 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-policy Reinforcement Learning with Optimistic Exploration and Distribution Correction
Paper and Code
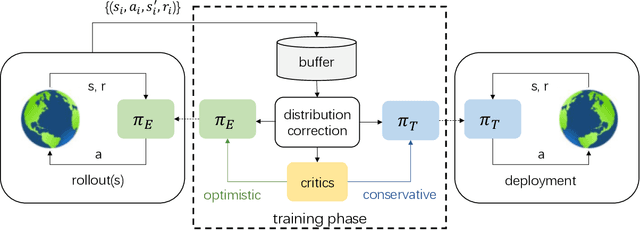
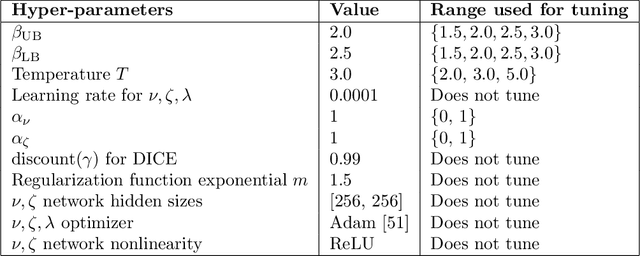

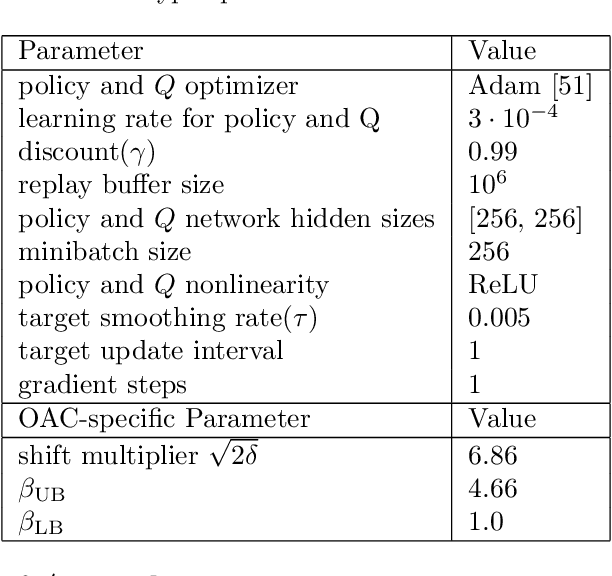
Improving sample efficiency of reinforcement learning algorithms requires effective exploration. Following the principle of $\textit{optimism in the face of uncertainty}$, we train a separate exploration policy to maximize an approximate upper confidence bound of the critics in an off-policy actor-critic framework. However, this introduces extra differences between the replay buffer and the target policy in terms of their stationary state-action distributions. To mitigate the off-policy-ness, we adapt the recently introduced DICE framework to learn a distribution correction ratio for off-policy actor-critic training. In particular, we correct the training distribution for both policies and critics. Empirically, we evaluate our proposed method in several challenging continuous control tasks and show superior performance compared to state-of-the-art methods. We also conduct extensive ablation studies to demonstrate the effectiveness and the rationality of the proposed method.