 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Image Modeling with Denoising Contrast
Paper and Code
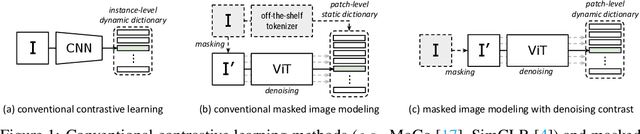
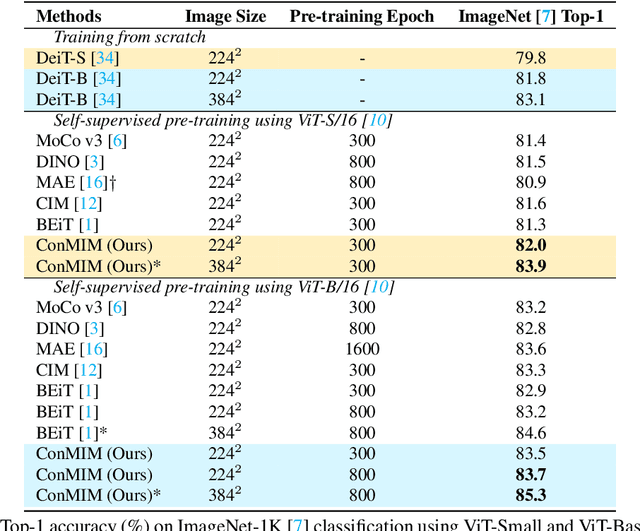
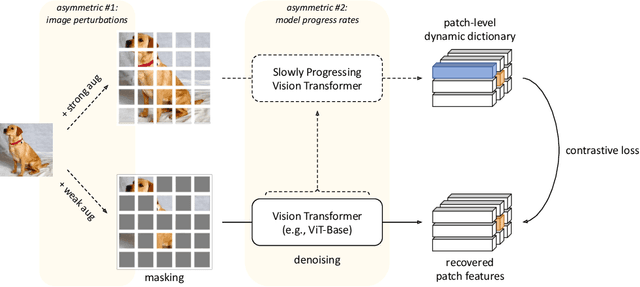

Since the development of self-supervised visual representation learning from contrastive learning to masked image modeling, there is no significant difference in essence, that is, how to design proper pretext tasks for vision dictionary look-up. Masked image modeling recently dominates this line of research with state-of-the-art performance on vision Transformers, where the core is to enhance the patch-level visual context capturing of the network via denoising auto-encoding mechanism. Rather than tailoring image tokenizers with extra training stages as in previous works, we unleash the great potential of contrastive learning on denoising auto-encoding and introduce a new pre-training method, ConMIM, to produce simple intra-image inter-patch contrastive constraints as the learning objectives for masked patch prediction. We further strengthen the denoising mechanism with asymmetric designs, including image perturbations and model progress rates, to improve the network pre-training. ConMIM-pretrained vision Transformers with various scales achieve promising results on downstream image classification, semantic segmentation, object detection, and instance segmentation tasks.