 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilled Dual-Encoder Model for Vision-Language Understanding
Paper and Code
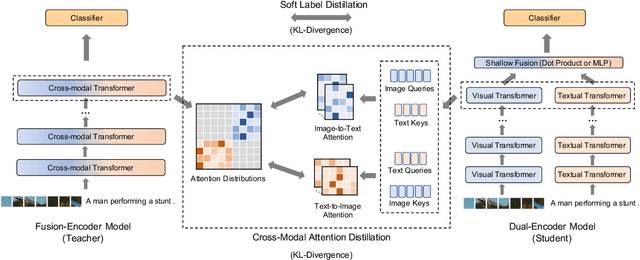
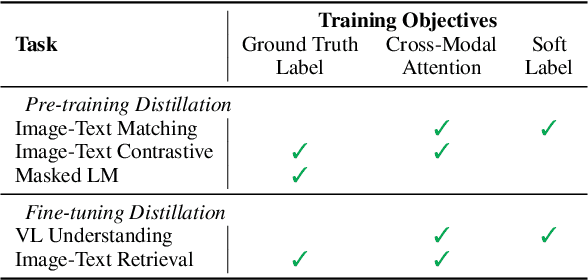

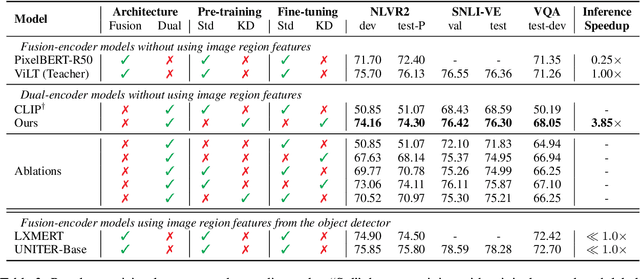
We propose a cross-modal attention distillation framework to train a dual-encoder model for vision-language understanding tasks, such as visual reasoning and visual question answering. Dual-encoder models have a faster inference speed than fusion-encoder models and enable the pre-computation of images and text during inference. However, the shallow interaction module used in dual-encoder models is insufficient to handle complex vision-language understanding tasks. In order to learn deep interactions of images and text, we introduce cross-modal attention distillation, which uses the image-to-text and text-to-image attention distributions of a fusion-encoder model to guide the training of our dual-encoder model. In addition, we show that applying the cross-modal attention distillation for both pre-training and fine-tuning stages achieves further improvements. Experimental results demonstrate that the distilled dual-encoder model achieves competitive performance for visual reasoning, visual entailment and visual question answering tasks while enjoying a much faster inference speed than fusion-encoder models. Our code and models will be publicly available at https://github.com/kugwzk/Distilled-DualEncoder.