 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProposalContrast: Unsupervised Pre-training for LiDAR-based 3D Object Detection
Paper and Code

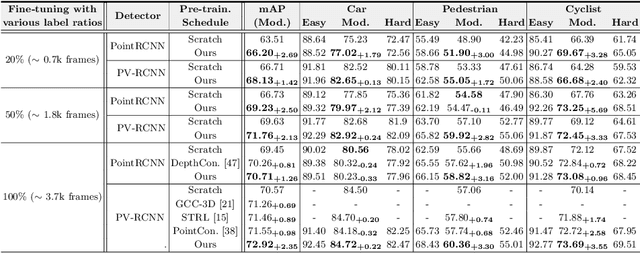
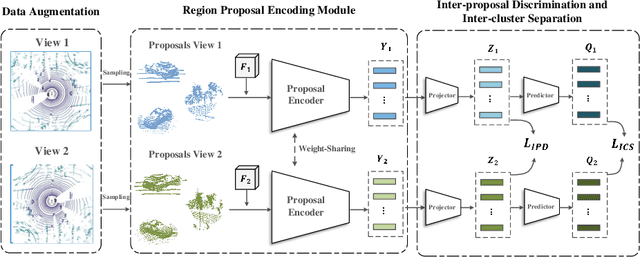
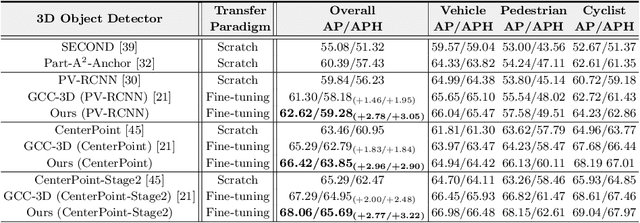
Existing approaches for unsupervised point cloud pre-training are constrained to either scene-level or point/voxel-level instance discrimination. Scene-level methods tend to lose local details that are crucial for recognizing the road objects, while point/voxel-level methods inherently suffer from limited receptive field that is incapable of perceiving large objects or context environments. Considering region-level representations are more suitable for 3D object detection, we devise a new unsupervised point cloud pre-training framework, called ProposalContrast, that learns robust 3D representations by contrasting region proposals. Specifically, with an exhaustive set of region proposals sampled from each point cloud, geometric point relations within each proposal are modeled for creating expressive proposal representations. To better accommodate 3D detection properties, ProposalContrast optimizes with both inter-cluster and inter-proposal separation, i.e., sharpening the discriminativeness of proposal representations across semantic classes and object instances. The generalizability and transferability of ProposalContrast are verified on various 3D detectors (i.e., PV-RCNN, CenterPoint, PointPillars and PointRCNN) and datasets (i.e., KITTI, Waymo and ONCE).