tasks have not been verified. In this paper, we propose an unsupervised image-to-image translation with self-attention networks, in which long range dependency helps to not only capture strong geometric change but also generate details using cues from all feature locations. In experiments, we qualitatively and quantitatively show superiority of the proposed method compared to existing state-of-the-art unsupervised image-to-image translation task.
Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
Dec 10, 2021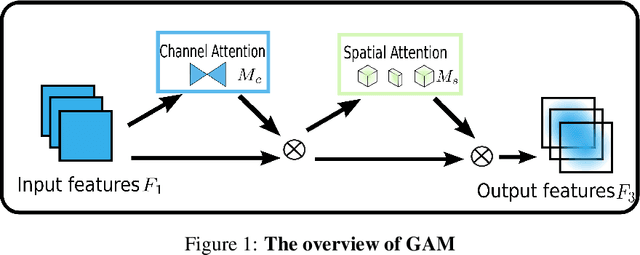
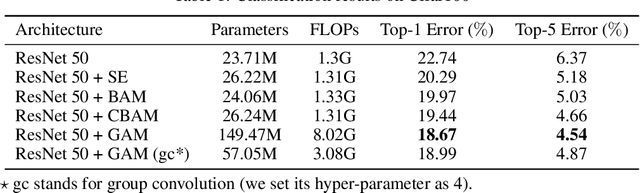
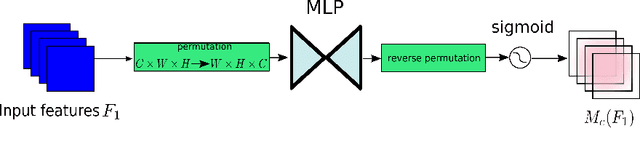
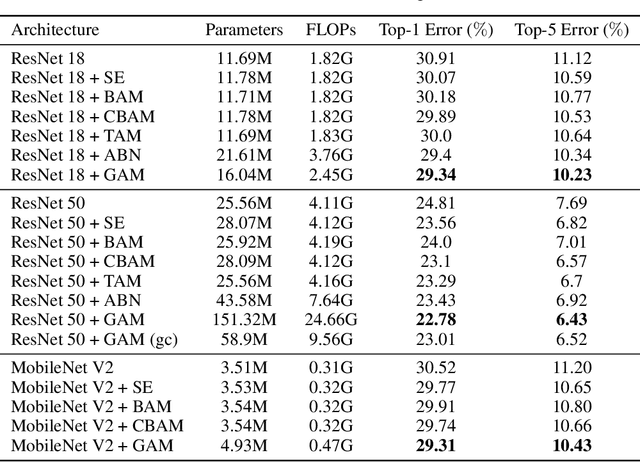
A variety of attention mechanisms have been studied to improve the performance of various computer vision tasks. However, the prior methods overlooked the significance of retaining the information on both channel and spatial aspects to enhance the cross-dimension interactions. Therefore, we propose a global attention mechanism that boosts the performance of deep neural networks by reducing information reduction and magnifying the global interactive representations. We introduce 3D-permutation with multilayer-perceptron for channel attention alongside a convolutional spatial attention submodule. The evaluation of the proposed mechanism for the image classification task on CIFAR-100 and ImageNet-1K indicates that our method stably outperforms several recent attention mechanisms with both ResNet and lightweight MobileNet.