 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditSpeech: A Text Based Speech Editing System Using Partial Inference and Bidirectional Fusion
Paper and Code
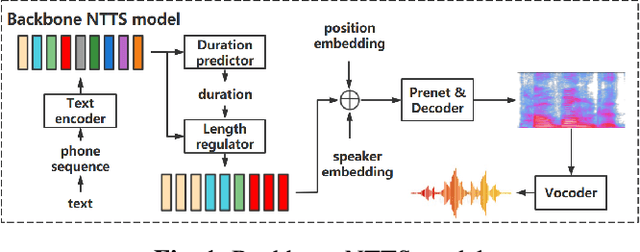
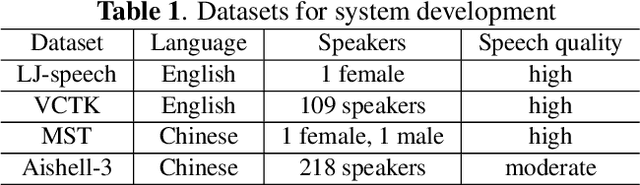
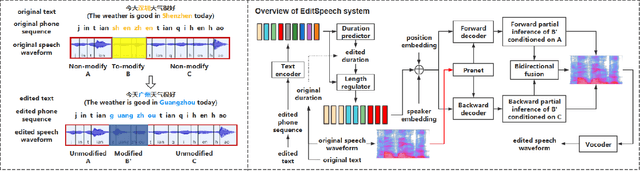
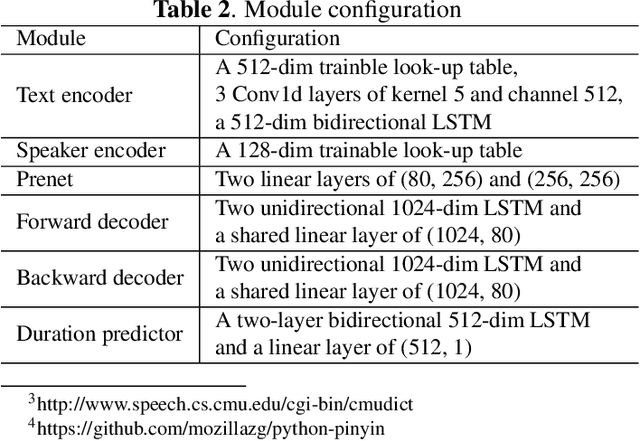
This paper presents the design, implementation and evaluation of a speech editing system, named EditSpeech, which allows a user to perform deletion, insertion and replacement of words in a given speech utterance, without causing audible degradation in speech quality and naturalness. The EditSpeech system is developed upon a neural text-to-speech (NTTS) synthesis framework. Partial inference and bidirectional fusion are proposed to effectively incorporate the contextual information related to the edited region and achieve smooth transition at both left and right boundaries. Distortion introduced to the unmodified parts of the utterance is alleviated. The EditSpeech system is developed and evaluated on English and Chinese in multi-speaker scenarios. Objective and subjective evaluation demonstrate that EditSpeech outperforms a few baseline systems in terms of low spectral distortion and preferred speech quality. Audio samples are available online for demonstration https://daxintan-cuhk.github.io/EditSpeech/ .