 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Cross-Modal Prediction and Relation Consistency for Semi-Supervised Image Captioning
Paper and Code
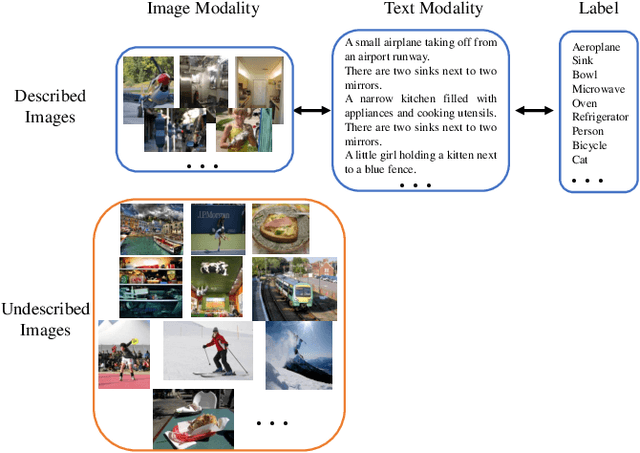
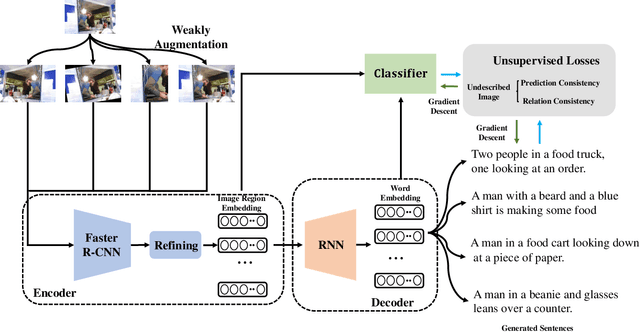
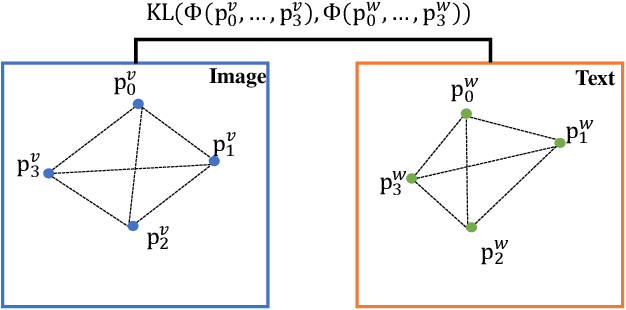
The task of image captioning aims to generate captions directly from images via the automatically learned cross-modal generator. To build a well-performing generator, existing approaches usually need a large number of described images, which requires a huge effects on manual labeling. However, in real-world applications, a more general scenario is that we only have limited amount of described images and a large number of undescribed images. Therefore, a resulting challenge is how to effectively combine the undescribed images into the learning of cross-modal generator. To solve this problem, we propose a novel image captioning method by exploiting the Cross-modal Prediction and Relation Consistency (CPRC), which aims to utilize the raw image input to constrain the generated sentence in the commonly semantic space. In detail, considering that the heterogeneous gap between modalities always leads to the supervision difficulty of using the global embedding directly, CPRC turns to transform both the raw image and corresponding generated sentence into the shared semantic space, and measure the generated sentence from two aspects: 1) Prediction consistency. CPRC utilizes the prediction of raw image as soft label to distill useful supervision for the generated sentence, rather than employing the traditional pseudo labeling; 2) Relation consistency. CPRC develops a novel relation consistency between augmented images and corresponding generated sentences to retain the important relational knowledge. In result, CPRC supervises the generated sentence from both the informativeness and representativeness perspectives, and can reasonably use the undescribed images to learn a more effective generator under the semi-supervised scenario.