 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANT: Exploiting Adaptive Numerical Data Type for Low-bit Deep Neural Network Quantization
Paper and Code
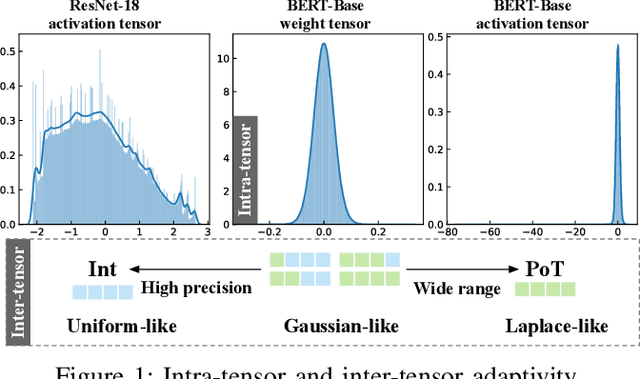
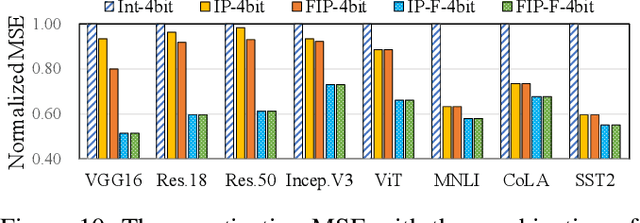
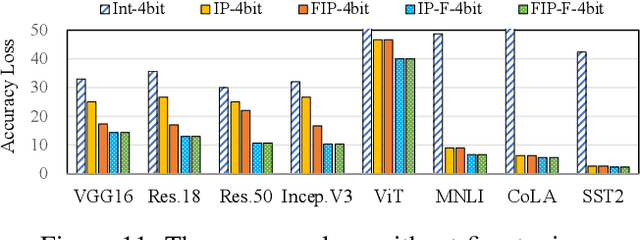
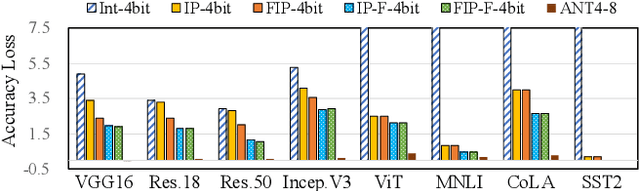
Quantization is a technique to reduce the computation and memory cost of DNN models, which are getting increasingly large. Existing quantization solutions use fixed-point integer or floating-point types, which have limited benefits, as both require more bits to maintain the accuracy of original models. On the other hand, variable-length quantization uses low-bit quantization for normal values and high-precision for a fraction of outlier values. Even though this line of work brings algorithmic benefits, it also introduces significant hardware overheads due to variable-length encoding and decoding. In this work, we propose a fixed-length adaptive numerical data type called ANT to achieve low-bit quantization with tiny hardware overheads. Our data type ANT leverages two key innovations to exploit the intra-tensor and inter-tensor adaptive opportunities in DNN models. First, we propose a particular data type, flint, that combines the advantages of float and int for adapting to the importance of different values within a tensor. Second, we propose an adaptive framework that selects the best type for each tensor according to its distribution characteristics. We design a unified processing element architecture for ANT and show its ease of integration with existing DNN accelerators. Our design results in 2.8$\times$ speedup and 2.5$\times$ energy efficiency improvement over the state-of-the-art quantization accelerators.