 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree Structured Parzen Estimator Approach Tpe
Papers and Code
Auto-Unrolled Proximal Gradient Descent: An AutoML Approach to Interpretable Waveform Optimization
Mar 18, 2026This study explores the combination of automated machine learning (AutoML) with model-based deep unfolding (DU) for optimizing wireless beamforming and waveforms. We convert the iterative proximal gradient descent (PGD) algorithm into a deep neural network, wherein the parameters of each layer are learned instead of being predetermined. Additionally, we enhance the architecture by incorporating a hybrid layer that performs a learnable linear gradient transformation prior to the proximal projection. By utilizing AutoGluon with a tree-structured parzen estimator (TPE) for hyperparameter optimization (HPO) across an expanded search space, which includes network depth, step-size initialization, optimizer, learning rate scheduler, layer type, and post-gradient activation, the proposed auto-unrolled PGD (Auto-PGD) achieves 98.8% of the spectral efficiency of a traditional 200-iteration PGD solver using only five unrolled layers, while requiring only 100 training samples. We also address a gradient normalization issue to ensure consistent performance during training and evaluation, and we illustrate per-layer sum-rate logging as a tool for transparency. These contributions highlight a notable reduction in the amount of training data and inference cost required, while maintaining high interpretability compared to conventional black-box architectures.
Hyperparameter Optimisation with Practical Interpretability and Explanation Methods in Probabilistic Curriculum Learning
Apr 09, 2025Hyperparameter optimisation (HPO) is crucial for achieving strong performance in reinforcement learning (RL), as RL algorithms are inherently sensitive to hyperparameter settings. Probabilistic Curriculum Learning (PCL) is a curriculum learning strategy designed to improve RL performance by structuring the agent's learning process, yet effective hyperparameter tuning remains challenging and computationally demanding. In this paper, we provide an empirical analysis of hyperparameter interactions and their effects on the performance of a PCL algorithm within standard RL tasks, including point-maze navigation and DC motor control. Using the AlgOS framework integrated with Optuna's Tree-Structured Parzen Estimator (TPE), we present strategies to refine hyperparameter search spaces, enhancing optimisation efficiency. Additionally, we introduce a novel SHAP-based interpretability approach tailored specifically for analysing hyperparameter impacts, offering clear insights into how individual hyperparameters and their interactions influence RL performance. Our work contributes practical guidelines and interpretability tools that significantly improve the effectiveness and computational feasibility of hyperparameter optimisation in reinforcement learning.
The M-factor: A Novel Metric for Evaluating Neural Architecture Search in Resource-Constrained Environments
Jan 29, 2025



Neural Architecture Search (NAS) aims to automate the design of deep neural networks. However, existing NAS techniques often focus on maximising accuracy, neglecting model efficiency. This limitation restricts their use in resource-constrained environments like mobile devices and edge computing systems. Moreover, current evaluation metrics prioritise performance over efficiency, lacking a balanced approach for assessing architectures suitable for constrained scenarios. To address these challenges, this paper introduces the M-factor, a novel metric combining model accuracy and size. Four diverse NAS techniques are compared: Policy-Based Reinforcement Learning, Regularised Evolution, Tree-structured Parzen Estimator (TPE), and Multi-trial Random Search. These techniques represent different NAS paradigms, providing a comprehensive evaluation of the M-factor. The study analyses ResNet configurations on the CIFAR-10 dataset, with a search space of 19,683 configurations. Experiments reveal that Policy-Based Reinforcement Learning and Regularised Evolution achieved M-factor values of 0.84 and 0.82, respectively, while Multi-trial Random Search attained 0.75, and TPE reached 0.67. Policy-Based Reinforcement Learning exhibited performance changes after 39 trials, while Regularised Evolution optimised within 20 trials. The research investigates the optimisation dynamics and trade-offs between accuracy and model size for each strategy. Findings indicate that, in some cases, random search performed comparably to more complex algorithms when assessed using the M-factor. These results highlight how the M-factor addresses the limitations of existing metrics by guiding NAS towards balanced architectures, offering valuable insights for selecting strategies in scenarios requiring both performance and efficiency.
Proximal Symmetric Non-negative Latent Factor Analysis: A Novel Approach to Highly-Accurate Representation of Undirected Weighted Networks
Jun 06, 2023An Undirected Weighted Network (UWN) is commonly found in big data-related applications. Note that such a network's information connected with its nodes, and edges can be expressed as a Symmetric, High-Dimensional and Incomplete (SHDI) matrix. However, existing models fail in either modeling its intrinsic symmetry or low-data density, resulting in low model scalability or representation learning ability. For addressing this issue, a Proximal Symmetric Nonnegative Latent-factor-analysis (PSNL) model is proposed. It incorporates a proximal term into symmetry-aware and data density-oriented objective function for high representation accuracy. Then an adaptive Alternating Direction Method of Multipliers (ADMM)-based learning scheme is implemented through a Tree-structured of Parzen Estimators (TPE) method for high computational efficiency. Empirical studies on four UWNs demonstrate that PSNL achieves higher accuracy gain than state-of-the-art models, as well as highly competitive computational efficiency.
Goal-Image Conditioned Dynamic Cable Manipulation through Bayesian Inference and Multi-Objective Black-Box Optimization
Jan 27, 2023



To perform dynamic cable manipulation to realize the configuration specified by a target image, we formulate dynamic cable manipulation as a stochastic forward model. Then, we propose a method to handle uncertainty by maximizing the expectation, which also considers estimation errors of the trained model. To avoid issues like multiple local minima and requirement of differentiability by gradient-based methods, we propose using a black-box optimization (BBO) to optimize joint angles to realize a goal image. Among BBO, we use the Tree-structured Parzen Estimator (TPE), a type of Bayesian optimization. By incorporating constraints into the TPE, the optimized joint angles are constrained within the range of motion. Since TPE is population-based, it is better able to detect multiple feasible configurations using the estimated inverse model. We evaluated image similarity between the target and cable images captured by executing the robot using optimal transport distance. The results show that the proposed method improves accuracy compared to conventional gradient-based approaches and methods that use deterministic models that do not consider uncertainty.
Multi-objective hyperparameter optimization with performance uncertainty
Sep 09, 2022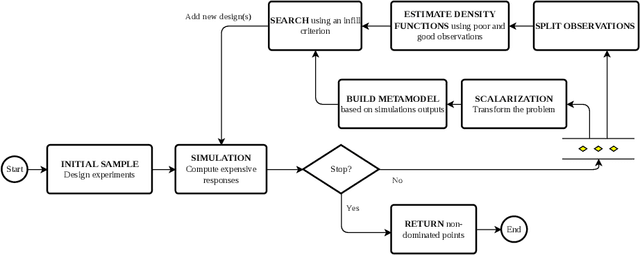
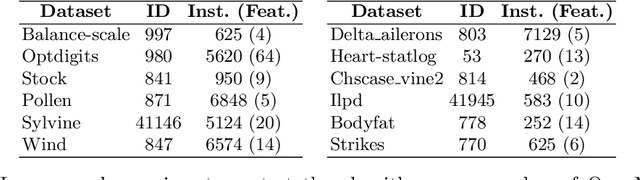
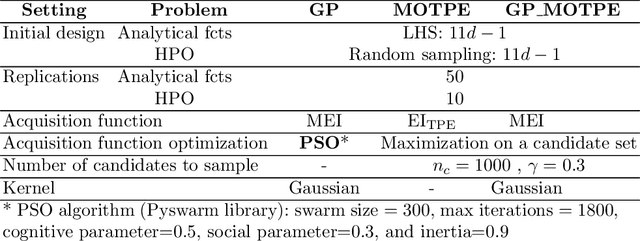
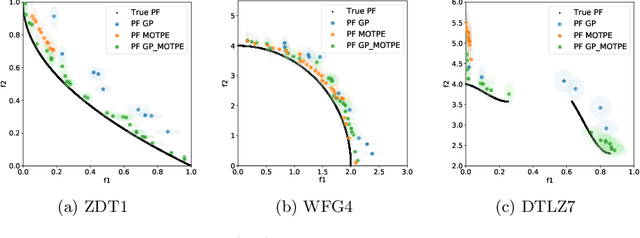
The performance of any Machine Learning (ML) algorithm is impacted by the choice of its hyperparameters. As training and evaluating a ML algorithm is usually expensive, the hyperparameter optimization (HPO) method needs to be computationally efficient to be useful in practice. Most of the existing approaches on multi-objective HPO use evolutionary strategies and metamodel-based optimization. However, few methods have been developed to account for uncertainty in the performance measurements. This paper presents results on multi-objective hyperparameter optimization with uncertainty on the evaluation of ML algorithms. We combine the sampling strategy of Tree-structured Parzen Estimators (TPE) with the metamodel obtained after training a Gaussian Process Regression (GPR) with heterogeneous noise. Experimental results on three analytical test functions and three ML problems show the improvement over multi-objective TPE and GPR, achieved with respect to the hypervolume indicator.
Prediction of Football Player Value using Bayesian Ensemble Approach
Jun 24, 2022



The transfer fees of sports players have become astronomical. This is because bringing players of great future value to the club is essential for their survival. We present a case study on the key factors affecting the world's top soccer players' transfer fees based on the FIFA data analysis. To predict each player's market value, we propose an improved LightGBM model by optimizing its hyperparameter using a Tree-structured Parzen Estimator (TPE) algorithm. We identify prominent features by the SHapley Additive exPlanations (SHAP) algorithm. The proposed method has been compared against the baseline regression models (e.g., linear regression, lasso, elastic net, kernel ridge regression) and gradient boosting model without hyperparameter optimization. The optimized LightGBM model showed an excellent accuracy of approximately 3.8, 1.4, and 1.8 times on average compared to the regression baseline models, GBDT, and LightGBM model in terms of RMSE. Our model offers interpretability in deciding what attributes football clubs should consider in recruiting players in the future.
A XGBoost risk model via feature selection and Bayesian hyper-parameter optimization
Jan 24, 2019
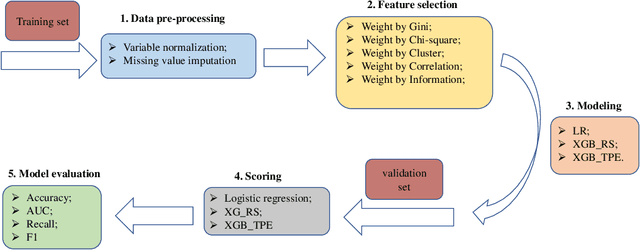
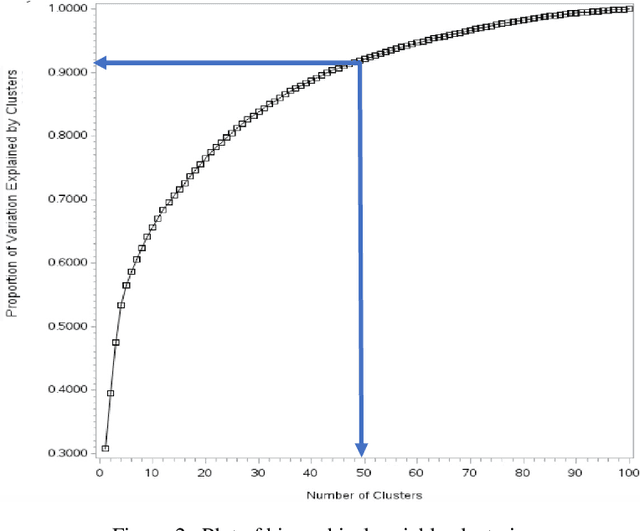
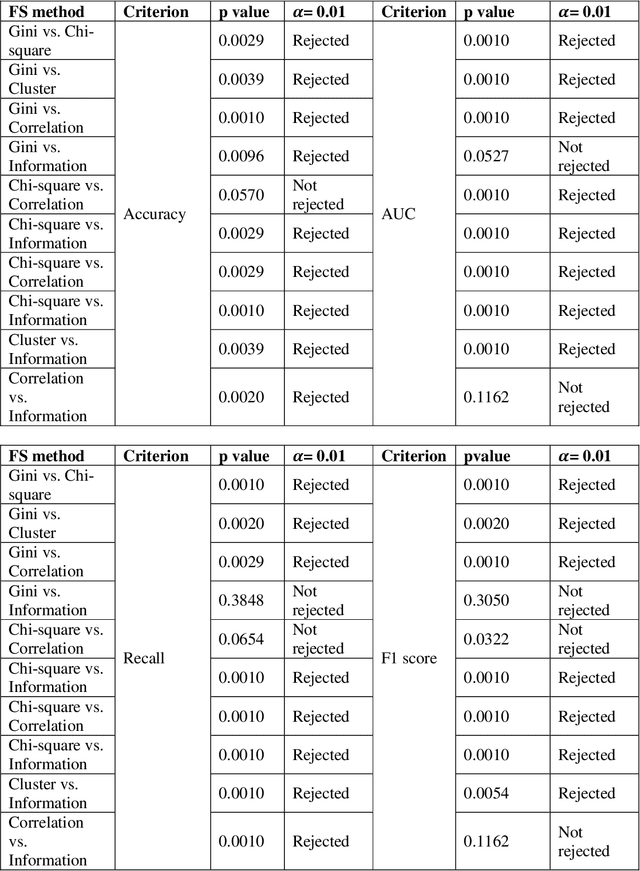
This paper aims to explore models based on the extreme gradient boosting (XGBoost) approach for business risk classification. Feature selection (FS) algorithms and hyper-parameter optimizations are simultaneously considered during model training. The five most commonly used FS methods including weight by Gini, weight by Chi-square, hierarchical variable clustering, weight by correlation, and weight by information are applied to alleviate the effect of redundant features. Two hyper-parameter optimization approaches, random search (RS) and Bayesian tree-structured Parzen Estimator (TPE), are applied in XGBoost. The effect of different FS and hyper-parameter optimization methods on the model performance are investigated by the Wilcoxon Signed Rank Test. The performance of XGBoost is compared to the traditionally utilized logistic regression (LR) model in terms of classification accuracy, area under the curve (AUC), recall, and F1 score obtained from the 10-fold cross validation. Results show that hierarchical clustering is the optimal FS method for LR while weight by Chi-square achieves the best performance in XG-Boost. Both TPE and RS optimization in XGBoost outperform LR significantly. TPE optimization shows a superiority over RS since it results in a significantly higher accuracy and a marginally higher AUC, recall and F1 score. Furthermore, XGBoost with TPE tuning shows a lower variability than the RS method. Finally, the ranking of feature importance based on XGBoost enhances the model interpretation. Therefore, XGBoost with Bayesian TPE hyper-parameter optimization serves as an operative while powerful approach for business risk modeling.