 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNesting Forward Automatic Differentiation for Memory-Efficient Deep Neural Network Training
Paper and Code
Sep 22, 2022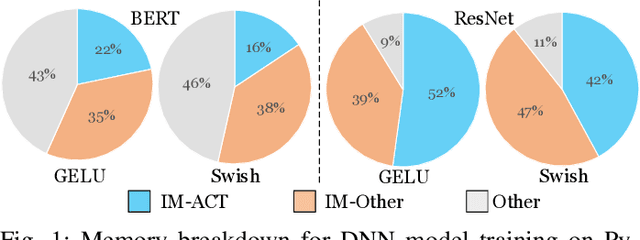
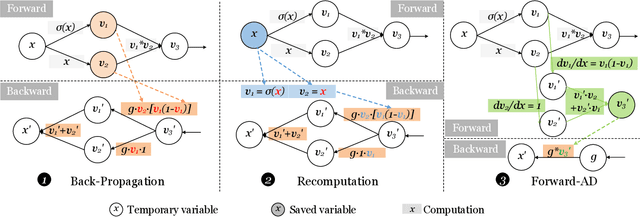
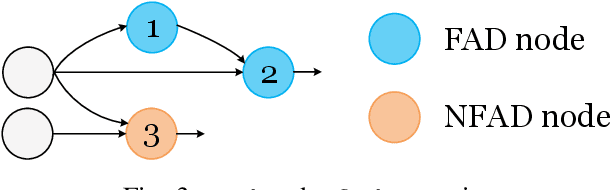
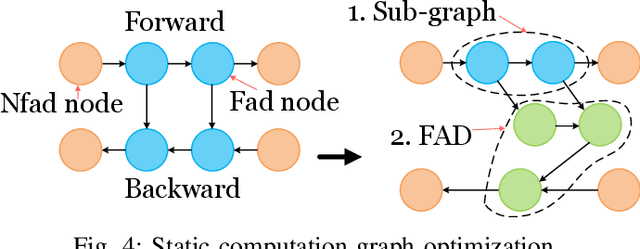
An activation function is an element-wise mathematical function and plays a crucial role in deep neural networks (DNN). Many novel and sophisticated activation functions have been proposed to improve the DNN accuracy but also consume massive memory in the training process with back-propagation. In this study, we propose the nested forward automatic differentiation (Forward-AD), specifically for the element-wise activation function for memory-efficient DNN training. We deploy nested Forward-AD in two widely-used deep learning frameworks, TensorFlow and PyTorch, which support the static and dynamic computation graph, respectively. Our evaluation shows that nested Forward-AD reduces the memory footprint by up to 1.97x than the baseline model and outperforms the recomputation by 20% under the same memory reduction ratio.