 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoodseg103
Papers and Code
BenchSeg: A Large-Scale Dataset and Benchmark for Multi-View Food Video Segmentation
Jan 12, 2026Food image segmentation is a critical task for dietary analysis, enabling accurate estimation of food volume and nutrients. However, current methods suffer from limited multi-view data and poor generalization to new viewpoints. We introduce BenchSeg, a novel multi-view food video segmentation dataset and benchmark. BenchSeg aggregates 55 dish scenes (from Nutrition5k, Vegetables & Fruits, MetaFood3D, and FoodKit) with 25,284 meticulously annotated frames, capturing each dish under free 360° camera motion. We evaluate a diverse set of 20 state-of-the-art segmentation models (e.g., SAM-based, transformer, CNN, and large multimodal) on the existing FoodSeg103 dataset and evaluate them (alone and combined with video-memory modules) on BenchSeg. Quantitative and qualitative results demonstrate that while standard image segmenters degrade sharply under novel viewpoints, memory-augmented methods maintain temporal consistency across frames. Our best model based on a combination of SeTR-MLA+XMem2 outperforms prior work (e.g., improving over FoodMem by ~2.63% mAP), offering new insights into food segmentation and tracking for dietary analysis. We release BenchSeg to foster future research. The project page including the dataset annotations and the food segmentation models can be found at https://amughrabi.github.io/benchseg.
Swin-TUNA : A Novel PEFT Approach for Accurate Food Image Segmentation
Jul 24, 2025



In the field of food image processing, efficient semantic segmentation techniques are crucial for industrial applications. However, existing large-scale Transformer-based models (such as FoodSAM) face challenges in meeting practical deploymentrequirements due to their massive parameter counts and high computational resource demands. This paper introduces TUNable Adapter module (Swin-TUNA), a Parameter Efficient Fine-Tuning (PEFT) method that integrates multiscale trainable adapters into the Swin Transformer architecture, achieving high-performance food image segmentation by updating only 4% of the parameters. The core innovation of Swin-TUNA lies in its hierarchical feature adaptation mechanism: it designs separable convolutions in depth and dimensional mappings of varying scales to address the differences in features between shallow and deep networks, combined with a dynamic balancing strategy for tasks-agnostic and task-specific features. Experiments demonstrate that this method achieves mIoU of 50.56% and 74.94% on the FoodSeg103 and UECFoodPix Complete datasets, respectively, surpassing the fully parameterized FoodSAM model while reducing the parameter count by 98.7% (to only 8.13M). Furthermore, Swin-TUNA exhibits faster convergence and stronger generalization capabilities in low-data scenarios, providing an efficient solution for assembling lightweight food image.
Exploring PCA-based feature representations of image pixels via CNN to enhance food image segmentation
Nov 05, 2024



For open vocabulary recognition of ingredients in food images, segmenting the ingredients is a crucial step. This paper proposes a novel approach that explores PCA-based feature representations of image pixels using a convolutional neural network (CNN) to enhance segmentation. An internal clustering metric based on the silhouette score is defined to evaluate the clustering quality of various pixel-level feature representations generated by different feature maps derived from various CNN backbones. Using this metric, the paper explores optimal feature representation selection and suitable clustering methods for ingredient segmentation. Additionally, it is found that principal component (PC) maps derived from concatenations of backbone feature maps improve the clustering quality of pixel-level feature representations, resulting in stable segmentation outcomes. Notably, the number of selected eigenvalues can be used as the number of clusters to achieve good segmentation results. The proposed method performs well on the ingredient-labeled dataset FoodSeg103, achieving a mean Intersection over Union (mIoU) score of 0.5423. Importantly, the proposed method is unsupervised, and pixel-level feature representations from backbones are not fine-tuned on specific datasets. This demonstrates the flexibility, generalizability, and interpretability of the proposed method, while reducing the need for extensive labeled datasets.
OVFoodSeg: Elevating Open-Vocabulary Food Image Segmentation via Image-Informed Textual Representation
Apr 01, 2024In the realm of food computing, segmenting ingredients from images poses substantial challenges due to the large intra-class variance among the same ingredients, the emergence of new ingredients, and the high annotation costs associated with large food segmentation datasets. Existing approaches primarily utilize a closed-vocabulary and static text embeddings setting. These methods often fall short in effectively handling the ingredients, particularly new and diverse ones. In response to these limitations, we introduce OVFoodSeg, a framework that adopts an open-vocabulary setting and enhances text embeddings with visual context. By integrating vision-language models (VLMs), our approach enriches text embedding with image-specific information through two innovative modules, eg, an image-to-text learner FoodLearner and an Image-Informed Text Encoder. The training process of OVFoodSeg is divided into two stages: the pre-training of FoodLearner and the subsequent learning phase for segmentation. The pre-training phase equips FoodLearner with the capability to align visual information with corresponding textual representations that are specifically related to food, while the second phase adapts both the FoodLearner and the Image-Informed Text Encoder for the segmentation task. By addressing the deficiencies of previous models, OVFoodSeg demonstrates a significant improvement, achieving an 4.9\% increase in mean Intersection over Union (mIoU) on the FoodSeg103 dataset, setting a new milestone for food image segmentation.
Food Image Classification and Segmentation with Attention-based Multiple Instance Learning
Aug 22, 2023



The demand for accurate food quantification has increased in the recent years, driven by the needs of applications in dietary monitoring. At the same time, computer vision approaches have exhibited great potential in automating tasks within the food domain. Traditionally, the development of machine learning models for these problems relies on training data sets with pixel-level class annotations. However, this approach introduces challenges arising from data collection and ground truth generation that quickly become costly and error-prone since they must be performed in multiple settings and for thousands of classes. To overcome these challenges, the paper presents a weakly supervised methodology for training food image classification and semantic segmentation models without relying on pixel-level annotations. The proposed methodology is based on a multiple instance learning approach in combination with an attention-based mechanism. At test time, the models are used for classification and, concurrently, the attention mechanism generates semantic heat maps which are used for food class segmentation. In the paper, we conduct experiments on two meta-classes within the FoodSeg103 data set to verify the feasibility of the proposed approach and we explore the functioning properties of the attention mechanism.
Transferring Knowledge for Food Image Segmentation using Transformers and Convolutions
Jun 15, 2023Food image segmentation is an important task that has ubiquitous applications, such as estimating the nutritional value of a plate of food. Although machine learning models have been used for segmentation in this domain, food images pose several challenges. One challenge is that food items can overlap and mix, making them difficult to distinguish. Another challenge is the degree of inter-class similarity and intra-class variability, which is caused by the varying preparation methods and dishes a food item may be served in. Additionally, class imbalance is an inevitable issue in food datasets. To address these issues, two models are trained and compared, one based on convolutional neural networks and the other on Bidirectional Encoder representation for Image Transformers (BEiT). The models are trained and valuated using the FoodSeg103 dataset, which is identified as a robust benchmark for food image segmentation. The BEiT model outperforms the previous state-of-the-art model by achieving a mean intersection over union of 49.4 on FoodSeg103. This study provides insights into transfering knowledge using convolution and Transformer-based approaches in the food image domain.
A Large-Scale Benchmark for Food Image Segmentation
May 12, 2021
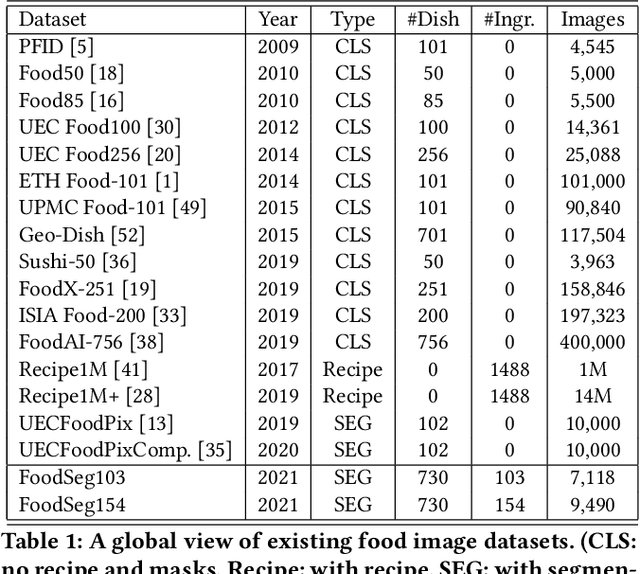

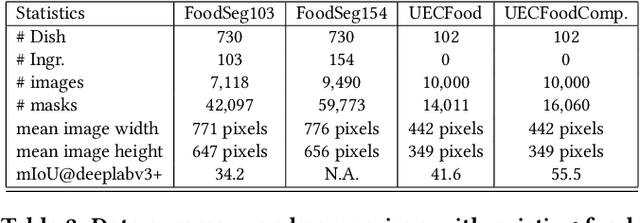
Food image segmentation is a critical and indispensible task for developing health-related applications such as estimating food calories and nutrients. Existing food image segmentation models are underperforming due to two reasons: (1) there is a lack of high quality food image datasets with fine-grained ingredient labels and pixel-wise location masks -- the existing datasets either carry coarse ingredient labels or are small in size; and (2) the complex appearance of food makes it difficult to localize and recognize ingredients in food images, e.g., the ingredients may overlap one another in the same image, and the identical ingredient may appear distinctly in different food images. In this work, we build a new food image dataset FoodSeg103 (and its extension FoodSeg154) containing 9,490 images. We annotate these images with 154 ingredient classes and each image has an average of 6 ingredient labels and pixel-wise masks. In addition, we propose a multi-modality pre-training approach called ReLeM that explicitly equips a segmentation model with rich and semantic food knowledge. In experiments, we use three popular semantic segmentation methods (i.e., Dilated Convolution based, Feature Pyramid based, and Vision Transformer based) as baselines, and evaluate them as well as ReLeM on our new datasets. We believe that the FoodSeg103 (and its extension FoodSeg154) and the pre-trained models using ReLeM can serve as a benchmark to facilitate future works on fine-grained food image understanding. We make all these datasets and methods public at \url{https://xiongweiwu.github.io/foodseg103.html}.