 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Reinforcement Learning Based Video Semantic Coding for Segmentation
Paper and Code
Aug 24, 2022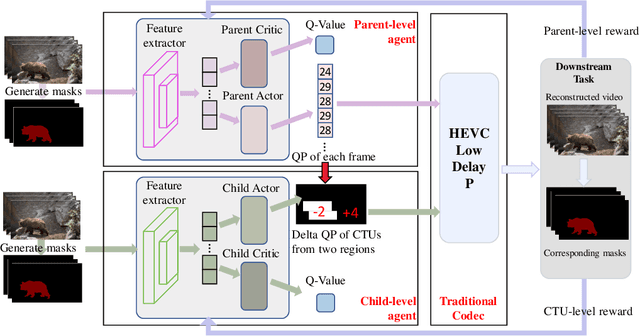
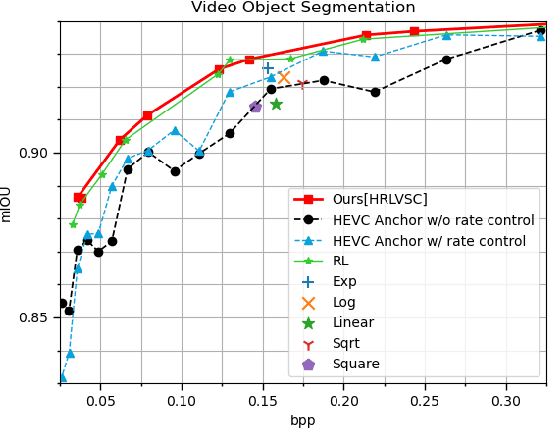
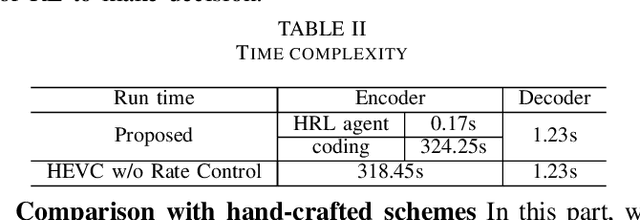
The rapid development of intelligent tasks, e.g., segmentation, detection, classification, etc, has brought an urgent need for semantic compression, which aims to reduce the compression cost while maintaining the original semantic information. However, it is impractical to directly integrate the semantic metric into the traditional codecs since they cannot be optimized in an end-to-end manner. To solve this problem, some pioneering works have applied reinforcement learning to implement image-wise semantic compression. Nevertheless, video semantic compression has not been explored since its complex reference architectures and compression modes. In this paper, we take a step forward to video semantic compression and propose the Hierarchical Reinforcement Learning based task-driven Video Semantic Coding, named as HRLVSC. Specifically, to simplify the complex mode decision of video semantic coding, we divided the action space into frame-level and CTU-level spaces in a hierarchical manner, and then explore the best mode selection for them progressively with the cooperation of frame-level and CTU-level agents. Moreover, since the modes of video semantic coding will exponentially increase with the number of frames in a Group of Pictures (GOP), we carefully investigate the effects of different mode selections for video semantic coding and design a simple but effective mode simplification strategy for it. We have validated our HRLVSC on the video segmentation task with HEVC reference software HM16.19. Extensive experimental results demonstrated that our HRLVSC can achieve over 39% BD-rate saving for video semantic coding under the Low Delay P configuration.