 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoBERT-Zero: Evolving BERT Backbone from Scratch
Paper and Code
Jul 15, 2021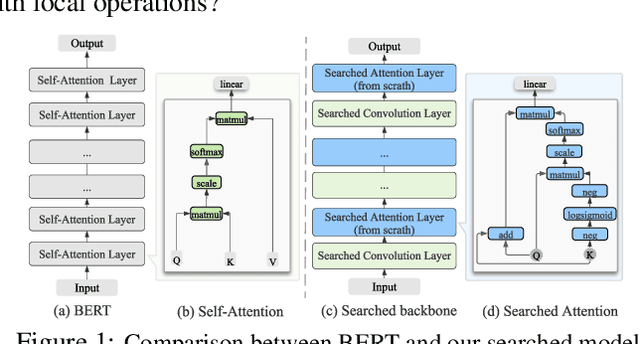

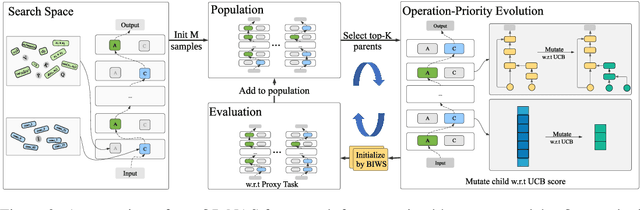
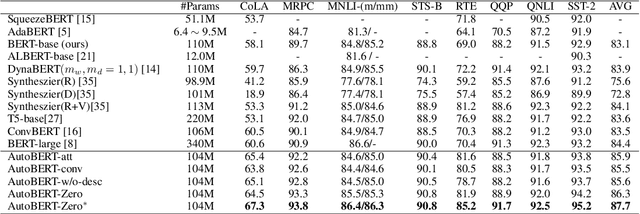
Transformer-based pre-trained language models like BERT and its variants have recently achieved promising performance in various natural language processing (NLP) tasks. However, the conventional paradigm constructs the backbone by purely stacking the manually designed global self-attention layers, introducing inductive bias and thus leading to sub-optimal. In this work, we propose an Operation-Priority Neural Architecture Search (OP-NAS) algorithm to automatically search for promising hybrid backbone architectures. Our well-designed search space (i) contains primitive math operations in the intra-layer level to explore novel attention structures, and (ii) leverages convolution blocks to be the supplementary for attention structure in the inter-layer level to better learn local dependency. We optimize both the search algorithm and evaluation of candidate models to boost the efficiency of our proposed OP-NAS. Specifically, we propose Operation-Priority (OP) evolution strategy to facilitate model search via balancing exploration and exploitation. Furthermore, we design a Bi-branch Weight-Sharing (BIWS) training strategy for fast model evaluation. Extensive experiments show that the searched architecture (named AutoBERT-Zero) significantly outperforms BERT and its variants of different model capacities in various downstream tasks, proving the architecture's transfer and generalization abilities. Remarkably, AutoBERT-Zero-base outperforms RoBERTa-base (using much more data) and BERT-large (with much larger model size) by 2.4 and 1.4 higher score on GLUE test set. Code and pre-trained models will be made publicly available.