 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget-Oriented Fine-tuning for Zero-Resource Named Entity Recognition
Paper and Code
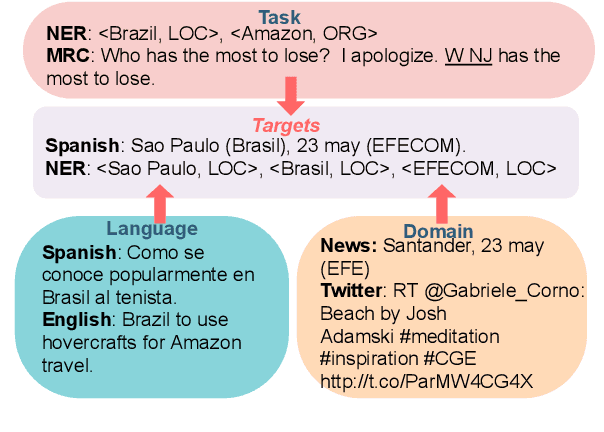
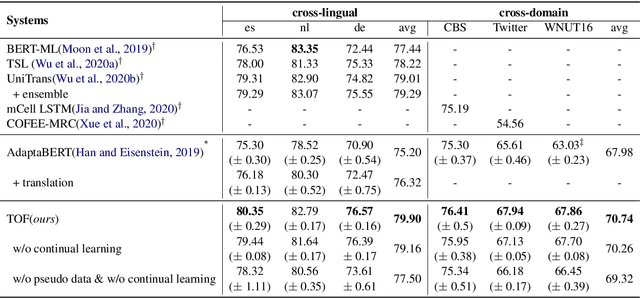
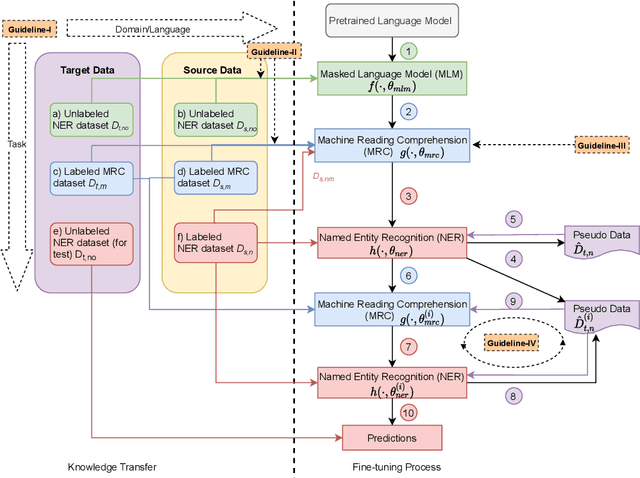
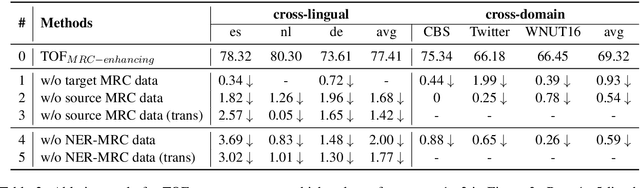
Zero-resource named entity recognition (NER) severely suffers from data scarcity in a specific domain or language. Most studies on zero-resource NER transfer knowledge from various data by fine-tuning on different auxiliary tasks. However, how to properly select training data and fine-tuning tasks is still an open problem. In this paper, we tackle the problem by transferring knowledge from three aspects, i.e., domain, language and task, and strengthening connections among them. Specifically, we propose four practical guidelines to guide knowledge transfer and task fine-tuning. Based on these guidelines, we design a target-oriented fine-tuning (TOF) framework to exploit various data from three aspects in a unified training manner. Experimental results on six benchmarks show that our method yields consistent improvements over baselines in both cross-domain and cross-lingual scenarios. Particularly, we achieve new state-of-the-art performance on five benchmarks.