 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThred
Papers and Code
Diversifying Topic-Coherent Response Generation for Natural Multi-turn Conversations
Oct 24, 2019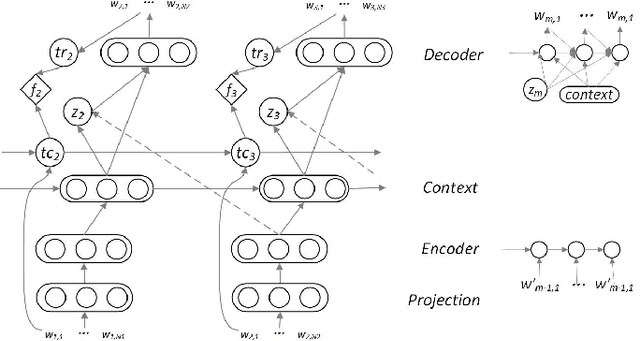
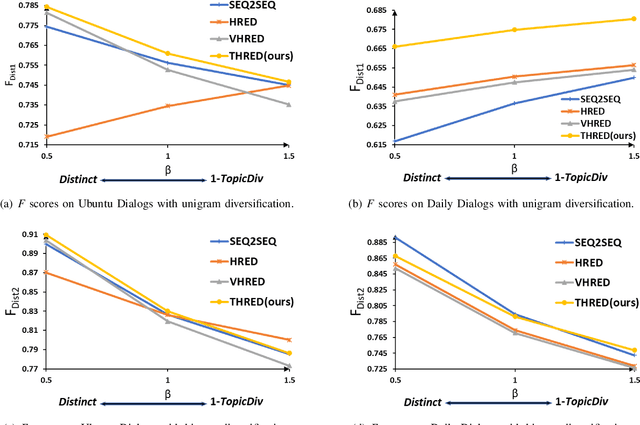

Although response generation (RG) diversification for single-turn dialogs has been well developed, it is less investigated for natural multi-turn conversations. Besides, past work focused on diversifying responses without considering topic coherence to the context, producing uninformative replies. In this paper, we propose the Topic-coherent Hierarchical Recurrent Encoder-Decoder model (THRED) to diversify the generated responses without deviating the contextual topics for multi-turn conversations. In overall, we build a sequence-to-sequence net (Seq2Seq) to model multi-turn conversations. And then we resort to the latent Variable Hierarchical Recurrent Encoder-Decoder model (VHRED) to learn global contextual distribution of dialogs. Besides, we construct a dense topic matrix which implies word-level correlations of the conversation corpora. The topic matrix is used to learn local topic distribution of the contextual utterances. By incorporating both the global contextual distribution and the local topic distribution, THRED produces both diversified and topic-coherent replies. In addition, we propose an explicit metric (\emph{TopicDiv}) to measure the topic divergence between the post and generated response, and we also propose an overall metric combining the diversification metric (\emph{Distinct}) and \emph{TopicDiv}. We evaluate our model comparing with three baselines (Seq2Seq, HRED and VHRED) on two real-world corpora, respectively, and demonstrate its outstanding performance in both diversification and topic coherence.
Augmenting Neural Response Generation with Context-Aware Topical Attention
Nov 02, 2018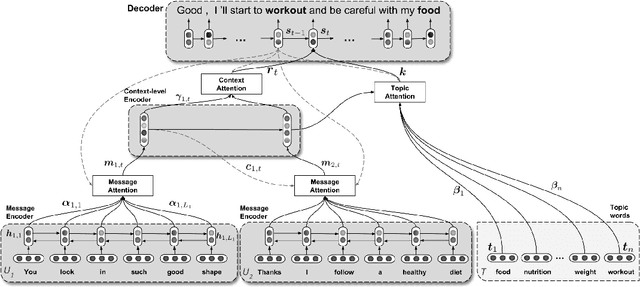

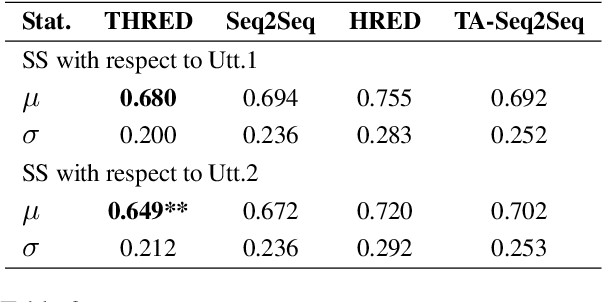
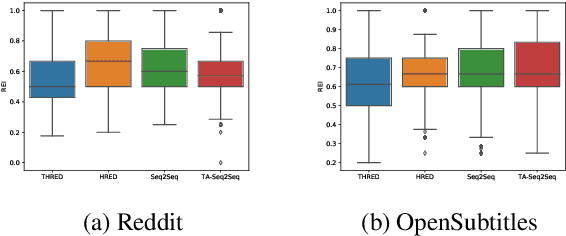
Sequence-to-Sequence (Seq2Seq) models have witnessed a notable success in generating natural conversational exchanges. Notwithstanding the syntactically well-formed responses generated by these neural network models, they are prone to be acontextual, short and generic. In this work, we introduce a Topical Hierarchical Recurrent Encoder Decoder (THRED), a novel, fully data-driven, multi-turn response generation system intended to produce contextual and topic-aware responses. Our model is built upon the basic Seq2Seq model by augmenting it with a hierarchical joint attention mechanism that incorporates topical concepts and previous interactions into the response generation. To train our model, we provide a clean and high-quality conversational dataset mined from Reddit comments. We evaluate THRED on two novel automated metrics, dubbed Semantic Similarity and Response Echo Index, as well as with human evaluation. Our experiments demonstrate that the proposed model is able to generate more diverse and contextually relevant responses compared to the strong baselines.