 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepgame
Papers and Code
An Empirical Study of Conformal Prediction in LLM with ASP Scaffolds for Robust Reasoning
Mar 07, 2025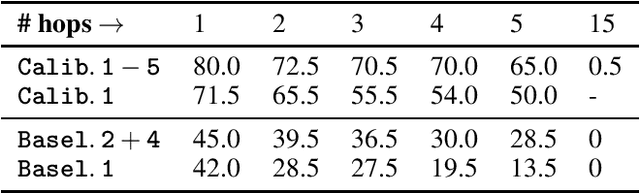

In this paper, we examine the use of Conformal Language Modelling (CLM) alongside Answer Set Programming (ASP) to enhance the performance of standard open-weight LLMs on complex multi-step reasoning tasks. Using the StepGame dataset, which requires spatial reasoning, we apply CLM to generate sets of ASP programs from an LLM, providing statistical guarantees on the correctness of the outputs. Experimental results show that CLM significantly outperforms baseline models that use standard sampling methods, achieving substantial accuracy improvements across different levels of reasoning complexity. Additionally, the LLM-as-Judge metric enhances CLM's performance, especially in assessing structurally and logically correct ASP outputs. However, calibrating CLM with diverse calibration sets did not improve generalizability for tasks requiring much longer reasoning steps, indicating limitations in handling more complex tasks.
Dspy-based Neural-Symbolic Pipeline to Enhance Spatial Reasoning in LLMs
Dec 12, 2024



Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, yet they often struggle with spatial reasoning. This paper presents a novel neural-symbolic framework that enhances LLMs' spatial reasoning abilities through iterative feedback between LLMs and Answer Set Programming (ASP). We evaluate our approach on two benchmark datasets: StepGame and SparQA, implementing three distinct strategies: (1) direct prompting baseline, (2) Facts+Rules prompting, and (3) DSPy-based LLM+ASP pipeline with iterative refinement. Our experimental results demonstrate that the LLM+ASP pipeline significantly outperforms baseline methods, achieving an average 82% accuracy on StepGame and 69% on SparQA, marking improvements of 40-50% and 8-15% respectively over direct prompting. The success stems from three key innovations: (1) effective separation of semantic parsing and logical reasoning through a modular pipeline, (2) iterative feedback mechanism between LLMs and ASP solvers that improves program rate, and (3) robust error handling that addresses parsing, grounding, and solving failures. Additionally, we propose Facts+Rules as a lightweight alternative that achieves comparable performance on complex SparQA dataset, while reducing computational overhead.Our analysis across different LLM architectures (Deepseek, Llama3-70B, GPT-4.0 mini) demonstrates the framework's generalizability and provides insights into the trade-offs between implementation complexity and reasoning capability, contributing to the development of more interpretable and reliable AI systems.
A Pipeline of Neural-Symbolic Integration to Enhance Spatial Reasoning in Large Language Models
Nov 27, 2024Large Language Models (LLMs) have demonstrated impressive capabilities across various tasks. However, LLMs often struggle with spatial reasoning which is one essential part of reasoning and inference and requires understanding complex relationships between objects in space. This paper proposes a novel neural-symbolic framework that enhances LLMs' spatial reasoning abilities. We evaluate our approach on two benchmark datasets: StepGame and SparQA, implementing three distinct strategies: (1) ASP (Answer Set Programming)-based symbolic reasoning, (2) LLM + ASP pipeline using DSPy, and (3) Fact + Logical rules. Our experiments demonstrate significant improvements over the baseline prompting methods, with accuracy increases of 40-50% on StepGame} dataset and 3-13% on the more complex SparQA dataset. The "LLM + ASP" pipeline achieves particularly strong results on the tasks of Finding Relations (FR) and Finding Block (FB) questions, though performance varies across different question types. The impressive results suggest that while neural-symbolic approaches offer promising directions for enhancing spatial reasoning in LLMs, their effectiveness depends heavily on the specific task characteristics and implementation strategies. We propose an integrated, simple yet effective set of strategies using a neural-symbolic pipeline to boost spatial reasoning abilities in LLMs. This pipeline and its strategies demonstrate strong and broader applicability to other reasoning domains in LLMs, such as temporal reasoning, deductive inference etc.
Advancing Spatial Reasoning in Large Language Models: An In-Depth Evaluation and Enhancement Using the StepGame Benchmark
Jan 08, 2024



Artificial intelligence (AI) has made remarkable progress across various domains, with large language models like ChatGPT gaining substantial attention for their human-like text-generation capabilities. Despite these achievements, spatial reasoning remains a significant challenge for these models. Benchmarks like StepGame evaluate AI spatial reasoning, where ChatGPT has shown unsatisfactory performance. However, the presence of template errors in the benchmark has an impact on the evaluation results. Thus there is potential for ChatGPT to perform better if these template errors are addressed, leading to more accurate assessments of its spatial reasoning capabilities. In this study, we refine the StepGame benchmark, providing a more accurate dataset for model evaluation. We analyze GPT's spatial reasoning performance on the rectified benchmark, identifying proficiency in mapping natural language text to spatial relations but limitations in multi-hop reasoning. We provide a flawless solution to the benchmark by combining template-to-relation mapping with logic-based reasoning. This combination demonstrates proficiency in performing qualitative reasoning on StepGame without encountering any errors. We then address the limitations of GPT models in spatial reasoning. We deploy Chain-of-thought and Tree-of-thoughts prompting strategies, offering insights into GPT's ``cognitive process", and achieving remarkable improvements in accuracy. Our investigation not only sheds light on model deficiencies but also proposes enhancements, contributing to the advancement of AI with more robust spatial reasoning capabilities.
Coupling Large Language Models with Logic Programming for Robust and General Reasoning from Text
Jul 15, 2023



While large language models (LLMs), such as GPT-3, appear to be robust and general, their reasoning ability is not at a level to compete with the best models trained for specific natural language reasoning problems. In this study, we observe that a large language model can serve as a highly effective few-shot semantic parser. It can convert natural language sentences into a logical form that serves as input for answer set programs, a logic-based declarative knowledge representation formalism. The combination results in a robust and general system that can handle multiple question-answering tasks without requiring retraining for each new task. It only needs a few examples to guide the LLM's adaptation to a specific task, along with reusable ASP knowledge modules that can be applied to multiple tasks. We demonstrate that this method achieves state-of-the-art performance on several NLP benchmarks, including bAbI, StepGame, CLUTRR, and gSCAN. Additionally, it successfully tackles robot planning tasks that an LLM alone fails to solve.
StepGame: A New Benchmark for Robust Multi-Hop Spatial Reasoning in Texts
Apr 18, 2022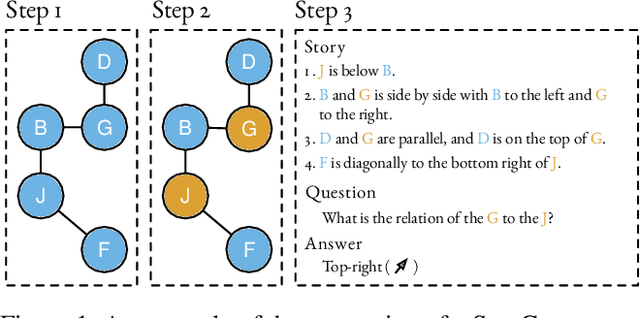
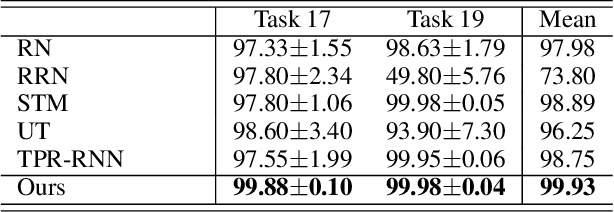
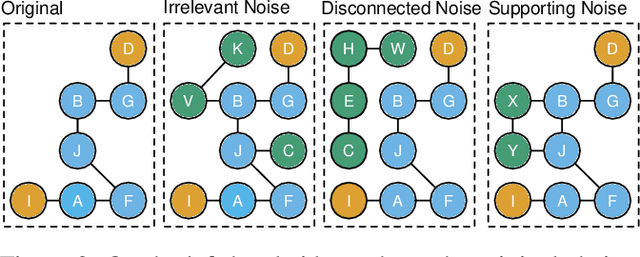

Inferring spatial relations in natural language is a crucial ability an intelligent system should possess. The bAbI dataset tries to capture tasks relevant to this domain (task 17 and 19). However, these tasks have several limitations. Most importantly, they are limited to fixed expressions, they are limited in the number of reasoning steps required to solve them, and they fail to test the robustness of models to input that contains irrelevant or redundant information. In this paper, we present a new Question-Answering dataset called StepGame for robust multi-hop spatial reasoning in texts. Our experiments demonstrate that state-of-the-art models on the bAbI dataset struggle on the StepGame dataset. Moreover, we propose a Tensor-Product based Memory-Augmented Neural Network (TP-MANN) specialized for spatial reasoning tasks. Experimental results on both datasets show that our model outperforms all the baselines with superior generalization and robustness performance.