 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHindsight Value Function for Variance Reduction in Stochastic Dynamic Environment
Paper and Code
Aug 05, 2021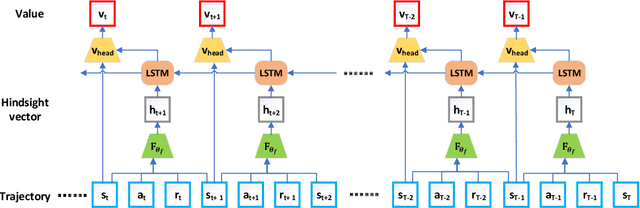
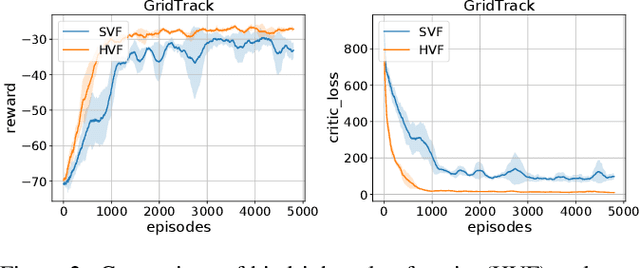
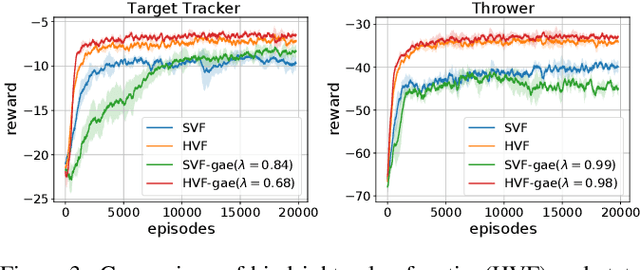
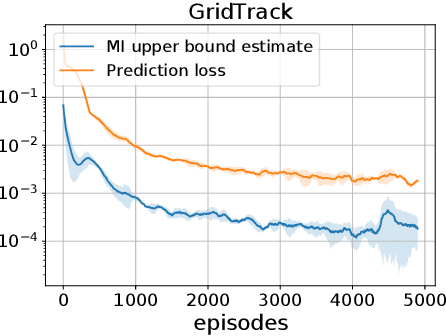
Policy gradient methods are appealing in deep reinforcement learning but suffer from high variance of gradient estimate. To reduce the variance, the state value function is applied commonly. However, the effect of the state value function becomes limited in stochastic dynamic environments, where the unexpected state dynamics and rewards will increase the variance. In this paper, we propose to replace the state value function with a novel hindsight value function, which leverages the information from the future to reduce the variance of the gradient estimate for stochastic dynamic environments. Particularly, to obtain an ideally unbiased gradient estimate, we propose an information-theoretic approach, which optimizes the embeddings of the future to be independent of previous actions. In our experiments, we apply the proposed hindsight value function in stochastic dynamic environments, including discrete-action environments and continuous-action environments. Compared with the standard state value function, the proposed hindsight value function consistently reduces the variance, stabilizes the training, and improves the eventual policy.