 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptiveON: Adaptive Outdoor Navigation Method For Stable and Reliable Actions
Paper and Code

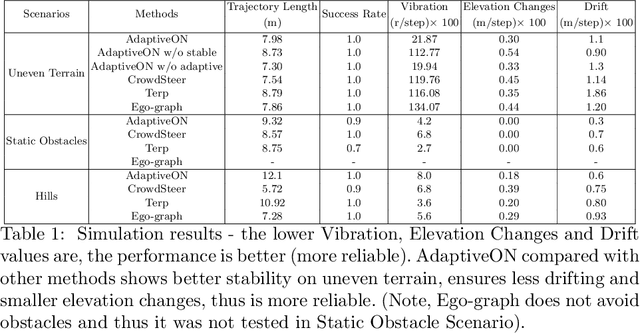
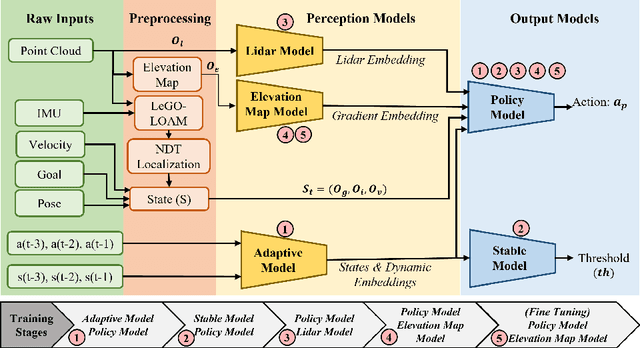
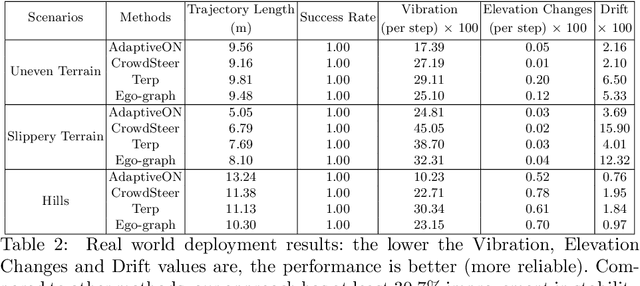
We present a novel outdoor navigation algorithm to generate stable and efficient actions to navigate a robot to the goal. We use a multi-stage training pipeline and show that our model produces policies that result in stable and reliable robot navigation on complex terrains. Based on the Proximal Policy Optimization (PPO) algorithm, we developed a novel method to achieve multiple capabilities for outdoor navigation tasks, namely: alleviating the robot's drifting, keeping the robot stable on bumpy terrains, avoiding climbing on hills with steep elevation changes, and collision avoidance. Our training process mitigates the reality(sim-to-real) gap by introducing more generalized environmental and robotic parameters and training with rich features of Lidar perception in the Unity simulator. We evaluate our method in both simulation and the real world with Clearpath Husky and Jackal. Additionally, we compare our method against the state-of-the-art approaches and show that in the real world it improves stability by at least 30.7% on uneven terrains, reduces drifting by 8.08%, and for high hills our trained policy keeps small changes of the elevation of the robot at each motion step by preventing the robot from moving on areas with high gradients.