 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGatv2
Papers and Code
FlowSymm: Physics Aware, Symmetry Preserving Graph Attention for Network Flow Completion
Jan 29, 2026Recovering missing flows on the edges of a network, while exactly respecting local conservation laws, is a fundamental inverse problem that arises in many systems such as transportation, energy, and mobility. We introduce FlowSymm, a novel architecture that combines (i) a group-action on divergence-free flows, (ii) a graph-attention encoder to learn feature-conditioned weights over these symmetry-preserving actions, and (iii) a lightweight Tikhonov refinement solved via implicit bilevel optimization. The method first anchors the given observation on a minimum-norm divergence-free completion. We then compute an orthonormal basis for all admissible group actions that leave the observed flows invariant and parameterize the valid solution subspace, which shows an Abelian group structure under vector addition. A stack of GATv2 layers then encodes the graph and its edge features into per-edge embeddings, which are pooled over the missing edges and produce per-basis attention weights. This attention-guided process selects a set of physics-aware group actions that preserve the observed flows. Finally, a scalar Tikhonov penalty refines the missing entries via a convex least-squares solver, with gradients propagated implicitly through Cholesky factorization. Across three real-world flow benchmarks (traffic, power, bike), FlowSymm outperforms state-of-the-art baselines in RMSE, MAE and correlation metrics.
Feature-Enhanced Graph Neural Networks for Classification of Synthetic Graph Generative Models: A Benchmarking Study
Dec 20, 2025



The ability to discriminate between generative graph models is critical to understanding complex structural patterns in both synthetic graphs and the real-world structures that they emulate. While Graph Neural Networks (GNNs) have seen increasing use to great effect in graph classification tasks, few studies explore their integration with interpretable graph theoretic features. This paper investigates the classification of synthetic graph families using a hybrid approach that combines GNNs with engineered graph-theoretic features. We generate a large and structurally diverse synthetic dataset comprising graphs from five representative generative families, Erdos-Renyi, Watts-Strogatz, Barab'asi-Albert, Holme-Kim, and Stochastic Block Model. These graphs range in size up to 1x10^4 nodes, containing up to 1.1x10^5 edges. A comprehensive range of node and graph level features is extracted for each graph and pruned using a Random Forest based feature selection pipeline. The features are integrated into six GNN architectures: GCN, GAT, GATv2, GIN, GraphSAGE and GTN. Each architecture is optimised for hyperparameter selection using Optuna. Finally, models were compared against a baseline Support Vector Machine (SVM) trained solely on the handcrafted features. Our evaluation demonstrates that GraphSAGE and GTN achieve the highest classification performance, with 98.5% accuracy, and strong class separation evidenced by t-SNE and UMAP visualisations. GCN and GIN also performed well, while GAT-based models lagged due to limitations in their ability to capture global structures. The SVM baseline confirmed the importance of the message passing functionality for performance gains and meaningful class separation.
Exploring a Graph-based Approach to Offline Reinforcement Learning for Sepsis Treatment
Sep 03, 2025Sepsis is a serious, life-threatening condition. When treating sepsis, it is challenging to determine the correct amount of intravenous fluids and vasopressors for a given patient. While automated reinforcement learning (RL)-based methods have been used to support these decisions with promising results, previous studies have relied on relational data. Given the complexity of modern healthcare data, representing data as a graph may provide a more natural and effective approach. This study models patient data from the well-known MIMIC-III dataset as a heterogeneous graph that evolves over time. Subsequently, we explore two Graph Neural Network architectures - GraphSAGE and GATv2 - for learning patient state representations, adopting the approach of decoupling representation learning from policy learning. The encoders are trained to produce latent state representations, jointly with decoders that predict the next patient state. These representations are then used for policy learning with the dBCQ algorithm. The results of our experimental evaluation confirm the potential of a graph-based approach, while highlighting the complexity of representation learning in this domain.
On the Power of Graph Neural Networks and Feature Augmentation Strategies to Classify Social Networks
Jan 11, 2024This paper studies four Graph Neural Network architectures (GNNs) for a graph classification task on a synthetic dataset created using classic generative models of Network Science. Since the synthetic networks do not contain (node or edge) features, five different augmentation strategies (artificial feature types) are applied to nodes. All combinations of the 4 GNNs (GCN with Hierarchical and Global aggregation, GIN and GATv2) and the 5 feature types (constant 1, noise, degree, normalized degree and ID -- a vector of the number of cycles of various lengths) are studied and their performances compared as a function of the hidden dimension of artificial neural networks used in the GNNs. The generalisation ability of these models is also analysed using a second synthetic network dataset (containing networks of different sizes).Our results point towards the balanced importance of the computational power of the GNN architecture and the the information level provided by the artificial features. GNN architectures with higher computational power, like GIN and GATv2, perform well for most augmentation strategies. On the other hand, artificial features with higher information content, like ID or degree, not only consistently outperform other augmentation strategies, but can also help GNN architectures with lower computational power to achieve good performance.
GraPhSyM: Graph Physical Synthesis Model
Aug 07, 2023In this work, we introduce GraPhSyM, a Graph Attention Network (GATv2) model for fast and accurate estimation of post-physical synthesis circuit delay and area metrics from pre-physical synthesis circuit netlists. Once trained, GraPhSyM provides accurate visibility of final design metrics to early EDA stages, such as logic synthesis, without running the slow physical synthesis flow, enabling global co-optimization across stages. Additionally, the swift and precise feedback provided by GraPhSym is instrumental for machine-learning-based EDA optimization frameworks. Given a gate-level netlist of a circuit represented as a graph, GraPhSyM utilizes graph structure, connectivity, and electrical property features to predict the impact of physical synthesis transformations such as buffer insertion and gate sizing. When trained on a dataset of 6000 prefix adder designs synthesized at an aggressive delay target, GraPhSyM can accurately predict the post-synthesis delay (98.3%) and area (96.1%) metrics of unseen adders with a fast 0.22s inference time. Furthermore, we illustrate the compositionality of GraPhSyM by employing the model trained on a fixed delay target to accurately anticipate post-synthesis metrics at a variety of unseen delay targets. Lastly, we report promising generalization capabilities of the GraPhSyM model when it is evaluated on circuits different from the adders it was exclusively trained on. The results show the potential for GraPhSyM to serve as a powerful tool for advanced optimization techniques and as an oracle for EDA machine learning frameworks.
Optimization and Interpretability of Graph Attention Networks for Small Sparse Graph Structures in Automotive Applications
May 25, 2023For automotive applications, the Graph Attention Network (GAT) is a prominently used architecture to include relational information of a traffic scenario during feature embedding. As shown in this work, however, one of the most popular GAT realizations, namely GATv2, has potential pitfalls that hinder an optimal parameter learning. Especially for small and sparse graph structures a proper optimization is problematic. To surpass limitations, this work proposes architectural modifications of GATv2. In controlled experiments, it is shown that the proposed model adaptions improve prediction performance in a node-level regression task and make it more robust to parameter initialization. This work aims for a better understanding of the attention mechanism and analyzes its interpretability of identifying causal importance.
Gradient Derivation for Learnable Parameters in Graph Attention Networks
Apr 21, 2023

This work provides a comprehensive derivation of the parameter gradients for GATv2 [4], a widely used implementation of Graph Attention Networks (GATs). GATs have proven to be powerful frameworks for processing graph-structured data and, hence, have been used in a range of applications. However, the achieved performance by these attempts has been found to be inconsistent across different datasets and the reasons for this remains an open research question. As the gradient flow provides valuable insights into the training dynamics of statistically learning models, this work obtains the gradients for the trainable model parameters of GATv2. The gradient derivations supplement the efforts of [2], where potential pitfalls of GATv2 are investigated.
Who You Play Affects How You Play: Predicting Sports Performance Using Graph Attention Networks With Temporal Convolution
Mar 29, 2023



This study presents a novel deep learning method, called GATv2-GCN, for predicting player performance in sports. To construct a dynamic player interaction graph, we leverage player statistics and their interactions during gameplay. We use a graph attention network to capture the attention that each player pays to each other, allowing for more accurate modeling of the dynamic player interactions. To handle the multivariate player statistics time series, we incorporate a temporal convolution layer, which provides the model with temporal predictive power. We evaluate the performance of our model using real-world sports data, demonstrating its effectiveness in predicting player performance. Furthermore, we explore the potential use of our model in a sports betting context, providing insights into profitable strategies that leverage our predictive power. The proposed method has the potential to advance the state-of-the-art in player performance prediction and to provide valuable insights for sports analytics and betting industries.
Distance-Geometric Graph Attention Network (DG-GAT) for 3D Molecular Geometry
Jul 16, 2022Deep learning for molecular science has so far mainly focused on 2D molecular graphs. Recently, however, there has been work to extend it to 3D molecular geometry, due to its scientific significance and critical importance in real-world applications. The 3D distance-geometric graph representation (DG-GR) adopts a unified scheme (distance) for representing the geometry of 3D graphs. It is invariant to rotation and translation of the graph, and it reflects pair-wise node interactions and their generally local nature, particularly relevant for 3D molecular geometry. To facilitate the incorporation of 3D molecular geometry in deep learning for molecular science, we adopt the new graph attention network with dynamic attention (GATv2) for use with DG-GR and propose the 3D distance-geometric graph attention network (DG-GAT). GATv2 is a great fit for DG-GR since the attention can vary by node and by distance between nodes. Experimental results of DG-GAT for the ESOL and FreeSolv datasets show major improvement (31% and 38%, respectively) over those of the standard graph convolution network based on 2D molecular graphs. The same is true for the QM9 dataset. Our work demonstrates the utility and value of DG-GAT for deep learning based on 3D molecular geometry.
How Attentive are Graph Attention Networks?
May 30, 2021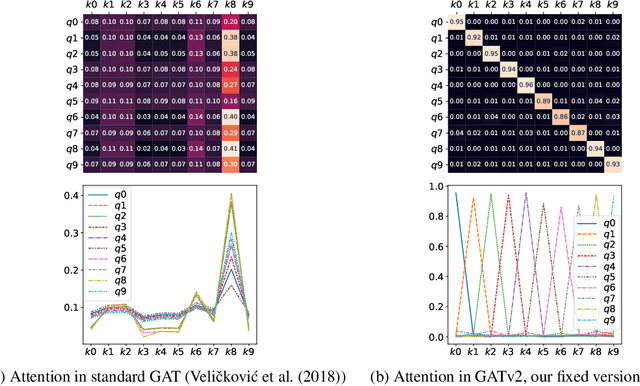
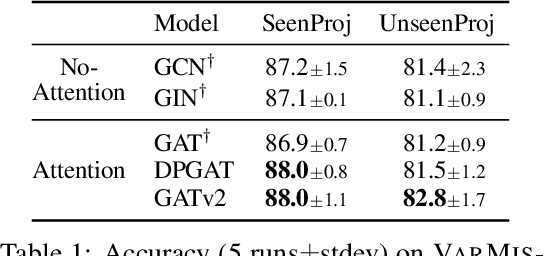
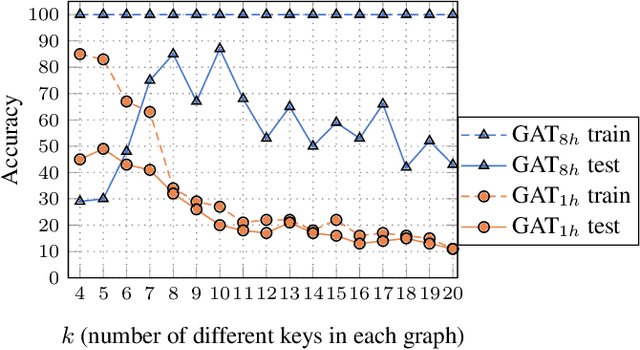
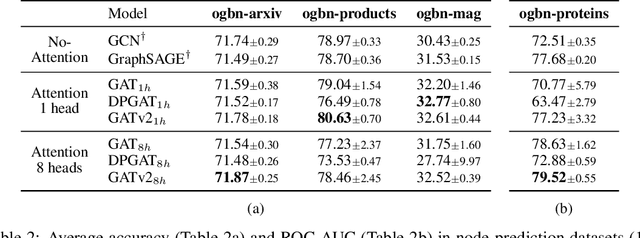
Graph Attention Networks (GATs) are one of the most popular GNN architectures and are considered as the state-of-the-art architecture for representation learning with graphs. In GAT, every node attends to its neighbors given its own representation as the query. However, in this paper we show that GATs can only compute a restricted kind of attention where the ranking of attended nodes is unconditioned on the query node. We formally define this restricted kind of attention as static attention and distinguish it from a strictly more expressive dynamic attention. Because GATs use a static attention mechanism, there are simple graph problems that GAT cannot express: in a controlled problem, we show that static attention hinders GAT from even fitting the training data. To remove this limitation, we introduce a simple fix by modifying the order of operations and propose GATv2: a dynamic graph attention variant that is strictly more expressive than GAT. We perform an extensive evaluation and show that GATv2 outperforms GAT across 11 OGB and other benchmarks while we match their parametric costs. Our code is available at https://github.com/tech-srl/how_attentive_are_gats .