 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePipedream
Papers and Code
GraphPipe: Improving Performance and Scalability of DNN Training with Graph Pipeline Parallelism
Jun 24, 2024



Deep neural networks (DNNs) continue to grow rapidly in size, making them infeasible to train on a single device. Pipeline parallelism is commonly used in existing DNN systems to support large-scale DNN training by partitioning a DNN into multiple stages, which concurrently perform DNN training for different micro-batches in a pipeline fashion. However, existing pipeline-parallel approaches only consider sequential pipeline stages and thus ignore the topology of a DNN, resulting in missed model-parallel opportunities. This paper presents graph pipeline parallelism (GPP), a new pipeline-parallel scheme that partitions a DNN into pipeline stages whose dependencies are identified by a directed acyclic graph. GPP generalizes existing sequential pipeline parallelism and preserves the inherent topology of a DNN to enable concurrent execution of computationally-independent operators, resulting in reduced memory requirement and improved GPU performance. In addition, we develop GraphPipe, a distributed system that exploits GPP strategies to enable performant and scalable DNN training. GraphPipe partitions a DNN into a graph of stages, optimizes micro-batch schedules for these stages, and parallelizes DNN training using the discovered GPP strategies. Evaluation on a variety of DNNs shows that GraphPipe outperforms existing pipeline-parallel systems such as PipeDream and Piper by up to 1.6X. GraphPipe also reduces the search time by 9-21X compared to PipeDream and Piper.
PipeOptim: Ensuring Effective 1F1B Schedule with Optimizer-Dependent Weight Prediction
Dec 05, 2023Asynchronous pipeline model parallelism with a "1F1B" (one forward, one backward) schedule generates little bubble overhead and always provides quite a high throughput. However, the "1F1B" schedule inevitably leads to weight inconsistency and weight staleness issues due to the cross-training of different mini-batches across GPUs. To simultaneously address these two problems, in this paper, we propose an optimizer-dependent weight prediction strategy (a.k.a PipeOptim) for asynchronous pipeline training. The key insight of our proposal is that we employ a weight prediction strategy in the forward pass to ensure that each mini-batch uses consistent and staleness-free weights to compute the forward pass. To be concrete, we first construct the weight prediction scheme based on the update rule of the used optimizer when training the deep neural network models. Then throughout the "1F1B" pipelined training, each mini-batch is mandated to execute weight prediction ahead of the forward pass, subsequently employing the predicted weights to perform the forward pass. As a result, PipeOptim 1) inherits the advantage of the "1F1B" schedule and generates pretty high throughput, and 2) can ensure effective parameter learning regardless of the type of the used optimizer. To verify the effectiveness of our proposal, we conducted extensive experimental evaluations using eight different deep-learning models spanning three machine-learning tasks including image classification, sentiment analysis, and machine translation. The experiment results demonstrate that PipeOptim outperforms the popular pipelined approaches including GPipe, PipeDream, PipeDream-2BW, and SpecTrain. The code of PipeOptim can be accessible at https://github.com/guanleics/PipeOptim.
Pipeline Parallelism for Inference on Heterogeneous Edge Computing
Oct 28, 2021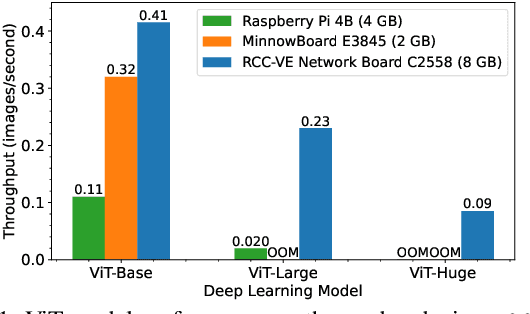

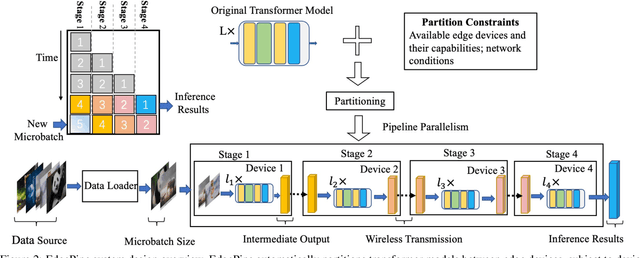

Deep neural networks with large model sizes achieve state-of-the-art results for tasks in computer vision (CV) and natural language processing (NLP). However, these large-scale models are too compute- or memory-intensive for resource-constrained edge devices. Prior works on parallel and distributed execution primarily focus on training -- rather than inference -- using homogeneous accelerators in data centers. We propose EdgePipe, a distributed framework for edge systems that uses pipeline parallelism to both speed up inference and enable running larger (and more accurate) models that otherwise cannot fit on single edge devices. EdgePipe achieves these results by using an optimal partition strategy that considers heterogeneity in compute, memory, and network bandwidth. Our empirical evaluation demonstrates that EdgePipe achieves $10.59\times$ and $11.88\times$ speedup using 16 edge devices for the ViT-Large and ViT-Huge models, respectively, with no accuracy loss. Similarly, EdgePipe improves ViT-Huge throughput by $3.93\times$ over a 4-node baseline using 16 edge devices, which independently cannot fit the model in memory. Finally, we show up to $4.16\times$ throughput improvement over the state-of-the-art PipeDream when using a heterogeneous set of devices.
LayerPipe: Accelerating Deep Neural Network Training by Intra-Layer and Inter-Layer Gradient Pipelining and Multiprocessor Scheduling
Aug 14, 2021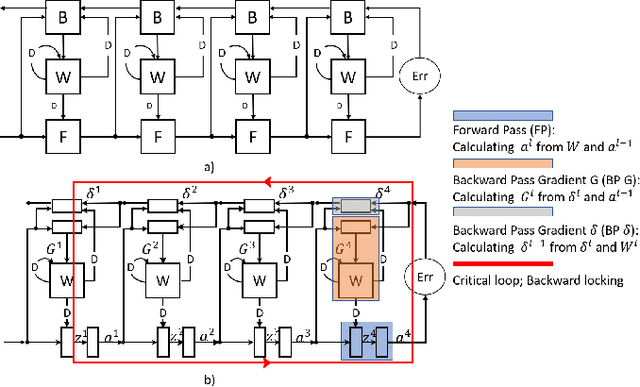
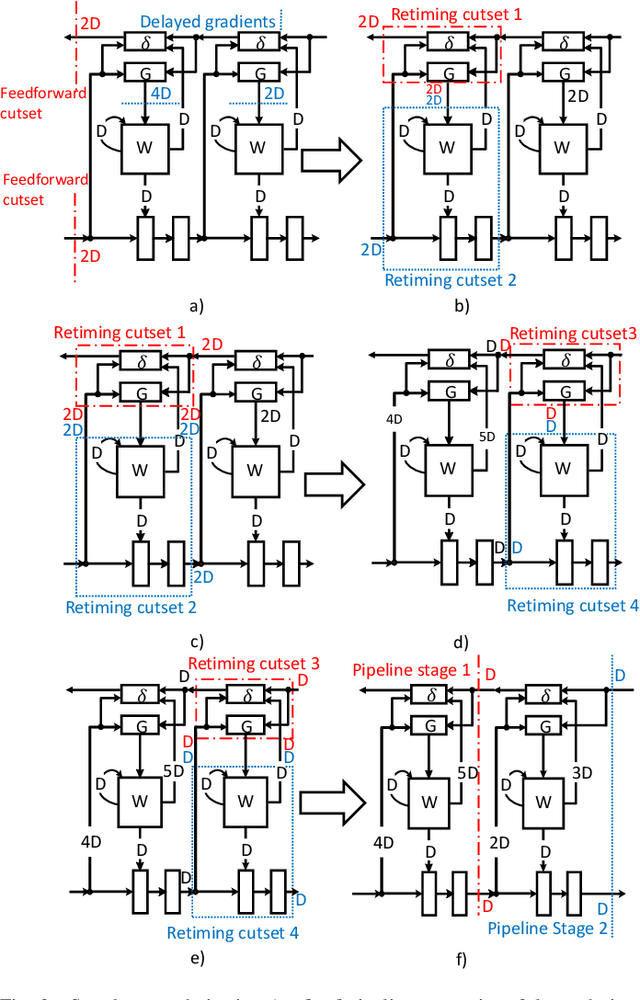
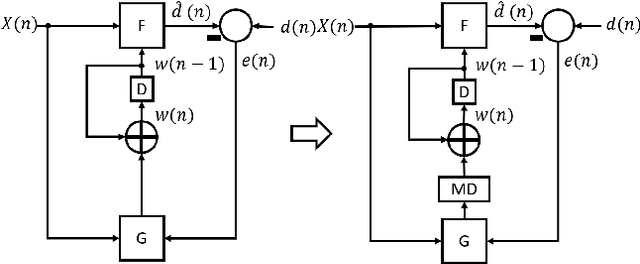
The time required for training the neural networks increases with size, complexity, and depth. Training model parameters by backpropagation inherently creates feedback loops. These loops hinder efficient pipelining and scheduling of the tasks within the layer and between consecutive layers. Prior approaches, such as PipeDream, have exploited the use of delayed gradient to achieve inter-layer pipelining. However, these approaches treat the entire backpropagation as a single task; this leads to an increase in computation time and processor underutilization. This paper presents novel optimization approaches where the gradient computations with respect to the weights and the activation functions are considered independently; therefore, these can be computed in parallel. This is referred to as intra-layer optimization. Additionally, the gradient computation with respect to the activation function is further divided into two parts and distributed to two consecutive layers. This leads to balanced scheduling where the computation time of each layer is the same. This is referred to as inter-layer optimization. The proposed system, referred to as LayerPipe, reduces the number of clock cycles required for training while maximizing processor utilization with minimal inter-processor communication overhead. LayerPipe achieves an average speedup of 25% and upwards of 80% with 7 to 9 processors with less communication overhead when compared to PipeDream.
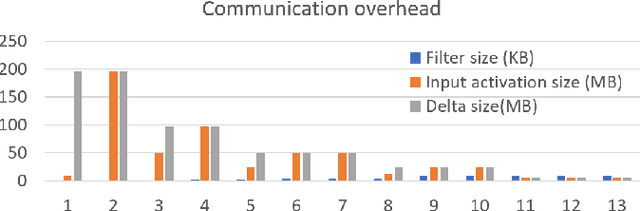
Memory-Efficient Pipeline-Parallel DNN Training
Jun 16, 2020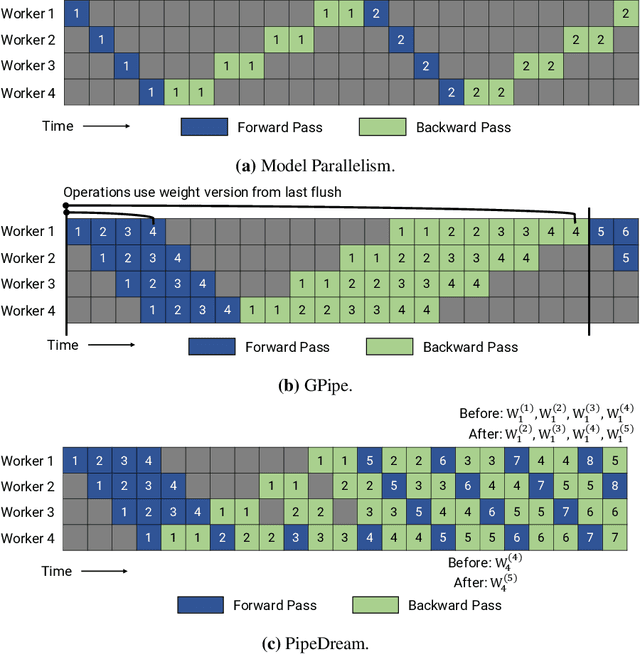
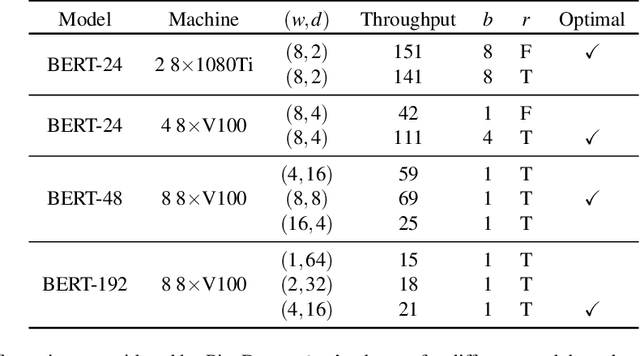
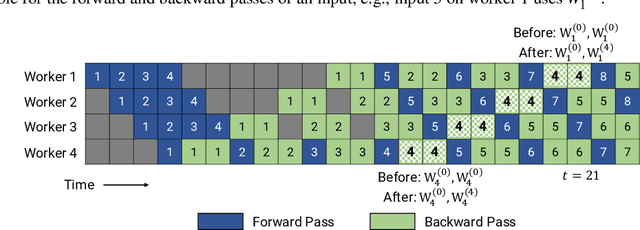
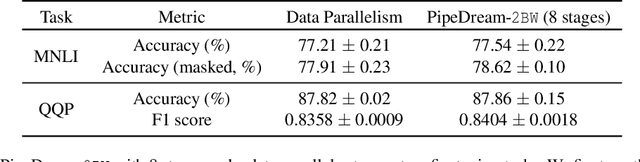
Many state-of-the-art results in domains such as NLP and computer vision have been obtained by scaling up the number of parameters in existing models. However, the weight parameters and intermediate outputs of these large models often do not fit in the main memory of a single accelerator device; this means that it is necessary to use multiple accelerators to train large models, which is challenging to do in a time-efficient way. In this work, we propose PipeDream-2BW, a system that performs memory-efficient pipeline parallelism, a hybrid form of parallelism that combines data and model parallelism with input pipelining. Our system uses a novel pipelining and weight gradient coalescing strategy, combined with the double buffering of weights, to ensure high throughput, low memory footprint, and weight update semantics similar to data parallelism. In addition, PipeDream-2BW automatically partitions the model over the available hardware resources, while being cognizant of constraints such as compute capabilities, memory capacities, and interconnect topologies, and determines when to employ existing memory-savings techniques, such as activation recomputation, that trade off extra computation for lower memory footprint. PipeDream-2BW is able to accelerate the training of large language models with up to 2.5 billion parameters by up to 6.9x compared to optimized baselines.