 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighbor-Vote: Improving Monocular 3D Object Detection through Neighbor Distance Voting
Paper and Code
Jul 06, 2021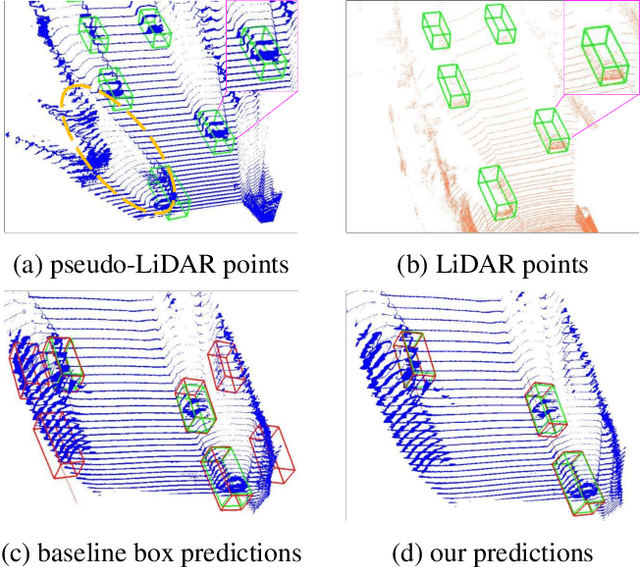
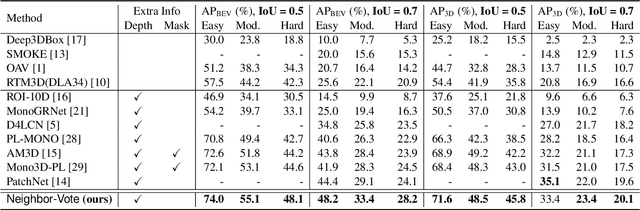
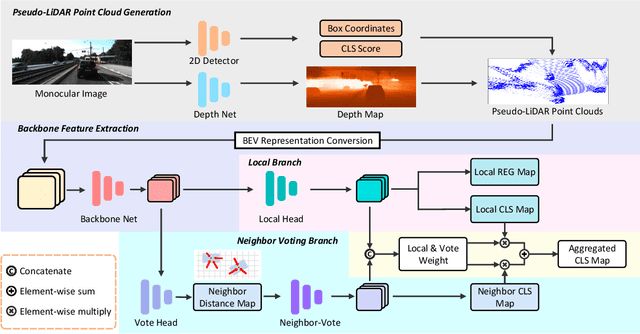
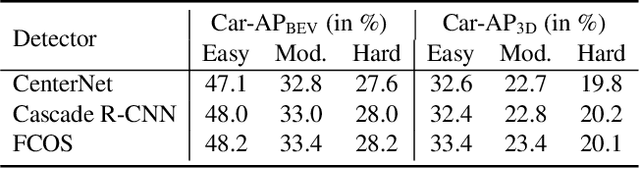
As cameras are increasingly deployed in new application domains such as autonomous driving, performing 3D object detection on monocular images becomes an important task for visual scene understanding. Recent advances on monocular 3D object detection mainly rely on the ``pseudo-LiDAR'' generation, which performs monocular depth estimation and lifts the 2D pixels to pseudo 3D points. However, depth estimation from monocular images, due to its poor accuracy, leads to inevitable position shift of pseudo-LiDAR points within the object. Therefore, the predicted bounding boxes may suffer from inaccurate location and deformed shape. In this paper, we present a novel neighbor-voting method that incorporates neighbor predictions to ameliorate object detection from severely deformed pseudo-LiDAR point clouds. Specifically, each feature point around the object forms their own predictions, and then the ``consensus'' is achieved through voting. In this way, we can effectively combine the neighbors' predictions with local prediction and achieve more accurate 3D detection. To further enlarge the difference between the foreground region of interest (ROI) pseudo-LiDAR points and the background points, we also encode the ROI prediction scores of 2D foreground pixels into the corresponding pseudo-LiDAR points. We conduct extensive experiments on the KITTI benchmark to validate the merits of our proposed method. Our results on the bird's eye view detection outperform the state-of-the-art performance by a large margin, especially for the ``hard'' level detection.