 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieverTTS: Modeling Decomposed Factors for Text-Based Speech Insertion
Paper and Code
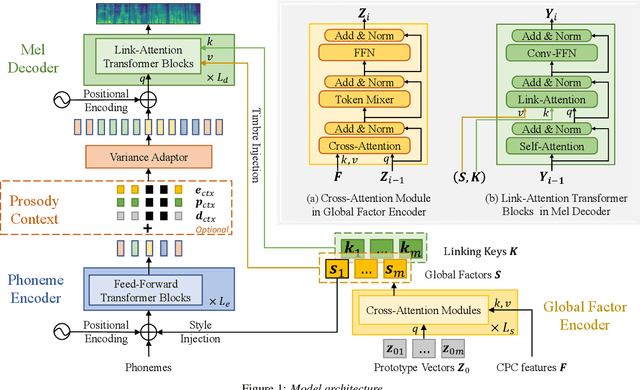
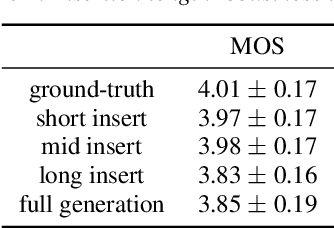
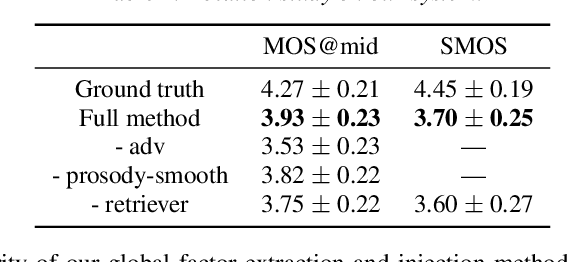
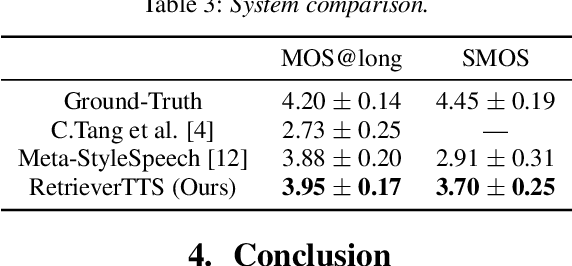
This paper proposes a new "decompose-and-edit" paradigm for the text-based speech insertion task that facilitates arbitrary-length speech insertion and even full sentence generation. In the proposed paradigm, global and local factors in speech are explicitly decomposed and separately manipulated to achieve high speaker similarity and continuous prosody. Specifically, we proposed to represent the global factors by multiple tokens, which are extracted by cross-attention operation and then injected back by link-attention operation. Due to the rich representation of global factors, we manage to achieve high speaker similarity in a zero-shot manner. In addition, we introduce a prosody smoothing task to make the local prosody factor context-aware and therefore achieve satisfactory prosody continuity. We further achieve high voice quality with an adversarial training stage. In the subjective test, our method achieves state-of-the-art performance in both naturalness and similarity. Audio samples can be found at https://ydcustc.github.io/retrieverTTS-demo/.