 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrior Is All You Need to Improve the Robustness and Safety for the First Time Deployment of Meta RL
Paper and Code
Aug 19, 2021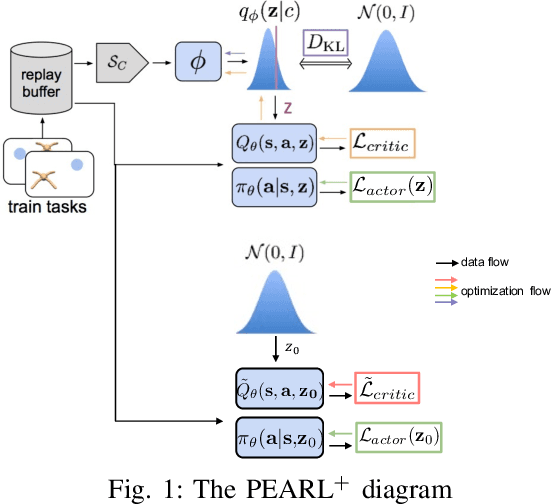

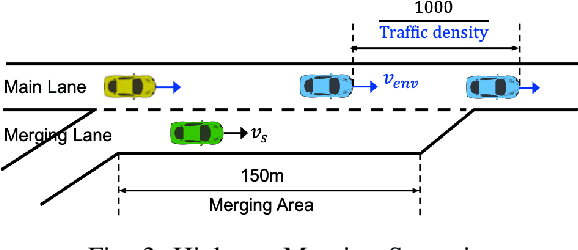
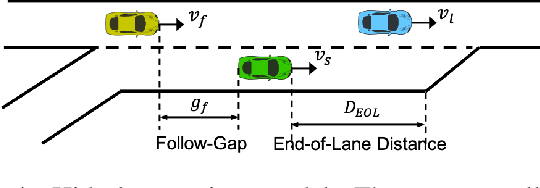
The field of Meta Reinforcement Learning (Meta-RL) has seen substantial advancements recently. In particular, off-policy methods were developed to improve the data efficiency of Meta-RL techniques. \textit{Probabilistic embeddings for actor-critic RL} (PEARL) is currently one of the leading approaches for multi-MDP adaptation problems. A major drawback of many existing Meta-RL methods, including PEARL, is that they do not explicitly consider the safety of the prior policy when it is exposed to a new task for the very first time. This is very important for some real-world applications, including field robots and Autonomous Vehicles (AVs). In this paper, we develop the PEARL PLUS (PEARL$^+$) algorithm, which optimizes the policy for both prior safety and posterior adaptation. Building on top of PEARL, our proposed PEARL$^+$ algorithm introduces a prior regularization term in the reward function and a new Q-network for recovering the state-action value with prior context assumption, to improve the robustness and safety of the trained network exposing to a new task for the first time. The performance of the PEARL$^+$ method is demonstrated by solving three safety-critical decision-making problems related to robots and AVs, including two MuJoCo benchmark problems. From the simulation experiments, we show that the safety of the prior policy is significantly improved compared to that of the original PEARL method.