 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Bird: Learnable Sparse Attention for Efficient and Effective Transformer
Paper and Code
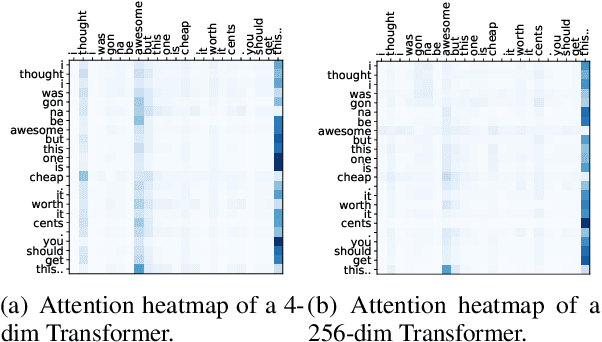
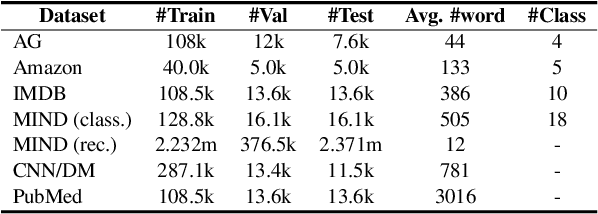
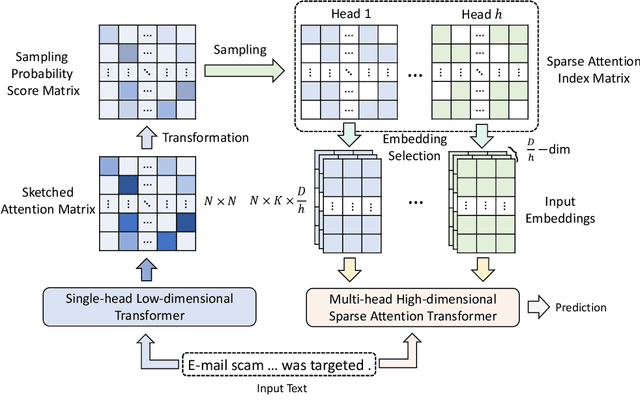

Transformer has achieved great success in NLP. However, the quadratic complexity of the self-attention mechanism in Transformer makes it inefficient in handling long sequences. Many existing works explore to accelerate Transformers by computing sparse self-attention instead of a dense one, which usually attends to tokens at certain positions or randomly selected tokens. However, manually selected or random tokens may be uninformative for context modeling. In this paper, we propose Smart Bird, which is an efficient and effective Transformer with learnable sparse attention. In Smart Bird, we first compute a sketched attention matrix with a single-head low-dimensional Transformer, which aims to find potential important interactions between tokens. We then sample token pairs based on their probability scores derived from the sketched attention matrix to generate different sparse attention index matrices for different attention heads. Finally, we select token embeddings according to the index matrices to form the input of sparse attention networks. Extensive experiments on six benchmark datasets for different tasks validate the efficiency and effectiveness of Smart Bird in text modeling.