 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatchVIE: Exploiting Match Relevancy between Entities for Visual Information Extraction
Paper and Code
Jun 24, 2021
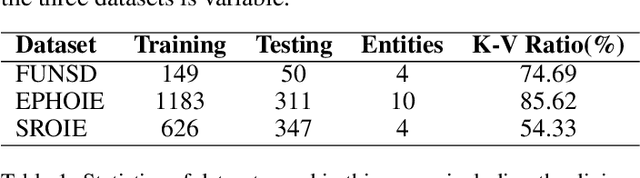
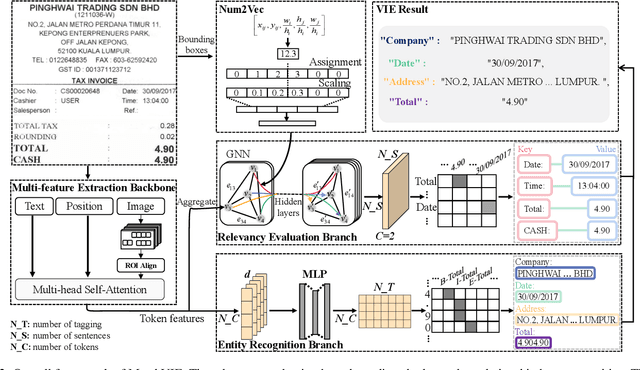
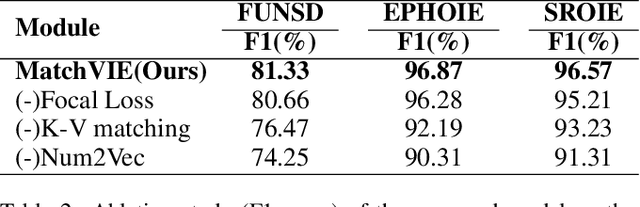
Visual Information Extraction (VIE) task aims to extract key information from multifarious document images (e.g., invoices and purchase receipts). Most previous methods treat the VIE task simply as a sequence labeling problem or classification problem, which requires models to carefully identify each kind of semantics by introducing multimodal features, such as font, color, layout. But simply introducing multimodal features couldn't work well when faced with numeric semantic categories or some ambiguous texts. To address this issue, in this paper we propose a novel key-value matching model based on a graph neural network for VIE (MatchVIE). Through key-value matching based on relevancy evaluation, the proposed MatchVIE can bypass the recognitions to various semantics, and simply focuses on the strong relevancy between entities. Besides, we introduce a simple but effective operation, Num2Vec, to tackle the instability of encoded values, which helps model converge more smoothly. Comprehensive experiments demonstrate that the proposed MatchVIE can significantly outperform previous methods. Notably, to the best of our knowledge, MatchVIE may be the first attempt to tackle the VIE task by modeling the relevancy between keys and values and it is a good complement to the existing methods.