 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEM: A General Evaluation Benchmark for Multimodal Tasks
Paper and Code
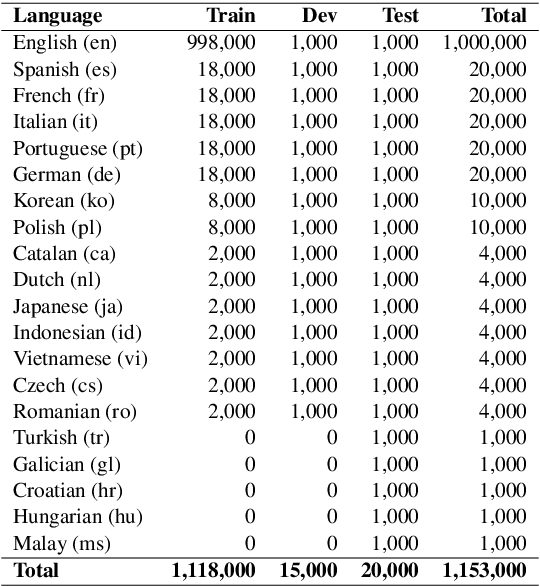

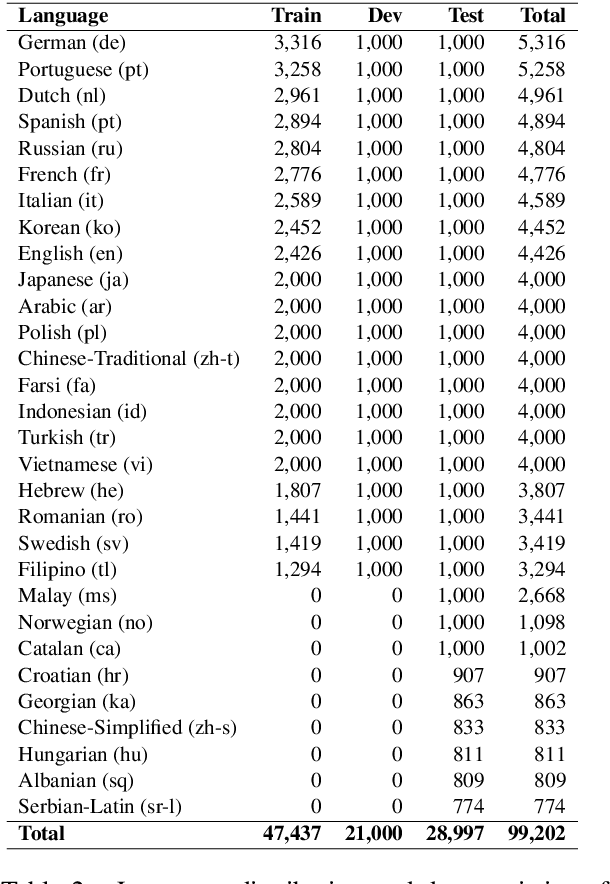

In this paper, we present GEM as a General Evaluation benchmark for Multimodal tasks. Different from existing datasets such as GLUE, SuperGLUE, XGLUE and XTREME that mainly focus on natural language tasks, GEM is a large-scale vision-language benchmark, which consists of GEM-I for image-language tasks and GEM-V for video-language tasks. Comparing with existing multimodal datasets such as MSCOCO and Flicker30K for image-language tasks, YouCook2 and MSR-VTT for video-language tasks, GEM is not only the largest vision-language dataset covering image-language tasks and video-language tasks at the same time, but also labeled in multiple languages. We also provide two baseline models for this benchmark. We will release the dataset, code and baseline models, aiming to advance the development of multilingual multimodal research.