 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Subglacial Bed Topography from Sparse Radar with Physics-Guided Residuals
Nov 18, 2025Accurate subglacial bed topography is essential for ice sheet modeling, yet radar observations are sparse and uneven. We propose a physics-guided residual learning framework that predicts bed thickness residuals over a BedMachine prior and reconstructs bed from the observed surface. A DeepLabV3+ decoder over a standard encoder (e.g.,ResNet-50) is trained with lightweight physics and data terms: multi-scale mass conservation, flow-aligned total variation, Laplacian damping, non-negativity of thickness, a ramped prior-consistency term, and a masked Huber fit to radar picks modulated by a confidence map. To measure real-world generalization, we adopt leakage-safe blockwise hold-outs (vertical/horizontal) with safety buffers and report metrics only on held-out cores. Across two Greenland sub-regions, our approach achieves strong test-core accuracy and high structural fidelity, outperforming U-Net, Attention U-Net, FPN, and a plain CNN. The residual-over-prior design, combined with physics, yields spatially coherent, physically plausible beds suitable for operational mapping under domain shift.
Improving Greenland Bed Topography Mapping with Uncertainty-Aware Graph Learning on Sparse Radar Data
Sep 10, 2025Accurate maps of Greenland's subglacial bed are essential for sea-level projections, but radar observations are sparse and uneven. We introduce GraphTopoNet, a graph-learning framework that fuses heterogeneous supervision and explicitly models uncertainty via Monte Carlo dropout. Spatial graphs built from surface observables (elevation, velocity, mass balance) are augmented with gradient features and polynomial trends to capture both local variability and broad structure. To handle data gaps, we employ a hybrid loss that combines confidence-weighted radar supervision with dynamically balanced regularization. Applied to three Greenland subregions, GraphTopoNet outperforms interpolation, convolutional, and graph-based baselines, reducing error by up to 60 percent while preserving fine-scale glacial features. The resulting bed maps improve reliability for operational modeling, supporting agencies engaged in climate forecasting and policy. More broadly, GraphTopoNet shows how graph machine learning can convert sparse, uncertain geophysical observations into actionable knowledge at continental scale.
DeepTopoNet: A Framework for Subglacial Topography Estimation on the Greenland Ice Sheets
May 29, 2025Understanding Greenland's subglacial topography is critical for projecting the future mass loss of the ice sheet and its contribution to global sea-level rise. However, the complex and sparse nature of observational data, particularly information about the bed topography under the ice sheet, significantly increases the uncertainty in model projections. Bed topography is traditionally measured by airborne ice-penetrating radar that measures the ice thickness directly underneath the aircraft, leaving data gap of tens of kilometers in between flight lines. This study introduces a deep learning framework, which we call as DeepTopoNet, that integrates radar-derived ice thickness observations and BedMachine Greenland data through a novel dynamic loss-balancing mechanism. Among all efforts to reconstruct bed topography, BedMachine has emerged as one of the most widely used datasets, combining mass conservation principles and ice thickness measurements to generate high-resolution bed elevation estimates. The proposed loss function adaptively adjusts the weighting between radar and BedMachine data, ensuring robustness in areas with limited radar coverage while leveraging the high spatial resolution of BedMachine predictions i.e. bed estimates. Our approach incorporates gradient-based and trend surface features to enhance model performance and utilizes a CNN architecture designed for subgrid-scale predictions. By systematically testing on the Upernavik Isstr{\o}m) region, the model achieves high accuracy, outperforming baseline methods in reconstructing subglacial terrain. This work demonstrates the potential of deep learning in bridging observational gaps, providing a scalable and efficient solution to inferring subglacial topography.
Prediction of Football Player Value using Bayesian Ensemble Approach
Jun 24, 2022



The transfer fees of sports players have become astronomical. This is because bringing players of great future value to the club is essential for their survival. We present a case study on the key factors affecting the world's top soccer players' transfer fees based on the FIFA data analysis. To predict each player's market value, we propose an improved LightGBM model by optimizing its hyperparameter using a Tree-structured Parzen Estimator (TPE) algorithm. We identify prominent features by the SHapley Additive exPlanations (SHAP) algorithm. The proposed method has been compared against the baseline regression models (e.g., linear regression, lasso, elastic net, kernel ridge regression) and gradient boosting model without hyperparameter optimization. The optimized LightGBM model showed an excellent accuracy of approximately 3.8, 1.4, and 1.8 times on average compared to the regression baseline models, GBDT, and LightGBM model in terms of RMSE. Our model offers interpretability in deciding what attributes football clubs should consider in recruiting players in the future.
An empirical investigation of different classifiers, encoding and ensemble schemes for next event prediction using business process event logs
Aug 24, 2020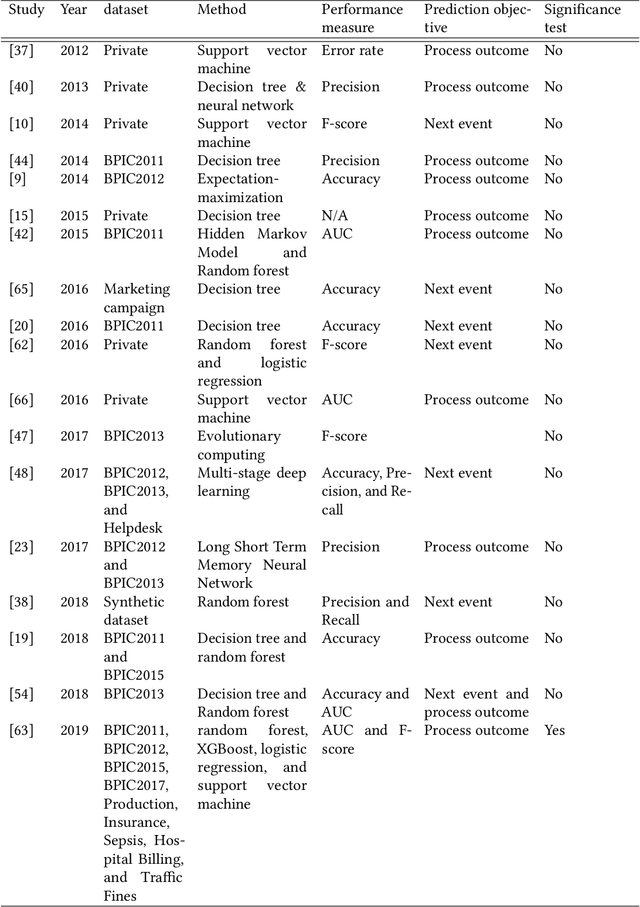
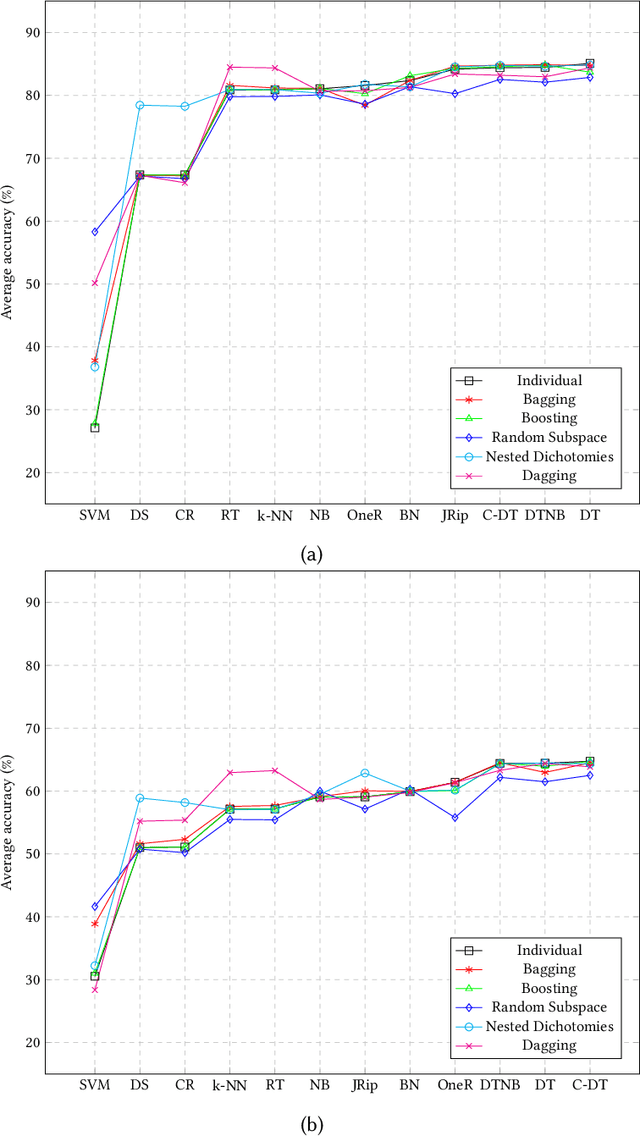
There is a growing need for empirical benchmarks that support researchers and practitioners in selecting the best machine learning technique for given prediction tasks. In this paper, we consider the next event prediction task in business process predictive monitoring and we extend our previously published benchmark by studying the impact on the performance of different encoding windows and of using ensemble schemes. The choice of whether to use ensembles and which scheme to use often depends on the type of data and classification task. While there is a general understanding that ensembles perform well in predictive monitoring of business processes, next event prediction is a task for which no other benchmarks involving ensembles are available. The proposed benchmark helps researchers to select a high performing individual classifier or ensemble scheme given the variability at the case level of the event log under consideration. Experimental results show that choosing an optimal number of events for feature encoding is challenging, resulting in the need to consider each event log individually when selecting an optimal value. Ensemble schemes improve the performance of low performing classifiers in this task, such as SVM, whereas high performing classifiers, such as tree-based classifiers, are not better off when ensemble schemes are considered.