 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Pre-trained BERT for Audio Captioning
Paper and Code
Mar 27, 2022
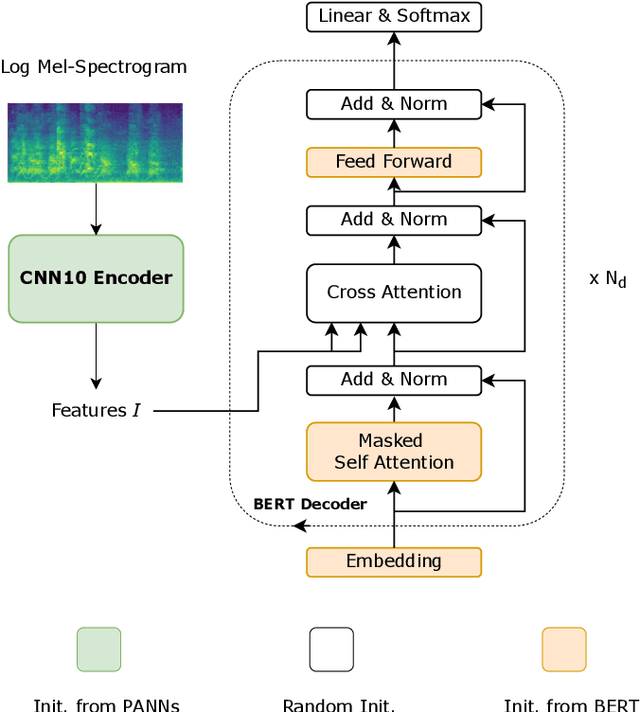
Audio captioning aims at using natural language to describe the content of an audio clip. Existing audio captioning systems are generally based on an encoder-decoder architecture, in which acoustic information is extracted by an audio encoder and then a language decoder is used to generate the captions. Training an audio captioning system often encounters the problem of data scarcity. Transferring knowledge from pre-trained audio models such as Pre-trained Audio Neural Networks (PANNs) have recently emerged as a useful method to mitigate this issue. However, there is less attention on exploiting pre-trained language models for the decoder, compared with the encoder. BERT is a pre-trained language model that has been extensively used in Natural Language Processing (NLP) tasks. Nevertheless, the potential of BERT as the language decoder for audio captioning has not been investigated. In this study, we demonstrate the efficacy of the pre-trained BERT model for audio captioning. Specifically, we apply PANNs as the encoder and initialize the decoder from the public pre-trained BERT models. We conduct an empirical study on the use of these BERT models for the decoder in the audio captioning model. Our models achieve competitive results with the existing audio captioning methods on the AudioCaps dataset.