 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusan
Papers and Code
Noise-Robust AV-ASR Using Visual Features Both in the Whisper Encoder and Decoder
Jan 26, 2026In audiovisual automatic speech recognition (AV-ASR) systems, information fusion of visual features in a pre-trained ASR has been proven as a promising method to improve noise robustness. In this work, based on the prominent Whisper ASR, first, we propose a simple and effective visual fusion method -- use of visual features both in encoder and decoder (dual-use) -- to learn the audiovisual interactions in the encoder and to weigh modalities in the decoder. Second, we compare visual fusion methods in Whisper models of various sizes. Our proposed dual-use method shows consistent noise robustness improvement, e.g., a 35% relative improvement (WER: 4.41% vs. 6.83%) based on Whisper small, and a 57% relative improvement (WER: 4.07% vs. 9.53%) based on Whisper medium, compared to typical reference middle fusion in babble noise with a signal-to-noise ratio (SNR) of 0dB. Third, we conduct ablation studies examining the impact of various module designs and fusion options. Fine-tuned on 1929 hours of audiovisual data, our dual-use method using Whisper medium achieves 4.08% (MUSAN babble noise) and 4.43% (NoiseX babble noise) average WER across various SNRs, thereby establishing a new state-of-the-art in noisy conditions on the LRS3 AV-ASR benchmark. Our code is at https://github.com/ifnspaml/Dual-Use-AVASR
Exploring WavLM Back-ends for Speech Spoofing and Deepfake Detection
Sep 08, 2024



This paper describes our submitted systems to the ASVspoof 5 Challenge Track 1: Speech Deepfake Detection - Open Condition, which consists of a stand-alone speech deepfake (bonafide vs spoof) detection task. Recently, large-scale self-supervised models become a standard in Automatic Speech Recognition (ASR) and other speech processing tasks. Thus, we leverage a pre-trained WavLM as a front-end model and pool its representations with different back-end techniques. The complete framework is fine-tuned using only the trained dataset of the challenge, similar to the close condition. Besides, we adopt data-augmentation by adding noise and reverberation using MUSAN noise and RIR datasets. We also experiment with codec augmentations to increase the performance of our method. Ultimately, we use the Bosaris toolkit for score calibration and system fusion to get better Cllr scores. Our fused system achieves 0.0937 minDCF, 3.42% EER, 0.1927 Cllr, and 0.1375 actDCF.
On the Efficacy and Noise-Robustness of Jointly Learned Speech Emotion and Automatic Speech Recognition
May 25, 2023


New-age conversational agent systems perform both speech emotion recognition (SER) and automatic speech recognition (ASR) using two separate and often independent approaches for real-world application in noisy environments. In this paper, we investigate a joint ASR-SER multitask learning approach in a low-resource setting and show that improvements are observed not only in SER, but also in ASR. We also investigate the robustness of such jointly trained models to the presence of background noise, babble, and music. Experimental results on the IEMOCAP dataset show that joint learning can improve ASR word error rate (WER) and SER classification accuracy by 10.7% and 2.3% respectively in clean scenarios. In noisy scenarios, results on data augmented with MUSAN show that the joint approach outperforms the independent ASR and SER approaches across many noisy conditions. Overall, the joint ASR-SER approach yielded more noise-resistant models than the independent ASR and SER approaches.
LSTM-TDNN with convolutional front-end for Dialect Identification in the 2019 Multi-Genre Broadcast Challenge
Dec 19, 2019

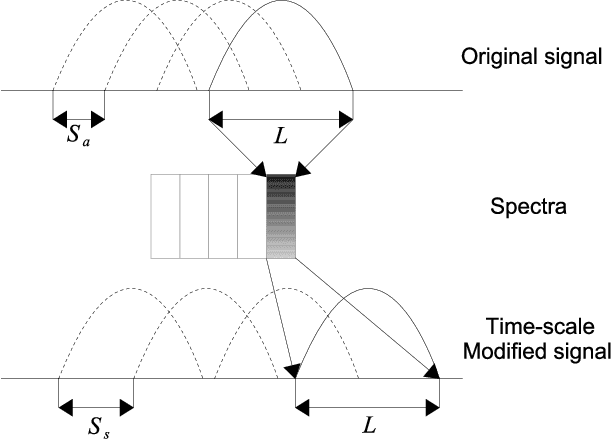
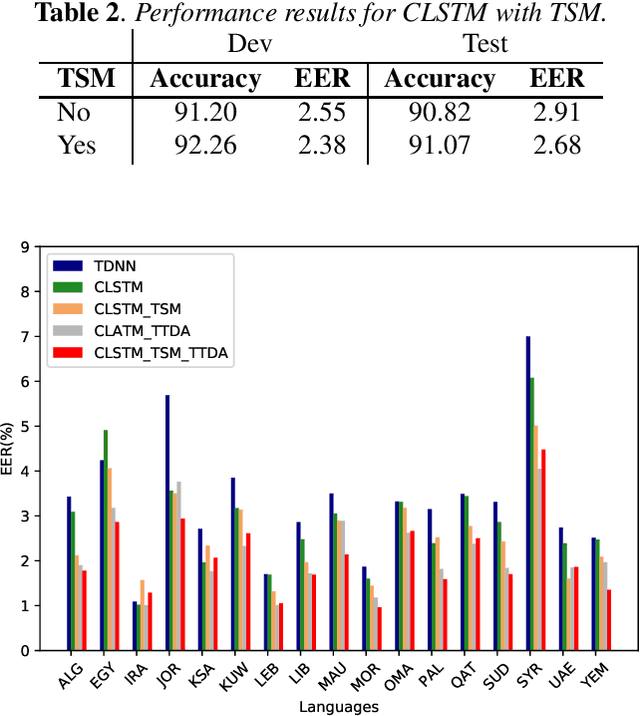
This paper presents a novel Dialect Identification (DID) system developed for the Fifth Edition of the Multi-Genre Broadcast challenge, the task of Fine-grained Arabic Dialect Identification (MGB-5 ADI Challenge). The system improves upon traditional DNN x-vector performance by employing a Convolutional and Long Short Term Memory-Recurrent (CLSTM) architecture to combine the benefits of a convolutional neural network front-end for feature extraction and a back-end recurrent neural to capture longer temporal dependencies. Furthermore we investigate intensive augmentation of one low resource dialect in the highly unbalanced training set using time-scale modification (TSM). This converts an utterance to several time-stretched or time-compressed versions, subsequently used to train the CLSTM system without using any other corpus. In this paper, we also investigate speech augmentation using MUSAN and the RIR datasets to increase the quantity and diversity of the existing training data in the normal way. Results show firstly that the CLSTM architecture outperforms a traditional DNN x-vector implementation. Secondly, adopting TSM-based speed perturbation yields a small performance improvement for the unbalanced data, finally that traditional data augmentation techniques yield further benefit, in line with evidence from related speaker and language recognition tasks. Our system achieved 2nd place ranking out of 15 entries in the MGB-5 ADI challenge, presented at ASRU 2019.
SwishNet: A Fast Convolutional Neural Network for Speech, Music and Noise Classification and Segmentation
Dec 01, 2018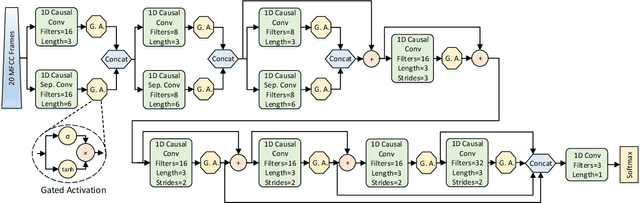
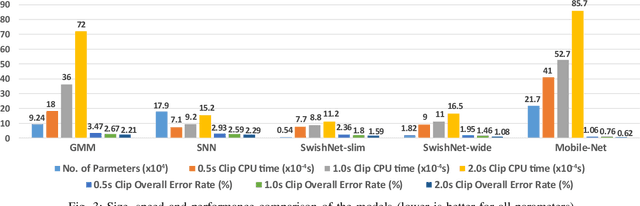
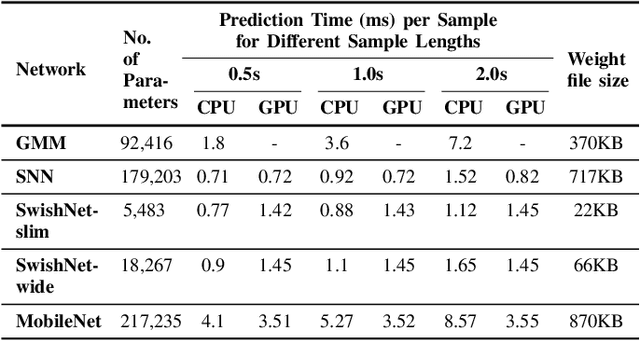
Speech, Music and Noise classification/segmentation is an important preprocessing step for audio processing/indexing. To this end, we propose a novel 1D Convolutional Neural Network (CNN) - SwishNet. It is a fast and lightweight architecture that operates on MFCC features which is suitable to be added to the front-end of an audio processing pipeline. We showed that the performance of our network can be improved by distilling knowledge from a 2D CNN, pretrained on ImageNet. We investigated the performance of our network on the MUSAN corpus - an openly available comprehensive collection of noise, music and speech samples, suitable for deep learning. The proposed network achieved high overall accuracy in clip (length of 0.5-2s) classification (>97% accuracy) and frame-wise segmentation (>93% accuracy) tasks with even higher accuracy (>99%) in speech/non-speech discrimination task. To verify the robustness of our model, we trained it on MUSAN and evaluated it on a different corpus - GTZAN and found good accuracy with very little fine-tuning. We also demonstrated that our model is fast on both CPU and GPU, consumes a low amount of memory and is suitable for implementation in embedded systems.