 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep learning for classification of noisy QR codes
Jul 20, 2023
We wish to define the limits of a classical classification model based on deep learning when applied to abstract images, which do not represent visually identifiable objects.QR codes (Quick Response codes) fall into this category of abstract images: one bit corresponding to one encoded character, QR codes were not designed to be decoded manually. To understand the limitations of a deep learning-based model for abstract image classification, we train an image classification model on QR codes generated from information obtained when reading a health pass. We compare a classification model with a classical (deterministic) decoding method in the presence of noise. This study allows us to conclude that a model based on deep learning can be relevant for the understanding of abstract images.
Contextual Affinity Distillation for Image Anomaly Detection
Jul 06, 2023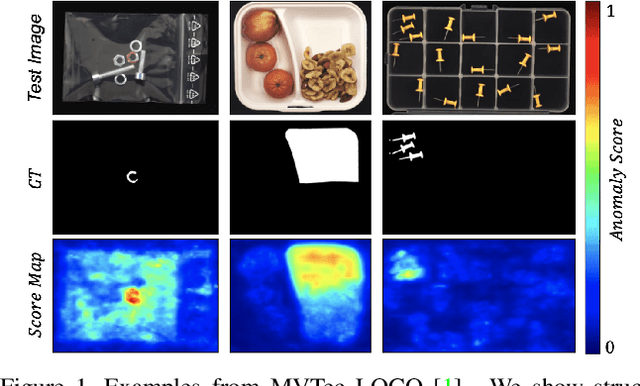
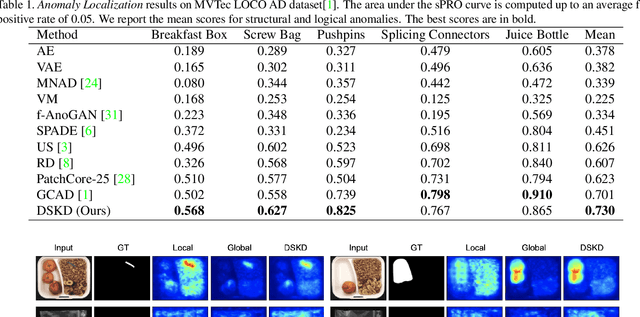
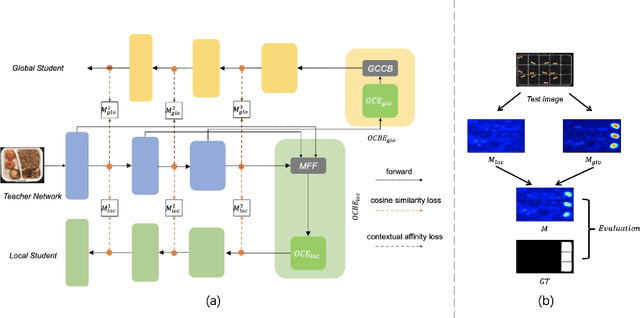
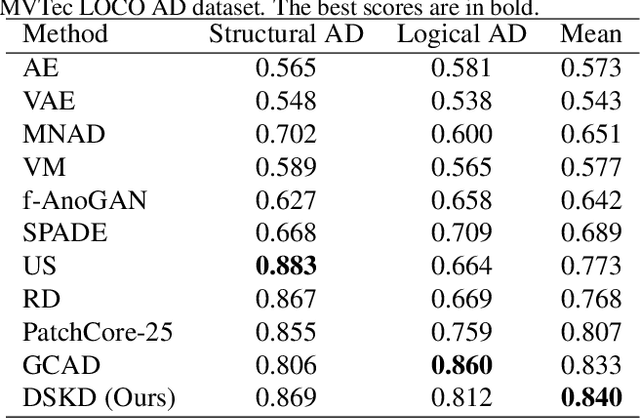
Previous works on unsupervised industrial anomaly detection mainly focus on local structural anomalies such as cracks and color contamination. While achieving significantly high detection performance on this kind of anomaly, they are faced with logical anomalies that violate the long-range dependencies such as a normal object placed in the wrong position. In this paper, based on previous knowledge distillation works, we propose to use two students (local and global) to better mimic the teacher's behavior. The local student, which is used in previous studies mainly focuses on structural anomaly detection while the global student pays attention to logical anomalies. To further encourage the global student's learning to capture long-range dependencies, we design the global context condensing block (GCCB) and propose a contextual affinity loss for the student training and anomaly scoring. Experimental results show the proposed method doesn't need cumbersome training techniques and achieves a new state-of-the-art performance on the MVTec LOCO AD dataset.
A Critical Look at the Current Usage of Foundation Model for Dense Recognition Task
Aug 01, 2023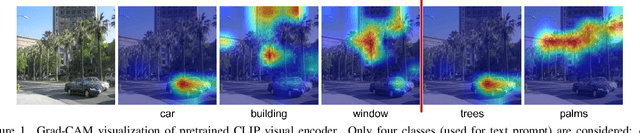
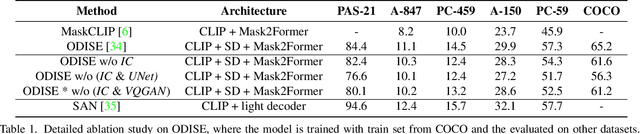


In recent years large model trained on huge amount of cross-modality data, which is usually be termed as foundation model, achieves conspicuous accomplishment in many fields, such as image recognition and generation. Though achieving great success in their original application case, it is still unclear whether those foundation models can be applied to other different downstream tasks. In this paper, we conduct a short survey on the current methods for discriminative dense recognition tasks, which are built on the pretrained foundation model. And we also provide some preliminary experimental analysis of an existing open-vocabulary segmentation method based on Stable Diffusion, which indicates the current way of deploying diffusion model for segmentation is not optimal. This aims to provide insights for future research on adopting foundation model for downstream task.
Patch-wise Auto-Encoder for Visual Anomaly Detection
Aug 01, 2023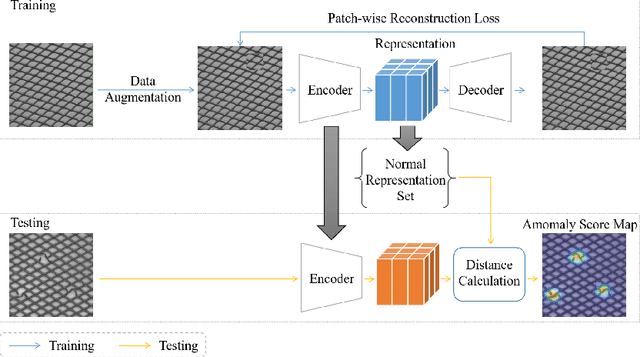
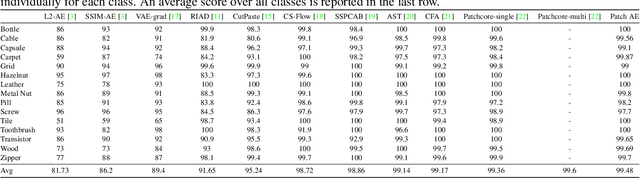
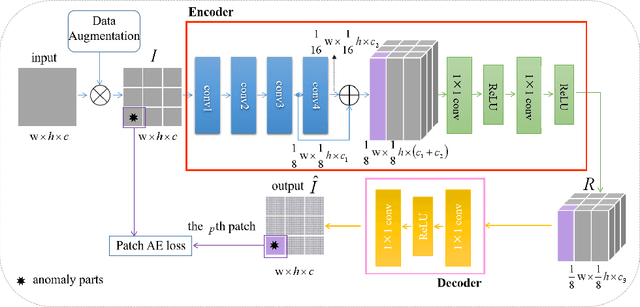
Anomaly detection without priors of the anomalies is challenging. In the field of unsupervised anomaly detection, traditional auto-encoder (AE) tends to fail based on the assumption that by training only on normal images, the model will not be able to reconstruct abnormal images correctly. On the contrary, we propose a novel patch-wise auto-encoder (Patch AE) framework, which aims at enhancing the reconstruction ability of AE to anomalies instead of weakening it. Each patch of image is reconstructed by corresponding spatially distributed feature vector of the learned feature representation, i.e., patch-wise reconstruction, which ensures anomaly-sensitivity of AE. Our method is simple and efficient. It advances the state-of-the-art performances on Mvtec AD benchmark, which proves the effectiveness of our model. It shows great potential in practical industrial application scenarios.
The Algonauts Project 2023 Challenge: UARK-UAlbany Team Solution
Aug 01, 2023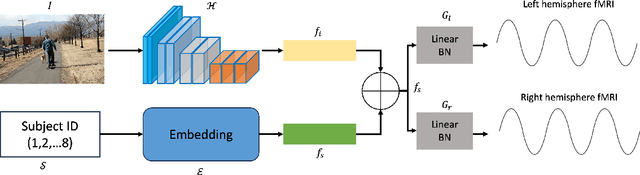

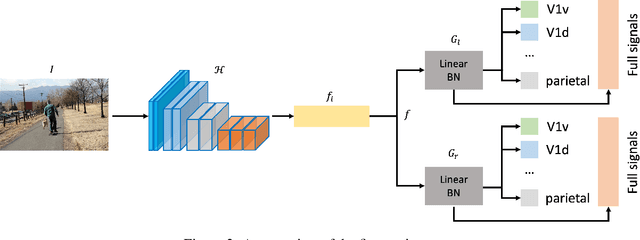
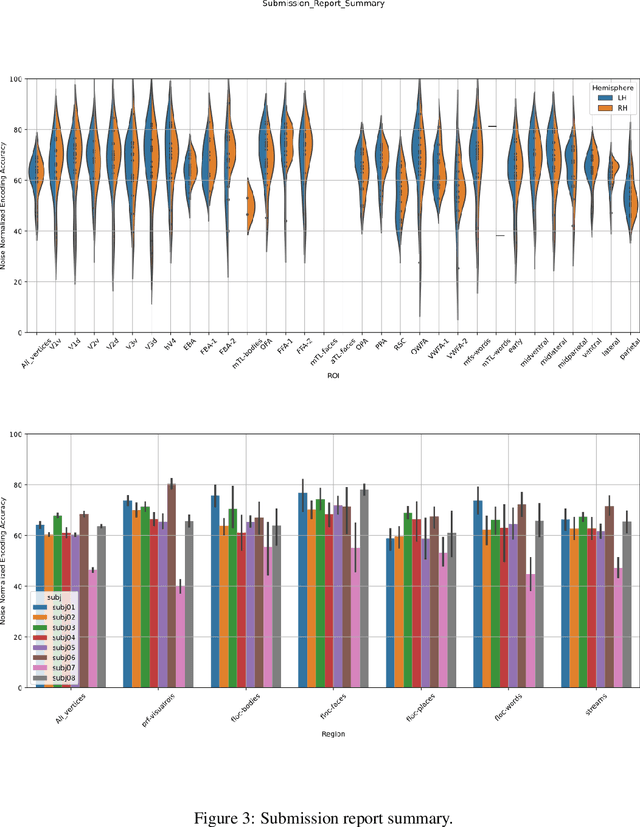
This work presents our solutions to the Algonauts Project 2023 Challenge. The primary objective of the challenge revolves around employing computational models to anticipate brain responses captured during participants' observation of intricate natural visual scenes. The goal is to predict brain responses across the entire visual brain, as it is the region where the most reliable responses to images have been observed. We constructed an image-based brain encoder through a two-step training process to tackle this challenge. Initially, we created a pretrained encoder using data from all subjects. Next, we proceeded to fine-tune individual subjects. Each step employed different training strategies, such as different loss functions and objectives, to introduce diversity. Ultimately, our solution constitutes an ensemble of multiple unique encoders. The code is available at https://github.com/uark-cviu/Algonauts2023
Detecting Cloud Presence in Satellite Images Using the RGB-based CLIP Vision-Language Model
Aug 01, 2023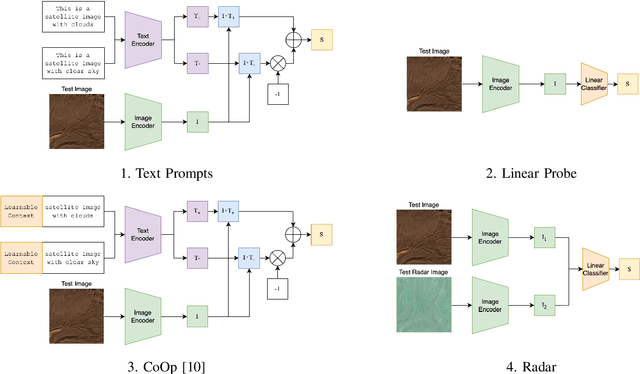
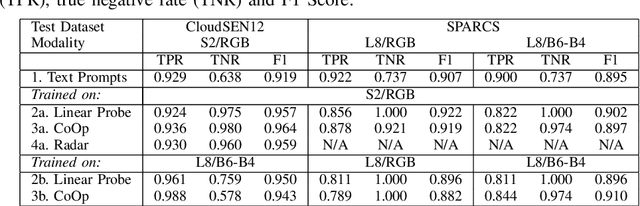
This work explores capabilities of the pre-trained CLIP vision-language model to identify satellite images affected by clouds. Several approaches to using the model to perform cloud presence detection are proposed and evaluated, including a purely zero-shot operation with text prompts and several fine-tuning approaches. Furthermore, the transferability of the methods across different datasets and sensor types (Sentinel-2 and Landsat-8) is tested. The results that CLIP can achieve non-trivial performance on the cloud presence detection task with apparent capability to generalise across sensing modalities and sensing bands. It is also found that a low-cost fine-tuning stage leads to a strong increase in true negative rate. The results demonstrate that the representations learned by the CLIP model can be useful for satellite image processing tasks involving clouds.
IIITD-20K: Dense captioning for Text-Image ReID
May 08, 2023

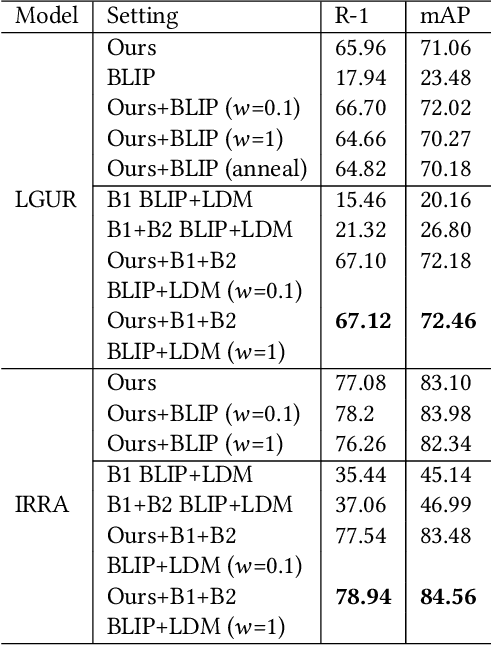
Text-to-Image (T2I) ReID has attracted a lot of attention in the recent past. CUHK-PEDES, RSTPReid and ICFG-PEDES are the three available benchmarks to evaluate T2I ReID methods. RSTPReid and ICFG-PEDES comprise of identities from MSMT17 but due to limited number of unique persons, the diversity is limited. On the other hand, CUHK-PEDES comprises of 13,003 identities but has relatively shorter text description on average. Further, these datasets are captured in a restricted environment with limited number of cameras. In order to further diversify the identities and provide dense captions, we propose a novel dataset called IIITD-20K. IIITD-20K comprises of 20,000 unique identities captured in the wild and provides a rich dataset for text-to-image ReID. With a minimum of 26 words for a description, each image is densely captioned. We further synthetically generate images and fine-grained captions using Stable-diffusion and BLIP models trained on our dataset. We perform elaborate experiments using state-of-art text-to-image ReID models and vision-language pre-trained models and present a comprehensive analysis of the dataset. Our experiments also reveal that synthetically generated data leads to a substantial performance improvement in both same dataset as well as cross dataset settings. Our dataset is available at https://bit.ly/3pkA3Rj.
Optimization-Based Improvement of Face Image Quality Assessment Techniques
May 24, 2023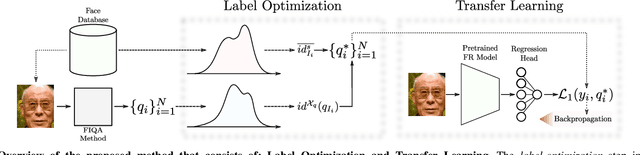
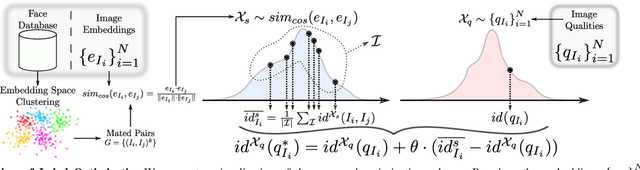

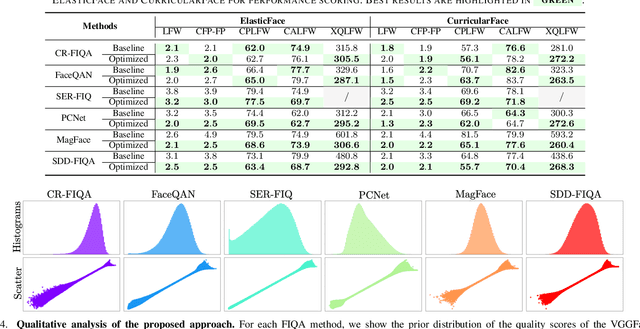
Contemporary face recognition (FR) models achieve near-ideal recognition performance in constrained settings, yet do not fully translate the performance to unconstrained (realworld) scenarios. To help improve the performance and stability of FR systems in such unconstrained settings, face image quality assessment (FIQA) techniques try to infer sample-quality information from the input face images that can aid with the recognition process. While existing FIQA techniques are able to efficiently capture the differences between high and low quality images, they typically cannot fully distinguish between images of similar quality, leading to lower performance in many scenarios. To address this issue, we present in this paper a supervised quality-label optimization approach, aimed at improving the performance of existing FIQA techniques. The developed optimization procedure infuses additional information (computed with a selected FR model) into the initial quality scores generated with a given FIQA technique to produce better estimates of the "actual" image quality. We evaluate the proposed approach in comprehensive experiments with six state-of-the-art FIQA approaches (CR-FIQA, FaceQAN, SER-FIQ, PCNet, MagFace, SDD-FIQA) on five commonly used benchmarks (LFW, CFPFP, CPLFW, CALFW, XQLFW) using three targeted FR models (ArcFace, ElasticFace, CurricularFace) with highly encouraging results.
Automated Artifact Detection in Ultra-widefield Fundus Photography of Patients with Sickle Cell Disease
Jul 11, 2023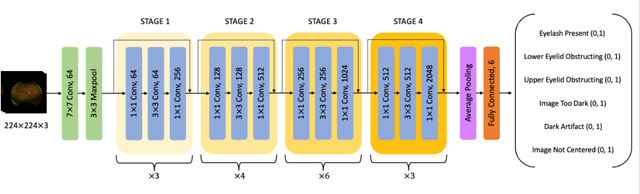
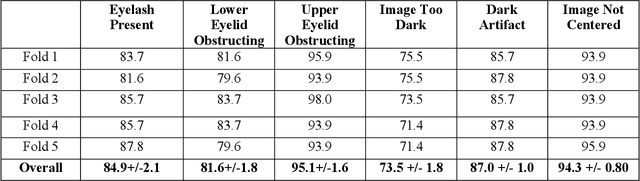
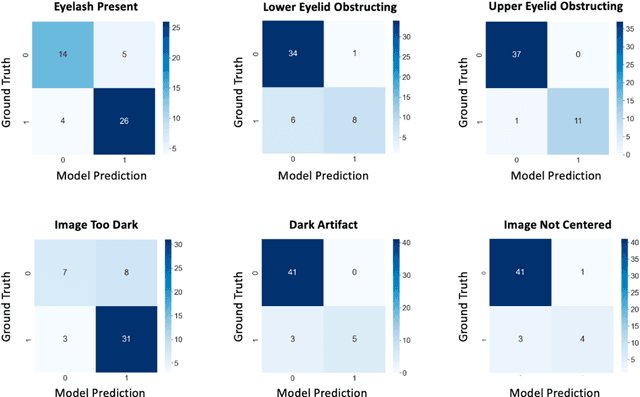
Importance: Ultra-widefield fundus photography (UWF-FP) has shown utility in sickle cell retinopathy screening; however, image artifact may diminish quality and gradeability of images. Objective: To create an automated algorithm for UWF-FP artifact classification. Design: A neural network based automated artifact detection algorithm was designed to identify commonly encountered UWF-FP artifacts in a cross section of patient UWF-FP. A pre-trained ResNet-50 neural network was trained on a subset of the images and the classification accuracy, sensitivity, and specificity were quantified on the hold out test set. Setting: The study is based on patients from a tertiary care hospital site. Participants: There were 243 UWF-FP acquired from patients with sickle cell disease (SCD), and artifact labelling in the following categories was performed: Eyelash Present, Lower Eyelid Obstructing, Upper Eyelid Obstructing, Image Too Dark, Dark Artifact, and Image Not Centered. Results: Overall, the accuracy for each class was Eyelash Present at 83.7%, Lower Eyelid Obstructing at 83.7%, Upper Eyelid Obstructing at 98.0%, Image Too Dark at 77.6%, Dark Artifact at 93.9%, and Image Not Centered at 91.8%. Conclusions and Relevance: This automated algorithm shows promise in identifying common imaging artifacts on a subset of Optos UWF-FP in SCD patients. Further refinement is ongoing with the goal of improving efficiency of tele-retinal screening in sickle cell retinopathy (SCR) by providing a photographer real-time feedback as to the types of artifacts present, and the need for image re-acquisition. This algorithm also may have potential future applicability in other retinal diseases by improving quality and efficiency of image acquisition of UWF-FP.
Expert load matters: operating networks at high accuracy and low manual effort
Aug 09, 2023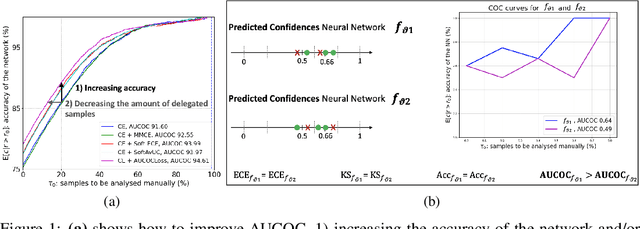
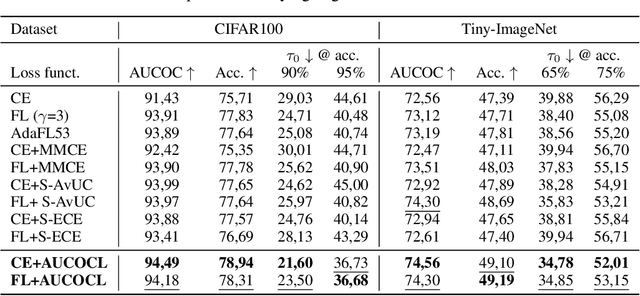
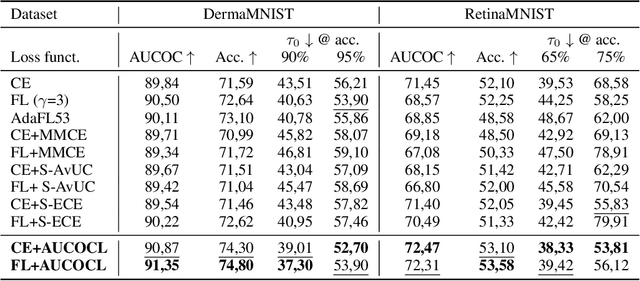
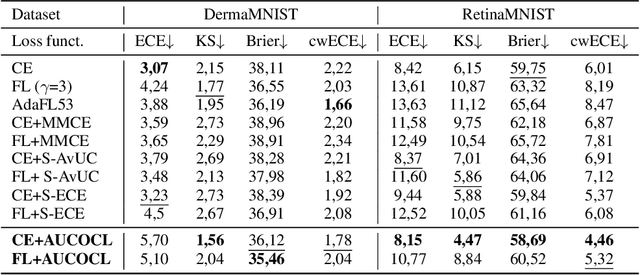
In human-AI collaboration systems for critical applications, in order to ensure minimal error, users should set an operating point based on model confidence to determine when the decision should be delegated to human experts. Samples for which model confidence is lower than the operating point would be manually analysed by experts to avoid mistakes. Such systems can become truly useful only if they consider two aspects: models should be confident only for samples for which they are accurate, and the number of samples delegated to experts should be minimized. The latter aspect is especially crucial for applications where available expert time is limited and expensive, such as healthcare. The trade-off between the model accuracy and the number of samples delegated to experts can be represented by a curve that is similar to an ROC curve, which we refer to as confidence operating characteristic (COC) curve. In this paper, we argue that deep neural networks should be trained by taking into account both accuracy and expert load and, to that end, propose a new complementary loss function for classification that maximizes the area under this COC curve. This promotes simultaneously the increase in network accuracy and the reduction in number of samples delegated to humans. We perform experiments on multiple computer vision and medical image datasets for classification. Our results demonstrate that the proposed loss improves classification accuracy and delegates less number of decisions to experts, achieves better out-of-distribution samples detection and on par calibration performance compared to existing loss functions.